This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
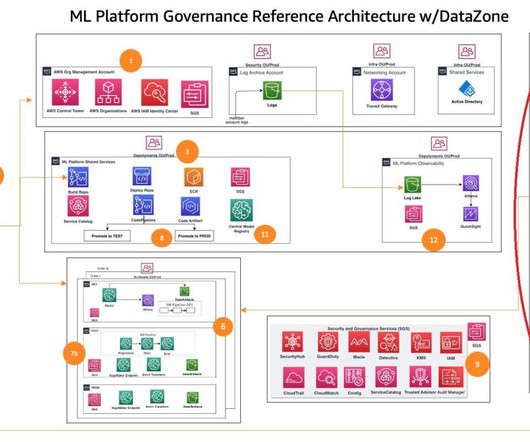
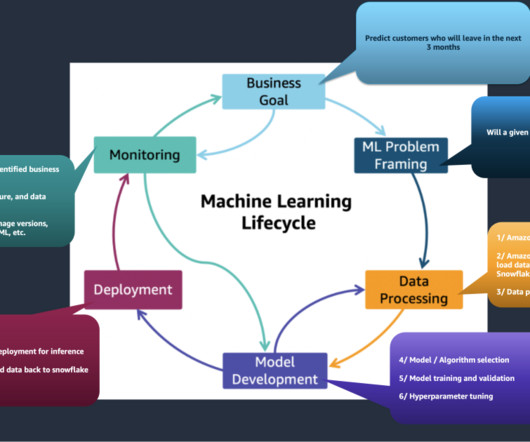
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up datagovernance at scale using Amazon DataZone for the data mesh. However, as data volumes and complexity continue to grow, effective datagovernance becomes a critical challenge.
AWS’ Legendary Presence at DAIS: Customer Speakers, Featured Breakouts, and Live Demos! Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI. AWS is also a proud sponsor of key Industry Forums – see full list below.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. At this point, you need to consider the use case and data isolation requirements. API Gateway also provides a WebSocket API.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex.
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Model versions should be managed centrally in a model registry.
Data catalogs play a pivotal role in modern data management strategies, acting as comprehensive inventories that enhance an organization’s ability to discover and utilize data assets. By providing a centralized view of metadata, data catalogs facilitate better analytics, datagovernance, and decision-making processes.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
Using an Amazon Q Business custom data source connector , you can gain insights into your organizations third party applications with the integration of generative AI and natural language processing. Alation is a data intelligence company serving more than 600 global enterprises, including 40% of the Fortune 100.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and governdata stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account.
This required custom integration efforts, along with complex AWS Identity and Access Management (IAM) policy management, further complicating the model governance process. We demonstrated through code how to register a model and update it with governance, technical, and business metadata in SageMaker Model Registry.
generally available on May 24, Alation introduces the Open Data Quality Initiative for the modern data stack, giving customers the freedom to choose the data quality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and DataGovernance application.
Throughout these examples, you will learn how the comprehensive suite of AWS services, including Amazon Bedrock and Amazon SageMaker , are the key to success. A key challenge is synthesizing diverse data into cohesive listings across more than 50 attributes, both textual and numerical.
However, you need to set up the infrastructure, implement datagovernance, and enable security and monitoring. The complete code for this example is available in the AWS Samples GitHub repository. Prerequisites To follow along with this post, you need an AWS account with the appropriate permissions.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
FL doesn’t require moving or sharing data across sites or with a centralized server during the model training process. In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. Participants can either choose to maintain their data in their on-premises systems or in an AWS account that they control.
The rise of big data technologies and the need for datagovernance further enhance the growth prospects in this field. Machine Learning Engineer Description Machine Learning Engineers are responsible for designing, building, and deploying machine learning models that enable organizations to make data-driven decisions.
Businesses globally recognize the power of generative AI and are eager to harness data and AI for unmatched growth, sustainable operations, streamlining and pioneering innovation. In this quest, IBM and AWS have forged a strategic alliance, aiming to transition AI’s business potential from mere talk to tangible action.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
In this post, we share AWS guidance that we have learned and developed as part of real-world projects into practical guides oriented towards the AWS Well-Architected Framework , which is used to build production infrastructure and applications on AWS. We focus on the operational excellence pillar in this post.
