This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. You can download the dataset loans-part-1.csv
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Amazon SageMaker Canvas is a low-code no-code visual interface to build and deploy ML models without the need to write code.
This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects. You can use SageMaker Canvas to build the initial datapreparation routine and generate accurate predictions without writing code.
Amazon S3 enables you to store and retrieve any amount of data at any time or place. It offers industry-leading scalability, data availability, security, and performance. SageMaker Canvas now supports comprehensive datapreparation capabilities powered by SageMaker Data Wrangler.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe. You will see a product ARN displayed.
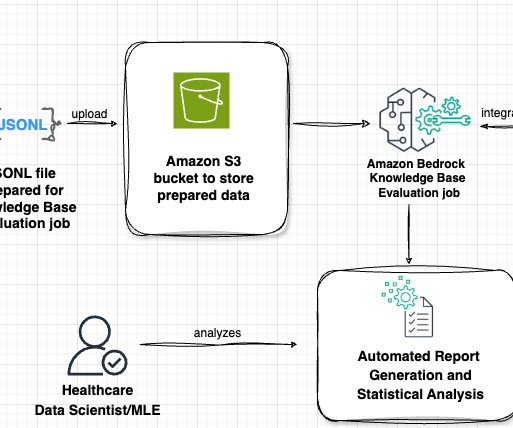
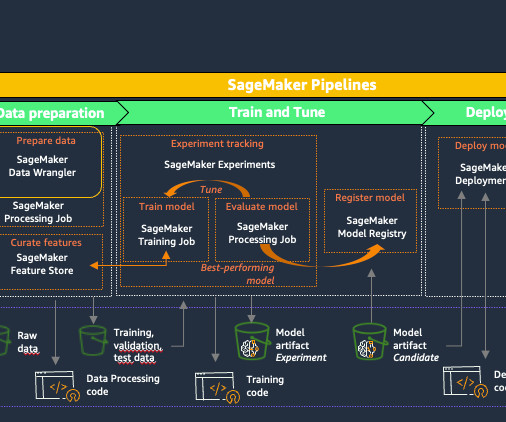
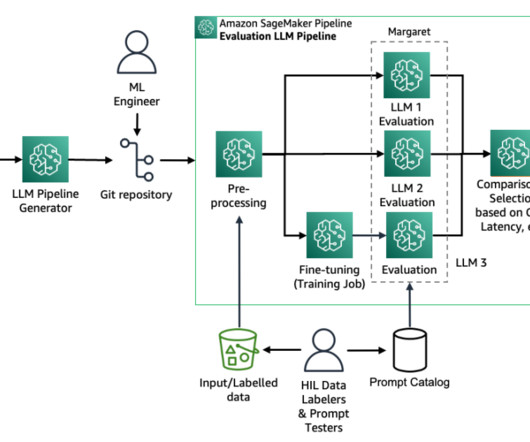
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
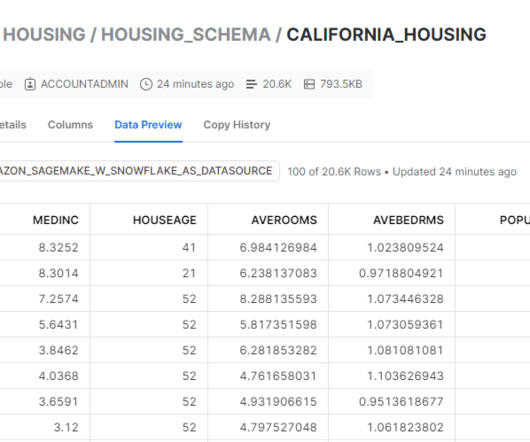
In such situations, it may be desirable to have the data accessible to SageMaker in the ephemeral storage media attached to the ephemeral training instances without the intermediate storage of data in Amazon S3. We add this data to Snowflake as a new table. Store your Snowflake account credentials in AWS Secrets Manager.
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets.
In the following sections, we demonstrate how to import and prepare the data, optionally export the data, create a model, and run inference, all in SageMaker Canvas. Download the dataset from Kaggle and upload it to an Amazon Simple Storage Service (Amazon S3) bucket.
