This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
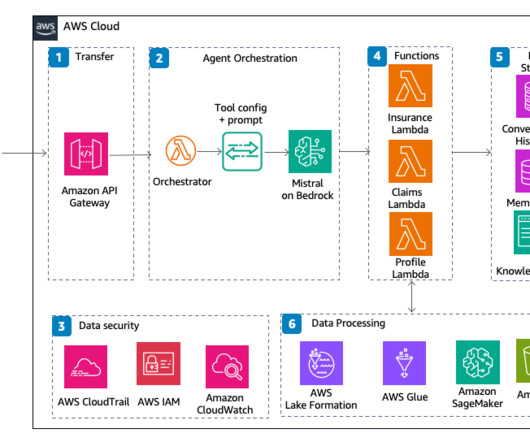
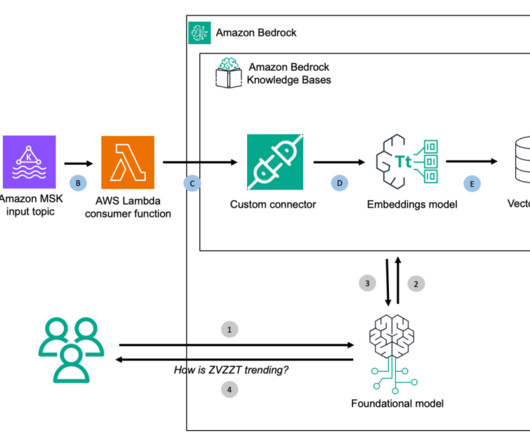
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
AWS Lambda orchestrator, along with tool configuration and prompts, handles orchestration and invokes the Mistral model on Amazon Bedrock. Data is stored in a conversation history, and a member database (MemberDB) is used to store member information and the knowledge base has static documents used by the agent.
This solution extends the capabilities demonstrated in Automate chatbot for document and data retrieval using Amazon Bedrock Agents and Knowledge Bases , which discussed using Amazon Bedrock Agents for document and data retrieval. The solution uses the AWS Cloud Development Kit (AWS CDK) to deploy the solution components.
The AWS Social Responsibility & Impact (SRI) team recognized an opportunity to augment this function using generative AI. Historically, AWS Health Equity Initiative applications were reviewed manually by a review committee. Review the provided proposal document: {PROPOSAL} 2. Here are the steps to follow: 1.
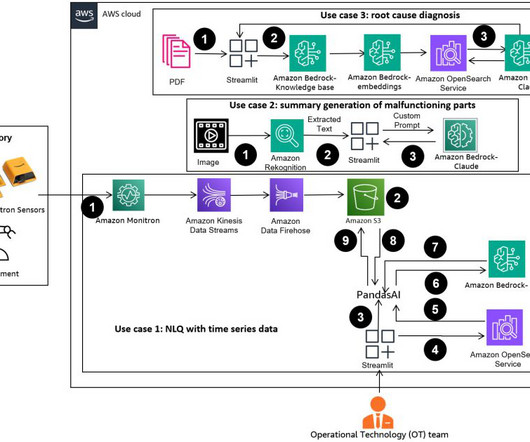
IoT data monitoring Data integration is crucial for processing Internet of Things (IoT) data, enabling predictive maintenance and operational efficiency through real-time insights. Documentation of data architecture Thorough documentation of data systems architecture is crucial for effective integration and long-term maintenance.
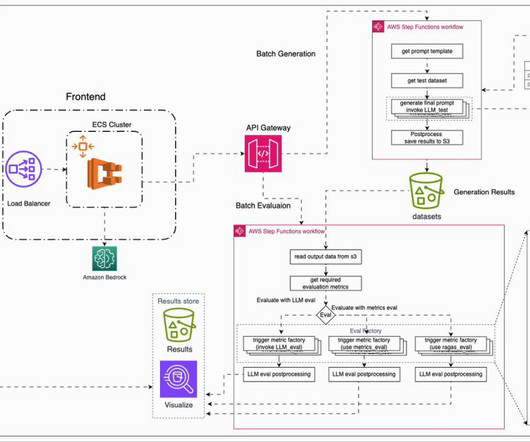
In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. The UI service can be run locally in a Docker container or deployed to AWS Fargate.
