This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
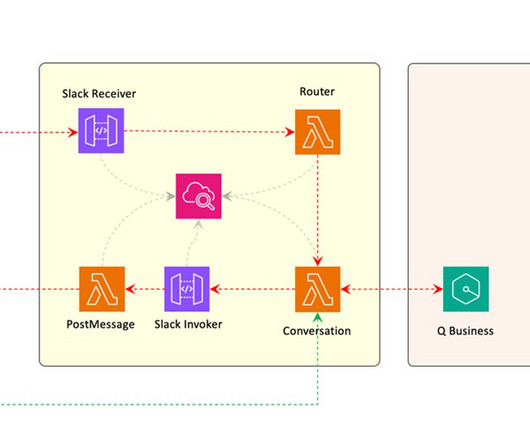
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Separation of storage and compute : Lakebases store their data in modern datalakes (object stores) in open formats, which enables scaling compute and storage separately, leading to lower TCO and eliminating lock-in. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes.
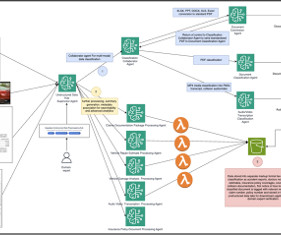
Enterprisesespecially in the insurance industryface increasing challenges in processing vast amounts of unstructured data from diverse formats, including PDFs, spreadsheets, images, videos, and audio files. All contain critical information across the claims processing lifecycle.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI.
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Leave us a comment and we will be glad to collaborate.
For a multi-account environment, you can track costs at an AWS account level to associate expenses. A combination of an AWS account and tags provides the best results. Implement a tagging strategy A tag is a label you assign to an AWS resource. The AWS reserved prefix aws: tags provide additional metadata tracked by AWS.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. This also led to a backlog of data that needed to be ingested.
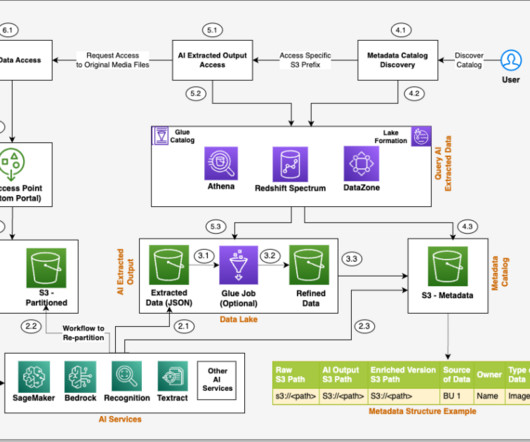
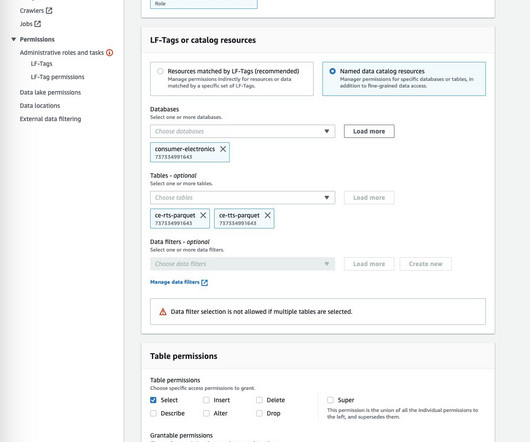
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context.
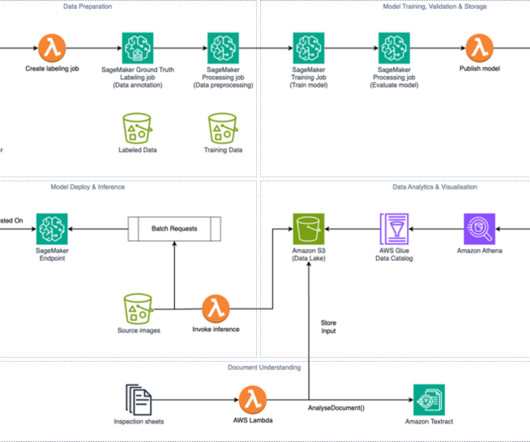
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. Precise Software Solutions, Inc. The platform helped the agency digitize and process forms, pictures, and other documents.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. Lets assume that the question What date will AWS re:invent 2024 occur? If the question was Whats the schedule for AWS events in December?,
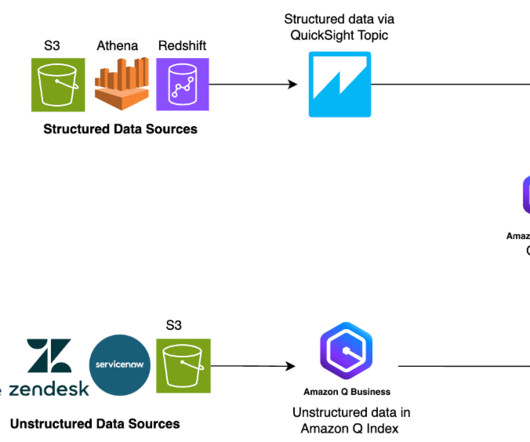
In this post, we show you how Amazon Q Business can help augment your generative AI needs in all the abovementioned use cases and more by answering questions, providing summaries, generating content, and securely completing tasks based on data and information in your enterprise systems. Traditionally, businesses face a challenge.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Depending on the question and data in QuickSight, Amazon Q Business may generate one or more visualizations as a response.