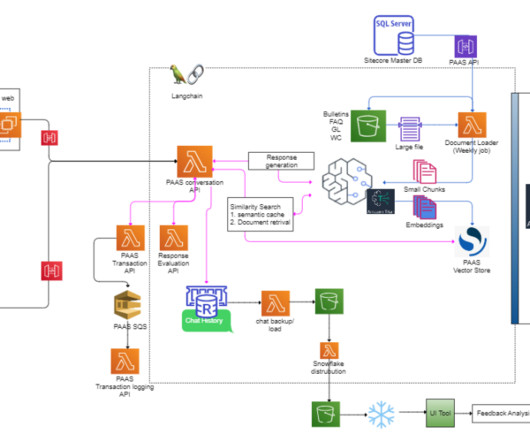
It employs a retrieval augmented generation (RAG) approach and a combination of AWS services alongside proprietary evaluations to promptly answer most user questions about the capabilities of the Verisk PAAS platform. Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Connect with him on LinkedIn.
This post explores key insights and lessons learned from AWS customers in Europe, Middle East, and Africa (EMEA) who have successfully navigated this transition, providing a roadmap for others looking to follow suit. Il Sole 24 Ore leveraged its vast internal knowledge with a Retrieval Augmented Generation (RAG) solution powered by AWS.
Because they’re in a highly regulated domain, HCLS partners and customers seek privacy-preserving mechanisms to manage and analyze large-scale, distributed, and sensitive data. To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface. Choose Create stack.
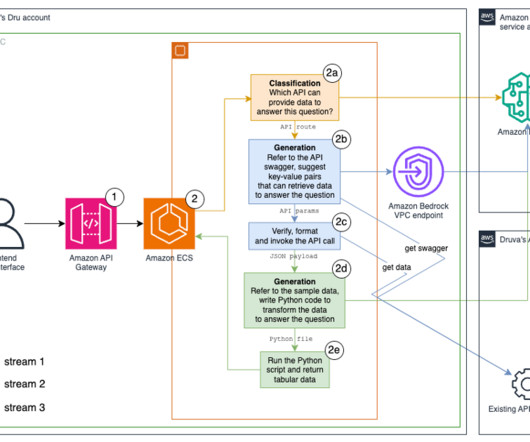
Druva enables cyber, data, and operational resilience for thousands of enterprises, and is trusted by 60 of the Fortune 500. Customers use Druva Data Resiliency Cloud to simplify data protection, streamline datagovernance, and gain data visibility and insights. The FM can’t initiate actions independently.
If pain points like these ring true for you, theres great news weve just announced significant enhancements to our Precisely Data Integrity Suite that directly target these challenges! Then, youll be ready to unlock new efficiencies and move forward with confident data-driven decision-making.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources , including Amazon Athena , which supports Apache Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. Choose Grant.
That’s why when it was announced that Alation achieved Amazon Web Services (AWS) Data and Analytics Competency in the datagovernance and security category, we were not only honored to receive this coveted designation, but we were also proud that it confirms the synergy — and customer benefits — of our AWS partnership.
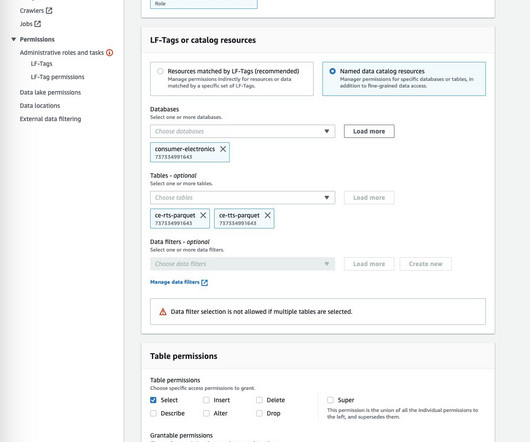
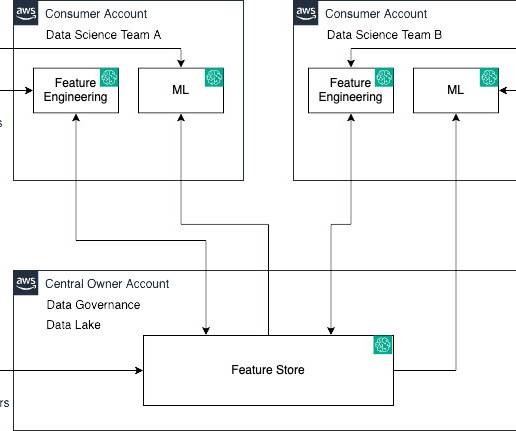
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Review the access policy to understand permissions granted.