Pre-training is highly resource-intensive, requiring substantial compute (often across thousands of GPUs or AWS Trainium chips), large-scale distributed training frameworks, and careful data curation to balance performance with bias, safety, and accuracy concerns. The following table summarizes the different types of PEFT.
Think of the examples of clickstream data, credit card swipes, Internet of Things (IoT) sensor data, log analysis and commodity priceswhere both current data and historical trends are important to make a learned decision. Based on the quality and quantity of the data, the time to complete this process varied.
To define the term, let’s first say that structured data includes spreadsheets with their formalized rows and columns, “form-based” data resources where we know the fields in a document and so we know what values to expect… and of course relational databases, the purest form of an ordered and structured data repository.
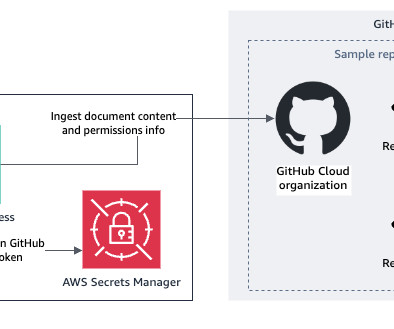
Overview of solution To create an Amazon Q Business application to connect to your GitHub repositories using AWS IAM Identity Center and AWS Secrets Manager , follow these high-level steps: Create an Amazon Q Business application Perform sync Run sample queries to test the solution The following screenshot shows the solution architecture.
It is an enterprise cloud-based asset management platform that leverages artificial intelligence (AI) , the Internet of Things (IoT) and analytics to help optimize equipment performance, extend asset lifecycles and reduce operational downtime and costs. Why ROSA for Maximo in AWS?
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. IoT analytics: IoT (Internet of Things) analytics deals with data generated by IoT devices, such as sensors, connected appliances, and industrial equipment.
In this post, multi-shot prompts are retrieved from an embedding containing successful Python code run on a similar data type (for example, high-resolution time series data from Internet of Things devices). For details, refer to Step 1: Create your AWS account. You can name this AWS CloudFormation stack as: genai-sagemaker.
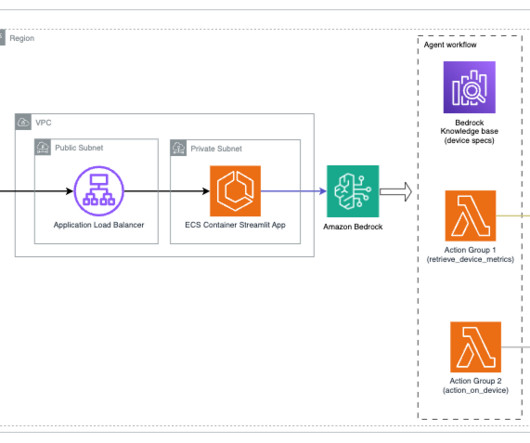
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. It is hosted on Amazon Elastic Container Service (Amazon ECS) with AWS Fargate , and it is accessed using an Application Load Balancer. Anthropic Claude v2.1
PII redaction is the process of masking or removing sensitive information from a document so it can be used and distributed, while still protecting confidential information. Prerequisites For this walkthrough, you should have the following: An AWS account. Neelam Koshiya is an Enterprise Solutions Architect at AWS.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. The challenge CCC processes more than $1 trillion claims transactions annually.
Internet companies like Amazon led the charge with the introduction of Amazon Web Services (AWS) in 2002, which offered businesses cloud-based storage and computing services, and the launch of Elastic Compute Cloud (EC2) in 2006, which allowed users to rent virtual computers to run their own applications. Google Workspace, Salesforce).
Models with larger context windows can understand and generate longer sequences of text, which can be useful for tasks involving longer conversations or documents. Some models may be trained on diverse text datasets like internet data, coding scripts, instructions, or human feedback. words for English).
Metadata Management can be performed manually by creating spreadsheets and documents notating information about the various datasets. Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process.
The data ingestion workflow creates semantic embeddings for documents and questions, storing document embeddings in a vector database. By comparing vector similarity to the question embedding, the text generation workflow selects the most relevant document chunks to enhance the prompt. Anthropic’s Claude Sonnet 3.5
Solution overview The chess demo uses a broad spectrum of AWS services to create an interactive and engaging gaming experience. On the frontend, AWS Amplify hosts a responsive React TypeScript application while providing secure user authentication through Amazon Cognito using the Amplify SDK. The demo offers a few gameplay options.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content