This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
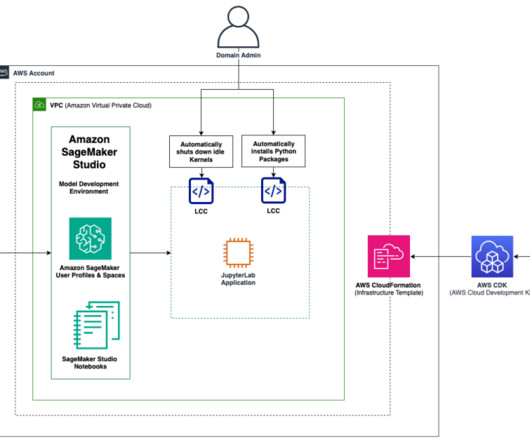
Amazon SageMaker Studio is the first integrated development environment (IDE) purposefully designed to accelerate end-to-end machine learning (ML) development. These automations can greatly decrease overhead related to ML project setup, facilitate technical consistency, and save costs related to running idle instances.
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Aamna Najmi is a GenAI and Data Specialist at AWS.
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
This post describes a pattern that AWS and Cisco teams have developed and deployed that is viable at scale and addresses a broad set of challenging enterprise use cases. Augmenting data with data definitions for prompt construction Several of the optimizations noted earlier require making some of the specifics of the data domain explicit.
It also comes with ready-to-deploy code samples to help you get started quickly with deploying GeoFMs in your own applications on AWS. Custom geospatial machine learning : Fine-tune a specialized regression, classification, or segmentation model for geospatial machine learning (ML) tasks. Lets dive in!
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. and above. Any version above 2.231.0
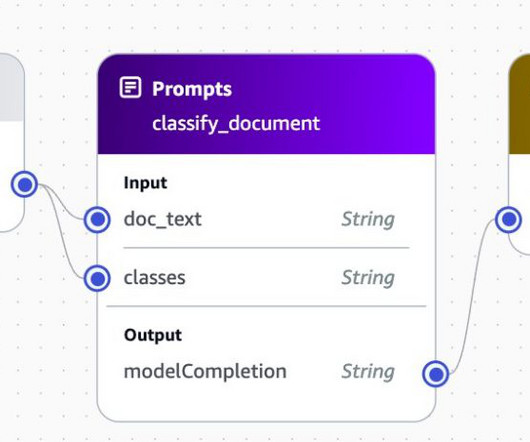
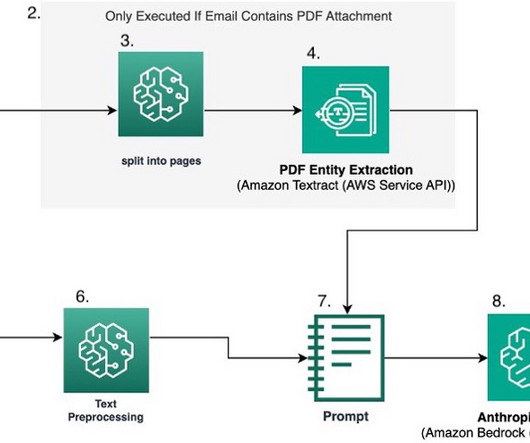
Extraction – A document schema definition is used to formulate the prompt and documents are embedded into the prompt and sent to Amazon Bedrock for extraction. To find the URL, open the AWS Management Console for SageMaker and choose Ground Truth and then Labeling workforces in the navigation pane. edit cdk.json Deploy the application.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. This approach lets the model learn how to interpret tool definitions and make appropriate function calls based on user queries.