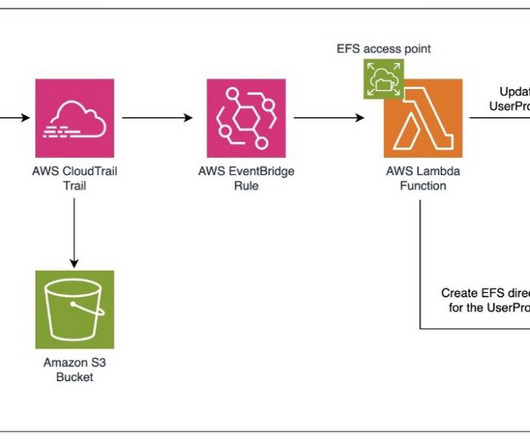
Amazon EFS provides a scalable fully managed elastic NFS file system for AWS compute instances. Using this folder, users can share data between their own private spaces. This means that each user within the domain will have their own private space on the EFS file system, allowing them to store and access their own data and files.
As IT leaders oversee migration, it’s critical they do not overlook datagovernance. Datagovernance is essential because it ensures people can access useful, high-quality data. Therefore, the question is not if a business should implement cloud data management and governance, but which framework is best for them.
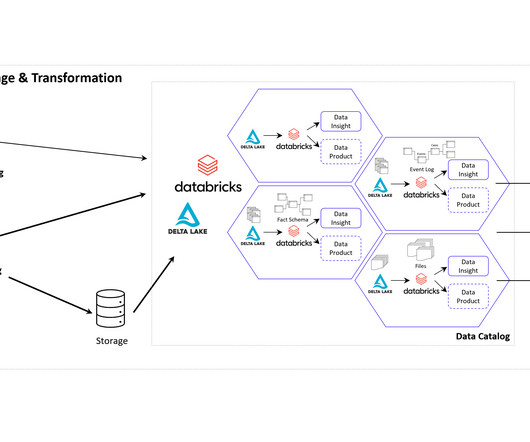
However, this concept on the Azure Cloud is just an example and can easily be implemented on the Google Cloud (GCP), Amazon Cloud (AWS) and now even on the SAP Cloud (Datasphere) using Databricks. Databricks is an ideal tool for realizing a Data Mesh due to its unified data platform, scalability, and performance.
For audio logs, choose an S3 bucket to store the logs and assign an AWS Key Management Service (AWS KMS) key for added security. The following is a sample AWS Lambda function code in Python for referencing the slot value of a phone number provided by the user. Choose Manage conversation logs. Select Selectively log utterances.
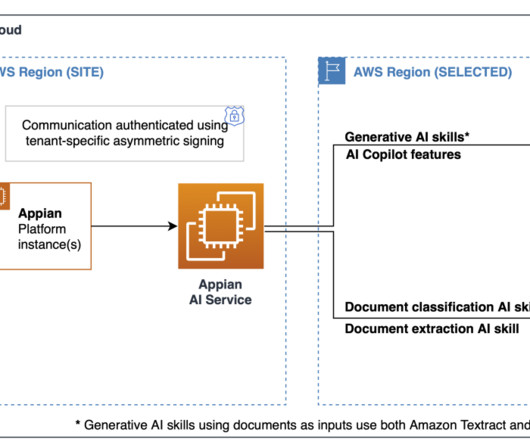
Background Appian , an AWS Partner with competencies in financial services, healthcare, and life sciences, is a leading provider of low-code automation software to streamline and optimize complex business processes for enterprises. This helps enhance the extracted data with deeper insights and contextual understanding.
Through ML EBA, experienced AWS ML subject matter experts work side by side with your cross-functional team to provide prescriptive guidance, remove blockers, and build organizational capability for a continued ML adoption. Additionally, AWS can offer financial incentives to help offset the costs for your first ML use case.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care. Data Management – Efficient data management is crucial for AI/ML platforms.