In the age of generative artificial intelligence (AI), data isnt just kingits the entire kingdom. This deep dive explores how organizations can architect their RAG implementations to harness the full potential of their data assets while maintaining security and compliance in highly regulated environments.
Writing data to an AWSdatalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the datalake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
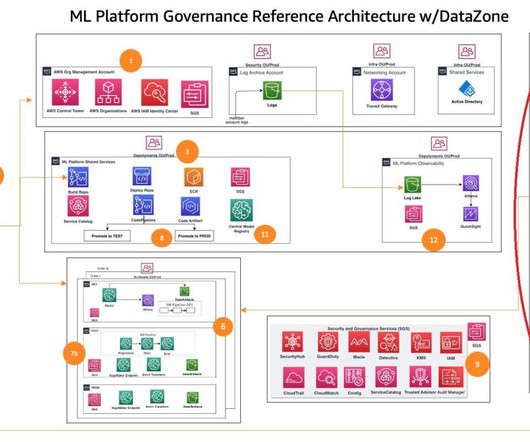
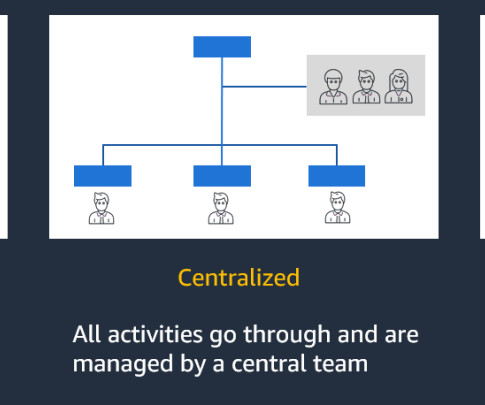
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. LOBs have autonomy over their AI workflows, models, and data within their respective AWS accounts.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI). As we can see the data retrieval is more accurate.
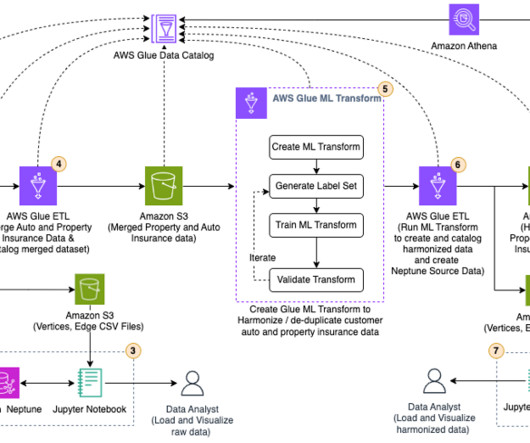
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
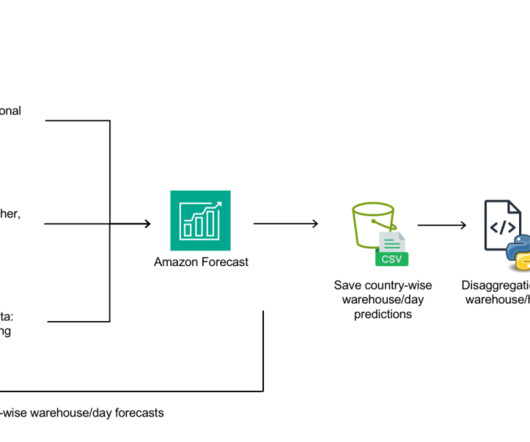
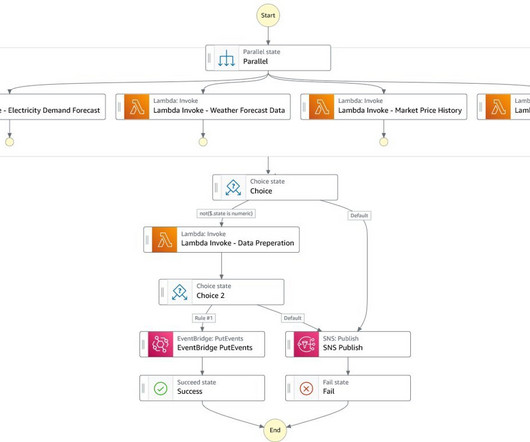
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
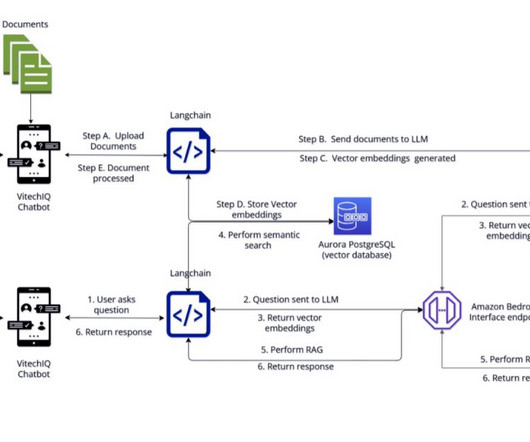
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
Amazon Simple Storage Service (Amazon S3) stores the model artifacts and creates a datalake to host the inference output, document analysis output, and other datasets in CSV format. About the authors Scott Patterson is a Senior Solutions Architect at AWS. Andreas Astrom is the Head of Technology and Innovation at Northpower
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
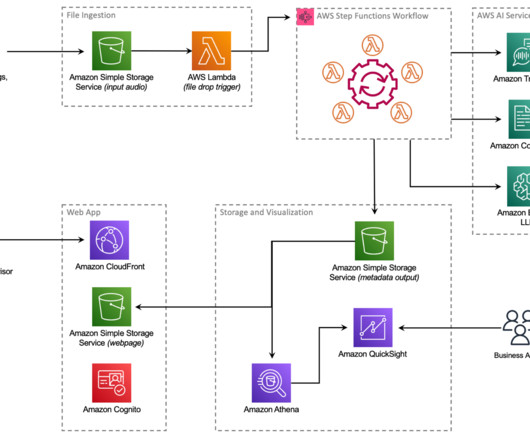
They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels. Solution requirements Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. In this article, we’ll focus on a datalake vs. data warehouse.
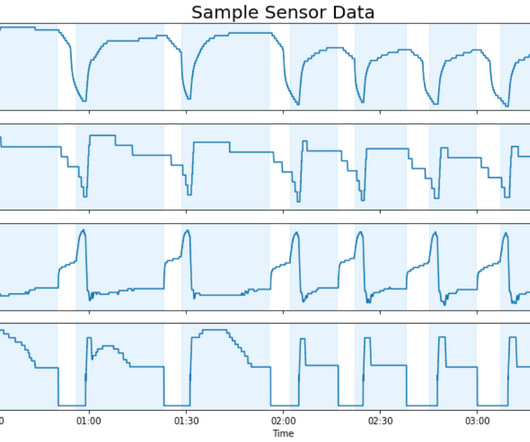