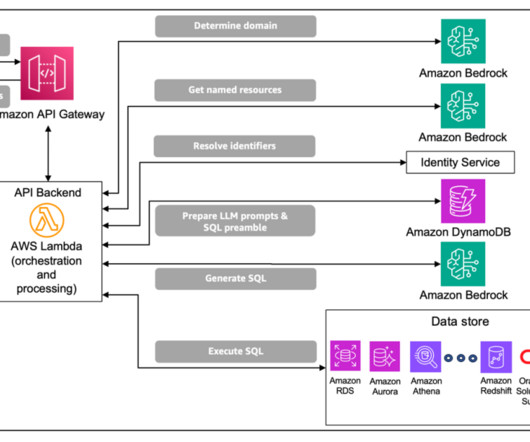
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. This entire workflow is shown in the following solution diagram.
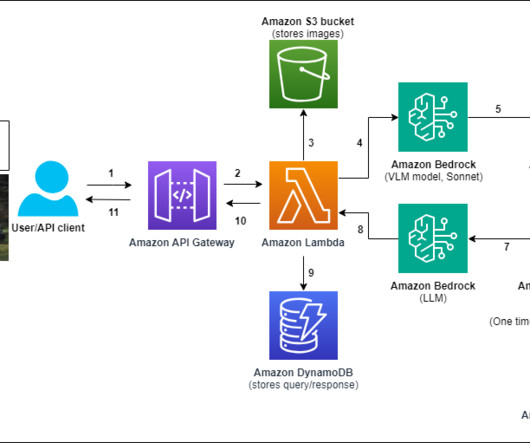
In this post, we show how to create a multimodal chat assistant on Amazon Web Services (AWS) using Amazon Bedrock models, where users can submit images and questions, and text responses will be sourced from a closed set of proprietary documents. For this post, we recommend activating these models in the us-east-1 or us-west-2 AWS Region.
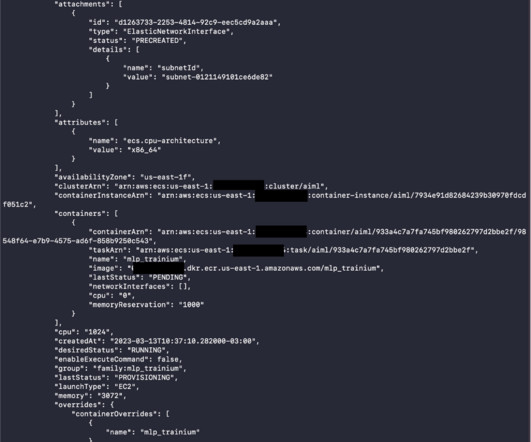
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an ML development environment that is consistent and portable. In this post, we show you how to run your ML training jobs in a container using Amazon ECS to deploy, manage, and scale your ML workload.
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. Our innovative new A-POPs (or vending machines) deliver enhanced customer experiences at ten times lower cost because of the performance and cost advantages AWS Inferentia delivers.
No definite pneumonia. This indicates that the key findings from the radiology report are the presence of a moderate hiatal hernia and the absence of any definite pneumonia. Data ScientistGenerative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS.
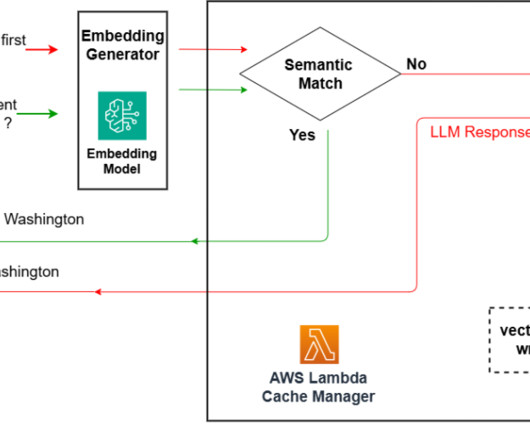
However, in a practical cache system, it’s crucial to refine the definition of similarity. In this post, we demonstrate how to use various AWS technologies to establish a serverless semantic cache system. The solution presented in this post can be deployed through an AWS CloudFormation template.