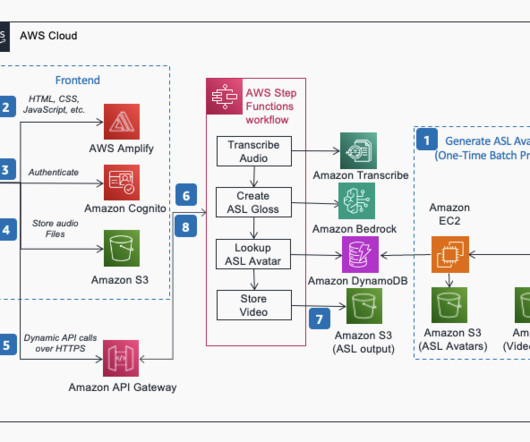
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
By using the AWS Experience-Based Acceleration (EBA) program, they can enhance efficiency, scalability, and maintainability through close collaboration. To address these challenges and streamline modernization efforts, AWS offers the EBA program.
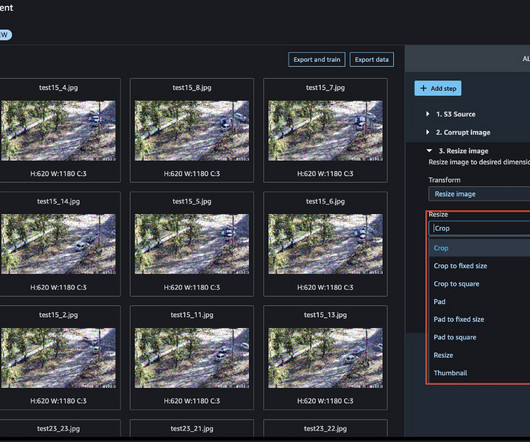
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import.
SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
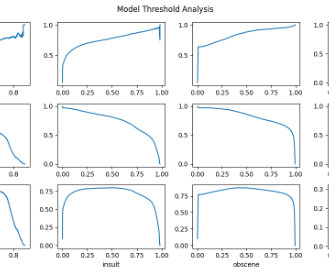
We go through several steps, including datapreparation, model creation, model performance metric analysis, and optimizing inference based on our analysis. We use an Amazon SageMaker notebook and the AWS Management Console to complete some of these steps. We will be using the Data-Preparation notebook.
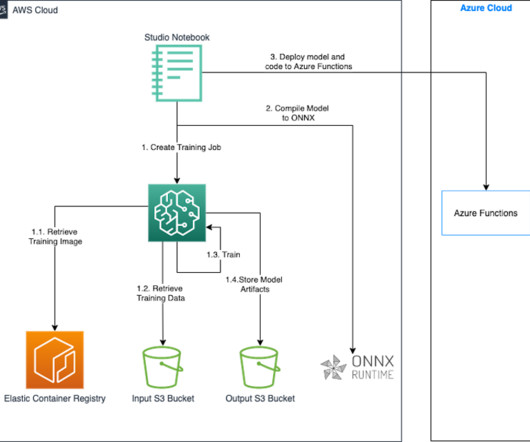
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
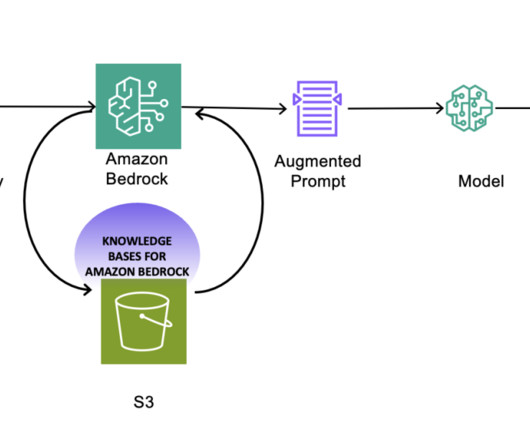
To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import , a feature that you can use to import customized models created in other environments—such as Amazon SageMaker , Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock.