In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. We first highlight how we use AWS Glue for highly parallel data processing. This dramatically reduces the size of data while capturing features that characterize the equipment’s behavior.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources , including Amazon Athena , which supports Apache Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift.
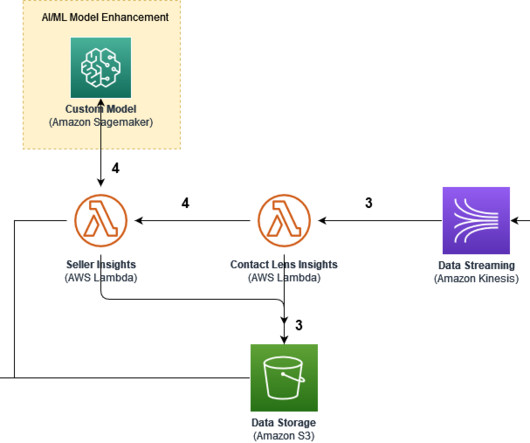
The large volume of contacts creates a challenge for CSBA to extract key information from the transcripts that helps sellers promptly address customer needs and improve customer experience. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability.
In such cases, using an FM to parse the data will provide better results. You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs. Many organizations store their data in structured formats within data warehouses and datalakes.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. earthquake, flood, or fire), where the data collected does not need to be as tightly controlled.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
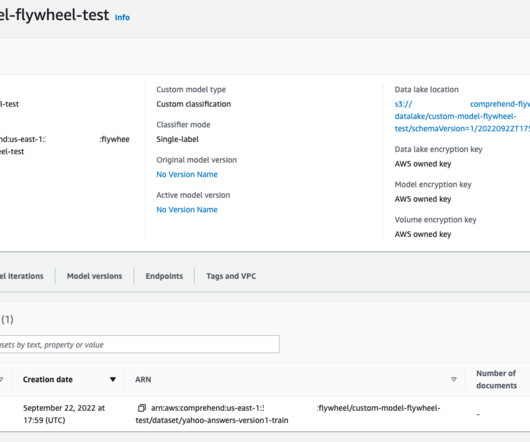
Flywheel creates a datalake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. The data can be accessed from AWS Open Data Registry.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
This post explores key insights and lessons learned from AWS customers in Europe, Middle East, and Africa (EMEA) who have successfully navigated this transition, providing a roadmap for others looking to follow suit. Il Sole 24 Ore leveraged its vast internal knowledge with a Retrieval Augmented Generation (RAG) solution powered by AWS.
The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only). Refer to Review knnVector Type Limitations for more information about the limitations of the knnVector type. Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content