However, the rise of intelligent document processing (IDP), which uses the power of artificial intelligence and machine learning (AI/ML) to automate the extraction, classification, and analysis of data from various document types is transforming the game. The Amazon S3 upload triggers an AWS Lambda function execution.
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. The data scientist is responsible for moving the code into SageMaker, either manually or by cloning it from a code repository such as AWS CodeCommit.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
What Zeta has accomplished in AI/ML In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
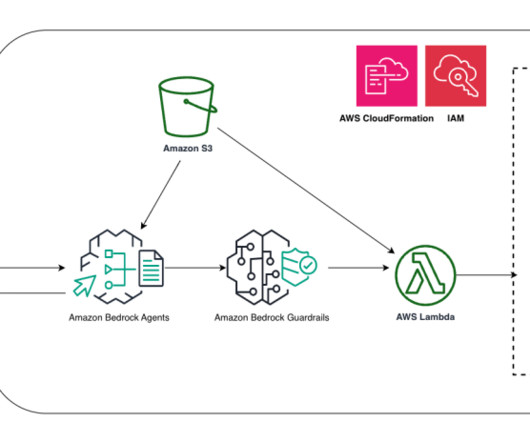
These agents work with AWS managed infrastructure capabilities and Amazon Bedrock , reducing infrastructure management overhead. Prerequisites To run this demo in your AWS account, complete the following prerequisites: Create an AWS account if you don’t already have one. For more details, see Amazon S3 pricing.
Increasingly, FMs are completing tasks that were previously solved by supervised learning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. With a serverless solution, AWS provides a managed solution, facilitating lower cost of ownership and reduced complexity of maintenance.
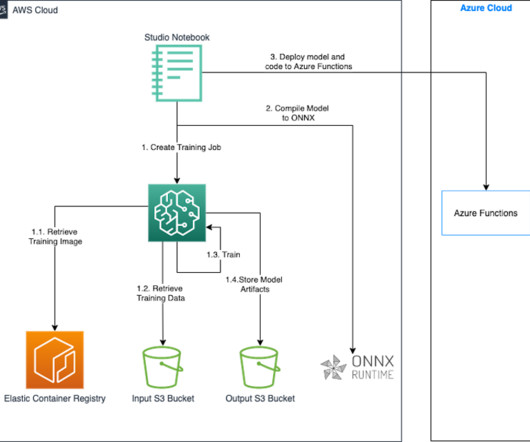
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
At AWS, we are committed to developing AI responsibly , taking a people-centric approach that prioritizes education, science, and our customers, integrating responsible AI across the end-to-end AI lifecycle. For human-in-the-loop evaluation, which can be done by either AWS managed or customer managed teams, you must bring your own dataset.
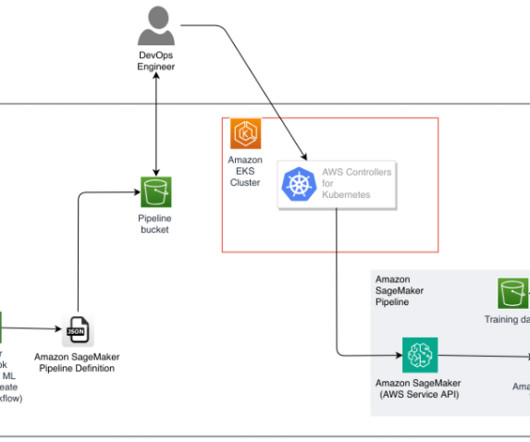
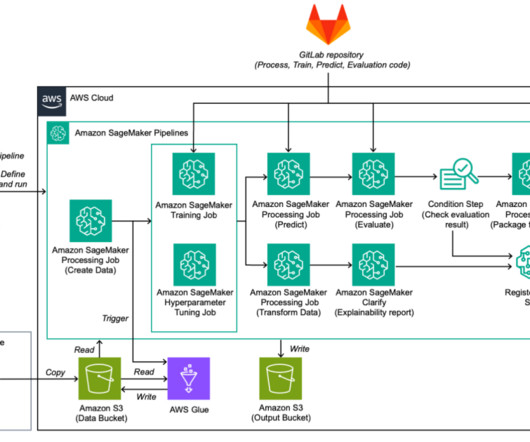
This post showcases how the TSBC built a machine learning operations (MLOps) solution using Amazon Web Services (AWS) to streamline production model training and management to process public safety inquiries more efficiently. It streamlines ML lifecycle management and stores model and pipeline artifacts.
