This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
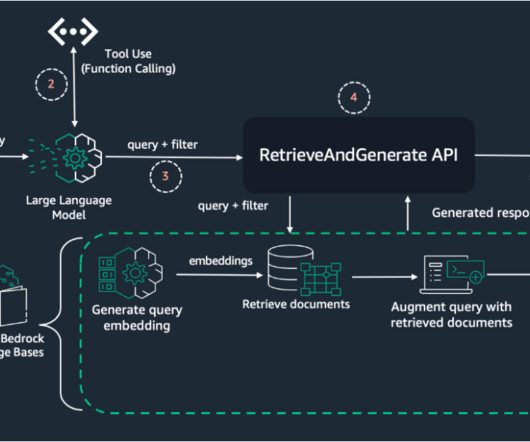
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock.
Because SageMaker Model Cards and SageMaker Model Registry were built on separate APIs, it was challenging to associate the model information and gain a comprehensive view of the model development lifecycle. Integrating model information and then sharing it across different stages became increasingly difficult.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
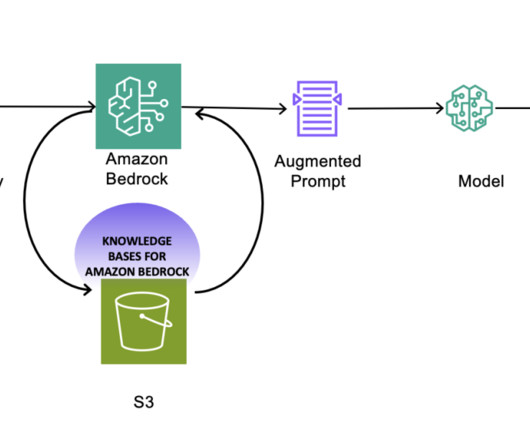
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure.
Launched in August 2019, Forecast predates Amazon SageMaker Canvas , a popular low-code no-code AWS tool for building, customizing, and deploying ML models, including time series forecasting models. For more information about AWS Region availability, see AWS Services by Region.
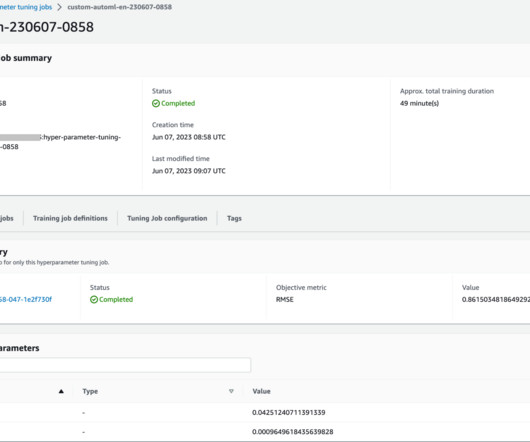
Prerequisites The following are prerequisites for completing the walkthrough in this post: An AWS account Familiarity with SageMaker concepts, such as an Estimator, training job, and HPO job Familiarity with the Amazon SageMaker Python SDK Python programming knowledge Implement the solution The full code is available in the GitHub repo.
Advanced tools like AWS QuickSight support large datasets and growing businesses. Microsoft Power BI is a comprehensive business intelligence (BI) tool designed to help organisations turn raw data into meaningful insights. Scalable : QuickSight can scale easily with the growing data needs of your business. What is Power BI?
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Model Evaluation and Tuning After building a Machine Learning model, it is crucial to evaluate its performance to ensure it generalises well to new, unseen data. Model evaluation and tuning involve several techniques to assess and optimise model accuracy and reliability.
As a fully managed service, Snowflake eliminates the need for infrastructure maintenance, differentiating itself from traditional data warehouses by being built from the ground up. It can be hosted on major cloud platforms like AWS, Azure, and GCP. These models are designed to run instantly after syncing data with the Source.
Predictive Analytics : Models that forecast future events based on historical data. Model Repository and Access Users can browse a comprehensive library of pre-trained models tailored to specific business needs, making it easy to find the right solution for various applications.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
It requires significant effort in terms of datapreparation, exploration, processing, and experimentation, which involves trying out algorithms and hyperparameters. It is so because these algorithms have proven great results on a benchmark dataset, whereas your business problem and hence your data is different.
You need to make that model available to the end users, monitor it, and retrain it for better performance if needed. Microsoft Azure ML Provided by Microsoft , Azure Machine Learning (ML) is a cloud-based machine learning platform that enables data scientists and developers to build, train, and deploy machine learning models at scale.
3 Quickly build and deploy an end-to-end ML pipeline with Kubeflow Pipelines on AWS. They include: 1 Data (or input) pipeline. 2 Model (or training) pipeline. Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used.
The following figure shows the framework to evaluate LLMs and LLM-based services: Amazon SageMaker Clarify LLM evaluation is an open-source Foundation Model Evaluation (FMEval) library developed by AWS to help customers easily evaluate LLMs. Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in Netherlands.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content