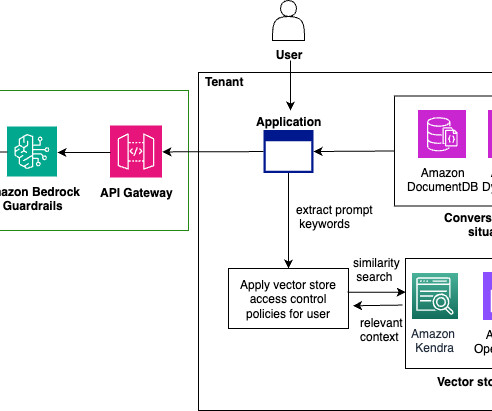
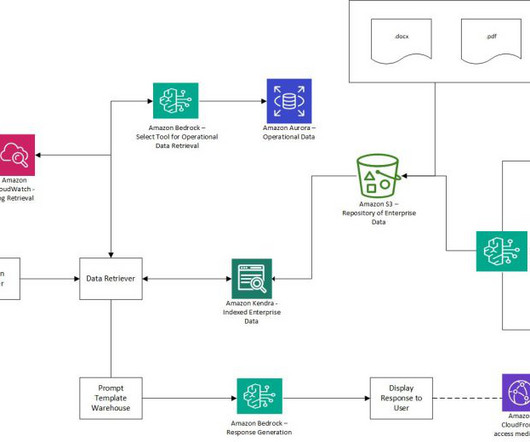
This helps maintain data privacy and security, preventing sensitive or restricted information from being inadvertently surfaced or used in generated responses. This access control approach can be extended to other relevant metadata fields, such as year or department, further refining the subset of data accessible to each user or application.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. Seamless Data Integration : Connect and integrate data from diverse sources easily.
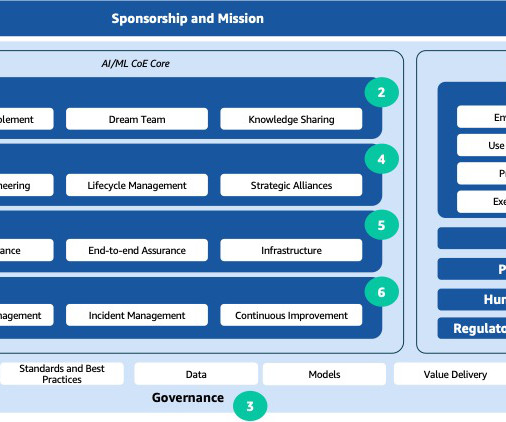
This growth underscores the escalating need for robust governance frameworks that ensure AI systems are transparent, fair and comply with increasing regulatory demands. Data security and privacy Ensuring the security and privacy of data used in AI models is crucial.
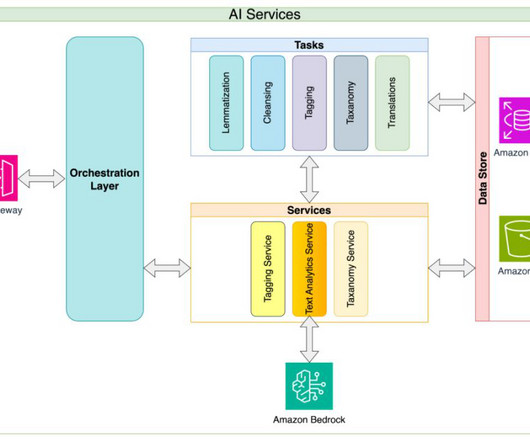
Finally, the service approach allows for a single point to implement any datagovernance and security policies that evolve as AI governance matures in the organization. If you interested in reading about other intriguing Amazon Bedrock applications, see the Amazon Bedrock specific section of the AWS Machine Learning Blog.
These encompass a holistic approach, covering datagovernance, model development, ethical deployment, and ongoing monitoring, reinforcing the organization’s commitment to responsible and ethical AI/ML practices. Datagovernance is essential for AI applications, because these applications often use large amounts of data.
It relies on a Retrieval Augmented Generation (RAG) approach and a mix of AWS services and proprietary configuration to instantly answer most user questions about the Verisk FAST platform’s extensive capabilities. The pipeline architecture allows for iterative enhancement as Verisk FAST’s use cases evolve.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content