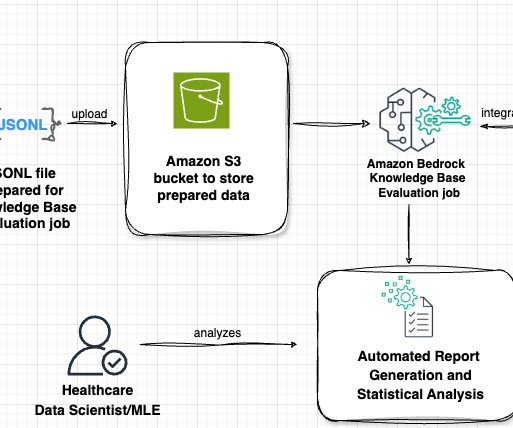
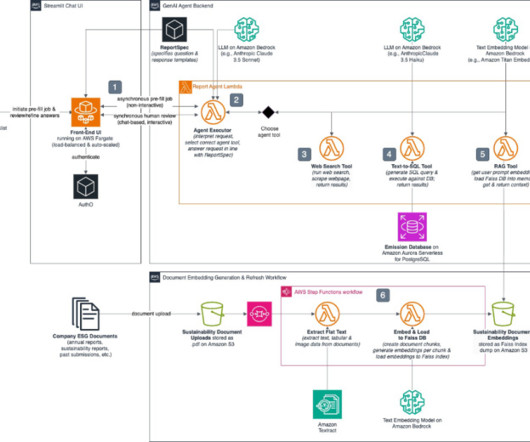
Gardenia Technologies, a data analytics company, partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop Report GenAI , a fully automated ESG reporting solution powered by the latest generative AI models on Amazon Bedrock. This ReportSpec definition is inserted into the task prompt. on Amazon Bedrock.
It usually comprises parsing log data into vectors or machine-understandable tokens, which you can then use to train custom machine learning (ML) algorithms for determining anomalies. You can adjust the inputs or hyperparameters for an ML algorithm to obtain a combination that yields the best-performing model. scikit-learn==0.21.3
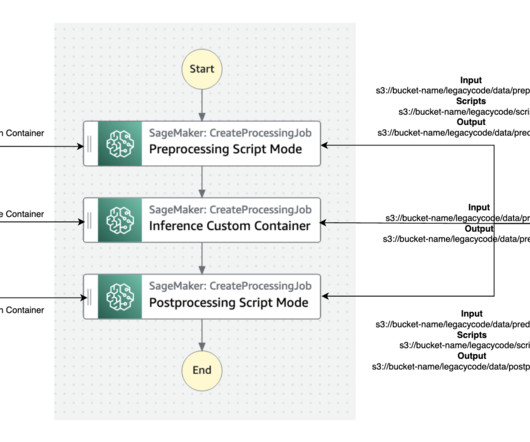
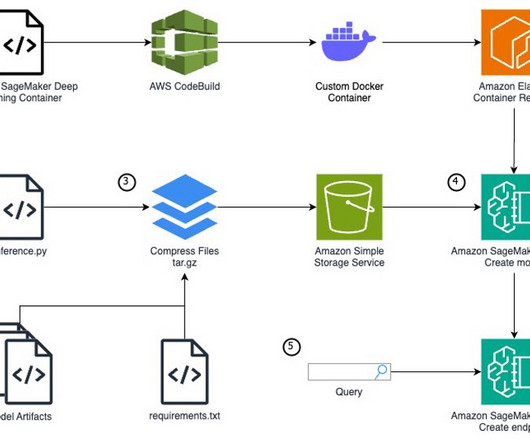
Amazon SageMake r provides a seamless experience for building, training, and deploying machine learning (ML) models at scale. In such cases, SageMaker allows you to extend its functionality by creating custom container images and defining custom model definitions. Write a Python model definition using the SageMaker inference.py
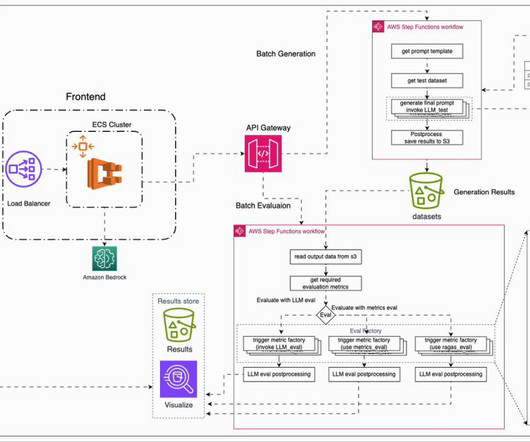