SageMaker Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Amazon SageMaker Canvas is a powerful no-code ML tool designed for business and data teams to generate accurate predictions without writing code or having extensive ML experience.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
Additionally, using Amazon Comprehend with AWS PrivateLink means that customer data never leaves the AWS network and is continuously secured with the same data access and privacy controls as the rest of your applications. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines.
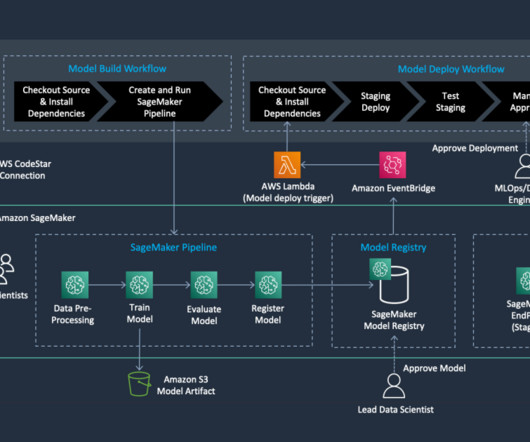
The built-in project templates provided by Amazon SageMaker include integration with some of third-party tools, such as Jenkins for orchestration and GitHub for source control, and several utilize AWS native CI/CD tools such as AWS CodeCommit , AWS CodePipeline , and AWS CodeBuild. all implemented via CloudFormation.
It does so by covering the ML workflow end-to-end: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, and ready-to-use models powered by AWS AI services and Generative AI, SageMaker Canvas can help you to achieve your goals.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics.
SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
This is where MLflow can help streamline the ML lifecycle, from datapreparation to model deployment. SageMaker access with required IAM permissions – You need to have access to SageMaker with the necessary AWS Identity and Access Management (IAM) permissions to create and manage resources.
Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. These models are released under different licenses designated by their respective sources.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. Prerequisites Before diving into this use case, complete the following prerequisites: Set up an AWS account.
This allows you to create unique views and filters, and grants management teams access to a streamlined, one-click dashboard without needing to log in to the AWS Management Console and search for the appropriate dashboard. On the AWS CloudFormation console, create a new stack. Clone the GitHub repo to create the container image: app.py
Additional model training benefits can include lower training costs with Managed Spot Training, distributed training libraries to split models and training datasets across AWS GPU instances, and more. Prepare the dataset for fine-tuning We use the low-resource language Marathi for the fine-tuning task.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. Data preprocessing holds a pivotal role in a data-centric AI approach. However, preparing raw data for ML training and evaluation is often a tedious and demanding task in terms of compute resources, time, and human effort.
In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload. Datapreparation LLM developers train their models on large datasets of naturally occurring text.
We will also illustrate how flywheel can be used to orchestrate the training of a new model version and improve the accuracy of the model using new labeled data. Optional) Configure permissions for AWS KMS keys for AWS KMS keys for the datalake. Create a data access role that authorizes Amazon Comprehend to access the datalake.
With AWS ML, organizations can accelerate the value creation from months to days. Complete the following steps to use Autopilot AutoML to build, train, deploy, and share an ML model with a business analyst: Download the dataset , upload it to an Amazon S3 ( Amazon Simple Storage Service ) bucket, and make a note of the S3 URI.
Launched in August 2019, Forecast predates Amazon SageMaker Canvas , a popular low-code no-code AWS tool for building, customizing, and deploying ML models, including time series forecasting models. For more information about AWS Region availability, see AWS Services by Region.
Each step of the workflow is developed in a different notebook, which are then converted into independent notebook jobs steps and connected as a pipeline: Preprocessing – Download the public SST2 dataset from Amazon Simple Storage Service (Amazon S3) and create a CSV file for the notebook in Step 2 to run. train sst2.train train sst2.train
The NFL, BioCore, and AWS are committed to advancing human understanding around the diagnosis, prevention, and treatment of sports-related injuries to make the game of football safer. You can download the endzone and sideline videos , and also the ground truth labels. To use SageMaker Studio Lab, request and set up a new account.