In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. The UI service can be run locally in a Docker container or deployed to AWS Fargate.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
By caching the system prompts and complex tool definitions, the time to process each step in the agentic flow can be reduced. Amazon Web Services (AWS) offers AWS Network Firewall, a stateful, managed network firewall that includes intrusion detection and prevention (IDP) for your Amazon Virtual Private Cloud (VPC)."nn[2]
AWS DeepRacer League 2024 Championship finalists at re:Invent 2024 The AWS DeepRacer League is the worlds first global autonomous racing league powered by machine learning (ML). Look for the Solution to kickstart your companys ML transformation starting in Q2 of 2025.
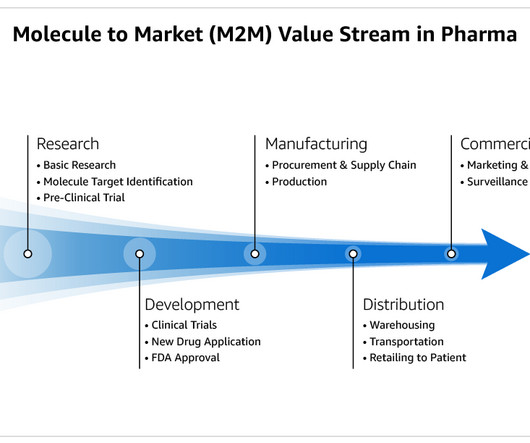
Nine out of ten biopharma companies are AWS customers, and helping them streamline and transform the M2M processes can help deliver drugs to patients faster, reduce risk, and bring value to our customers. Finally, we present instructions to deploy the service in your own AWS account.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
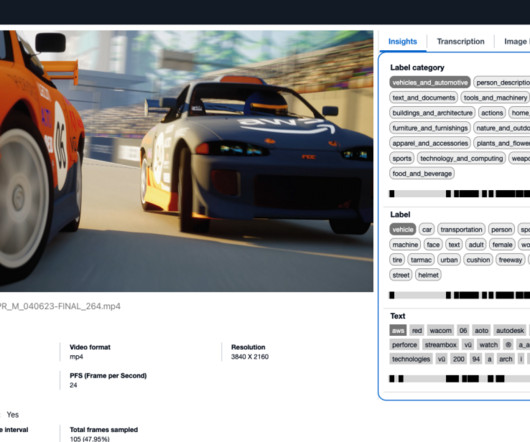
In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes. This solution, powered by AWS AI and generative AI services, meets these needs.
In this article we will speak about Serverless Machine learning in AWS, so sit back, relax, and enjoy! Introduction to Serverless Machine Learning in AWS Serverless computing reshapes machine learning (ML) workflow deployment through its combination of scalability and low operational cost, and reduced total maintenance expenses.
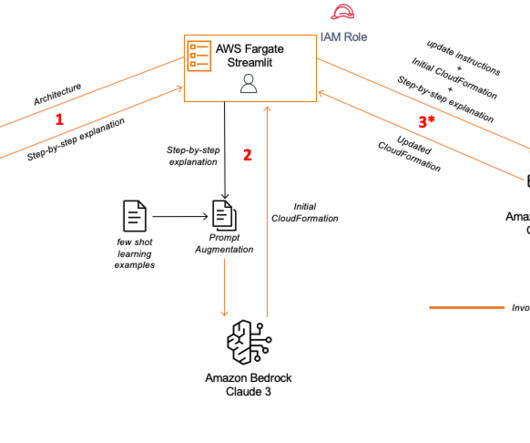
Architecting specific AWS Cloud solutions involves creating diagrams that show relationships and interactions between different services. Instead of building the code manually, you can use Anthropic’s Claude 3’s image analysis capabilities to generate AWS CloudFormation templates by passing an architecture diagram as input.
These agents work with AWS managed infrastructure capabilities and Amazon Bedrock , reducing infrastructure management overhead. The agent can recommend software and architecture design best practices using the AWS Well-Architected Framework for the overall system design. What are the top five most expensive products?
Overview Custom metrics in Amazon Bedrock Evaluations offer the following features: Simplified getting started experience Pre-built starter templates are available on the AWS Management Console based on our industry-tested built-in metrics, with options to create from scratch for specific evaluation criteria.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services.
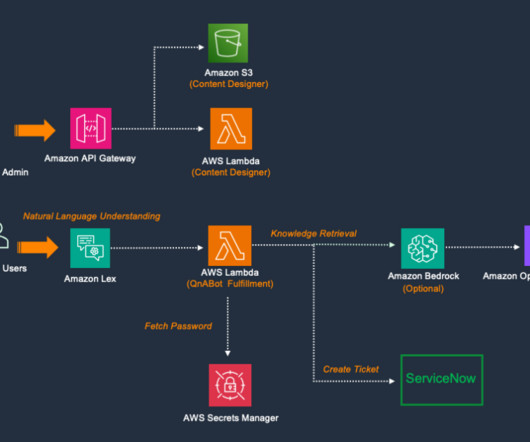
QnABot on AWS is an open source solution built using AWS native services like Amazon Lex , Amazon OpenSearch Service , AWS Lambda , Amazon Transcribe , and Amazon Polly. In this post, we demonstrate how to integrate the QnABot on AWS chatbot solution with ServiceNow. QnABot version 5.4+ Provide a name for the bot.
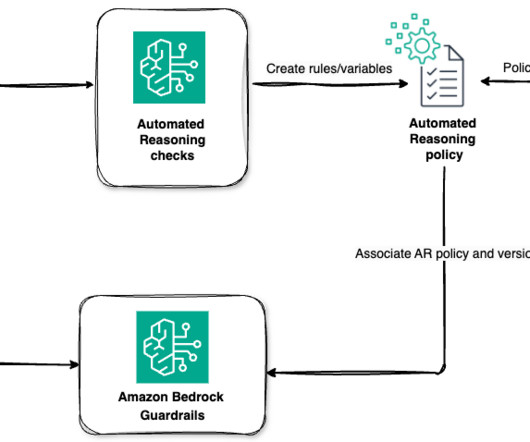
To improve factual accuracy of large language model (LLM) responses, AWS announced Amazon Bedrock Automated Reasoning checks (in gated preview) at AWS re:Invent 2024. For example, AWS customers have direct access to automated reasoning-based features such as IAM Access Analyzer , S3 Block Public Access , or VPC Reachability Analyzer.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content