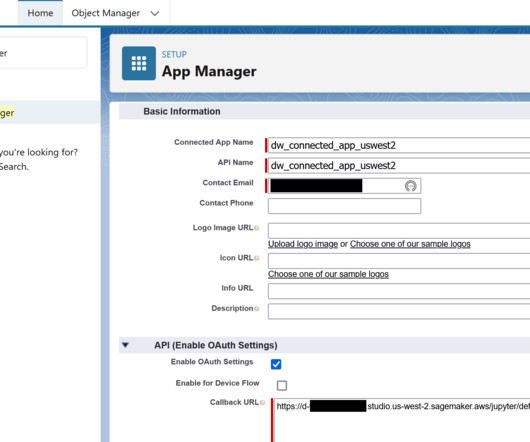
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. Select Other type of secret. Save the secret and note the ARN of the secret.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















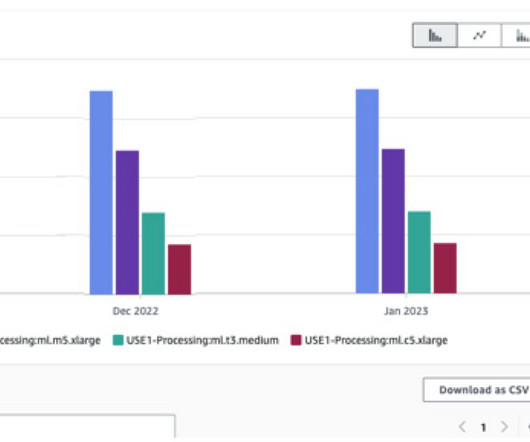
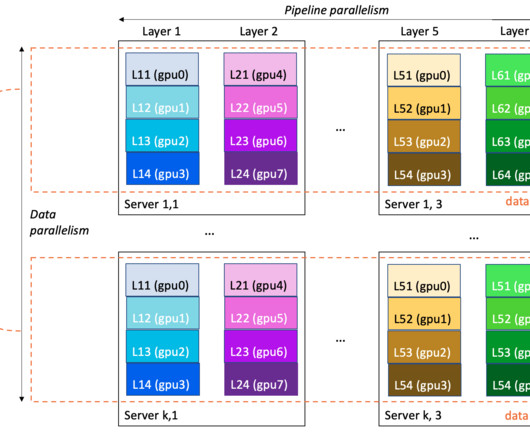
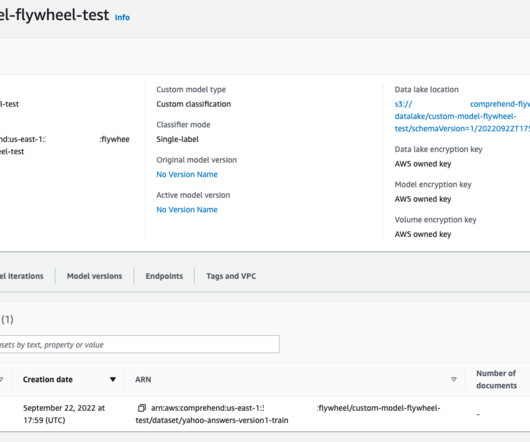
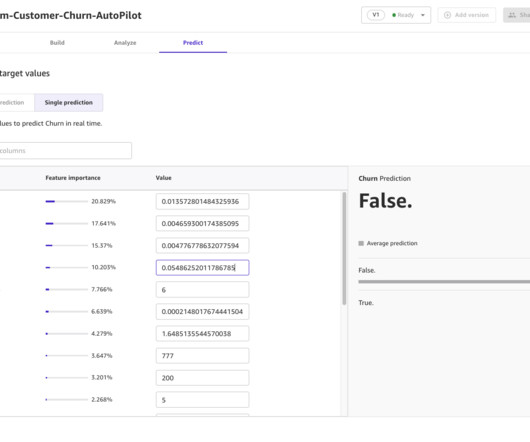








Let's personalize your content