This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Previously, setting up a custom labeling job required specifying two AWS Lambda functions: a pre-annotation function, which is run on each dataset object before it’s sent to workers, and a post-annotation function, which is run on the annotations of each dataset object and consolidates multiple worker annotations if needed.
We explore two approaches: using the SageMaker Python SDK for programmatic implementation, and using the Amazon SageMaker Studio UI for a more visual, interactive experience. In this post, we walked through the step-by-step process of implementing this feature through both the SageMaker Python SDK and SageMaker Studio UI.
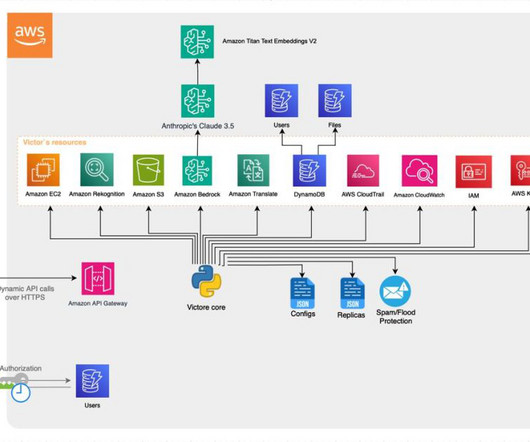
This post details our technical implementation using AWS services to create a scalable, multilingual AI assistant system that provides automated assistance while maintaining data security and GDPR compliance. Amazon Titan Embeddings also integrates smoothly with AWS, simplifying tasks like indexing, search, and retrieval.
A training plan provides simple and predictable access to accelerated compute resources (supporting P4d, P5, P5e, P5en, and trn2 as of the time of writing), allowing you to use this compute capacity to run model training on either Amazon SageMaker training jobs or SageMaker HyperPod.
invoke(input_text=Convert 11am from NYC time to London time) We showcase an example of building an agent to understand your Amazon Web Service (AWS) spend by connecting to AWS Cost Explorer , Amazon CloudWatch , and Perplexity AI through MCP. This gives you an AI agent that can transform the way you manage your AWS spend.
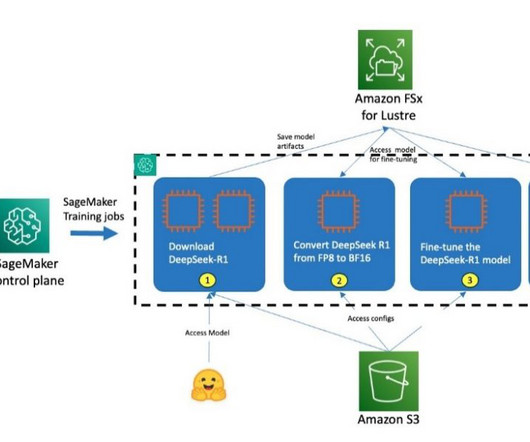
You can now use DeepSeek-R1 to build, experiment, and responsibly scale your generative AI ideas on AWS. To check if you have quotas for P5e, open the Service Quotas console and under AWS Services , choose Amazon SageMaker , and confirm youre using ml.p5e.48xlarge 48xlarge instance in the AWS Region you are deploying.
This post describes a pattern that AWS and Cisco teams have developed and deployed that is viable at scale and addresses a broad set of challenging enterprise use cases. AWS solution architecture In this section, we illustrate how you might implement the architecture on AWS.
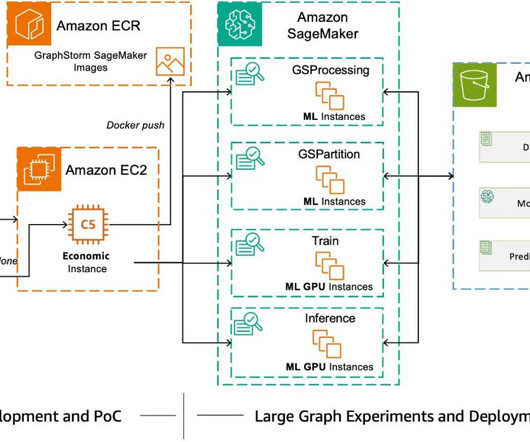
Although GraphStorm can run efficiently on single instances for small graphs, it truly shines when scaling to enterprise-level graphs in distributed mode using a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances or Amazon SageMaker. Today, AWS AI released GraphStorm v0.4. This dataset has approximately 170,000 nodes and 1.2
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
MLOps practitioners have many options to establish an MLOps platform; one among them is cloud-based integrated platforms that scale with data science teams. AWS provides a full-stack of services to establish an MLOps platform in the cloud that is customizable to your needs while reaping all the benefits of doing ML in the cloud.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping to support data security. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping to support data security. His area of focus is generative AI and AWS AI Accelerators.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. Access to accelerated instances (GPUs) for hosting the LLMs.
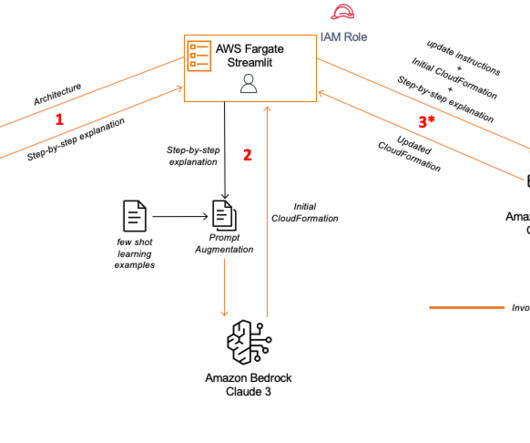
Architecting specific AWS Cloud solutions involves creating diagrams that show relationships and interactions between different services. Instead of building the code manually, you can use Anthropic’s Claude 3’s image analysis capabilities to generate AWS CloudFormation templates by passing an architecture diagram as input.
AWS customers that implement secure development environments often have to restrict outbound and inbound internet traffic. Therefore, accessing AWS services without leaving the AWS network can be a secure workflow. Therefore, accessing AWS services without leaving the AWS network can be a secure workflow.
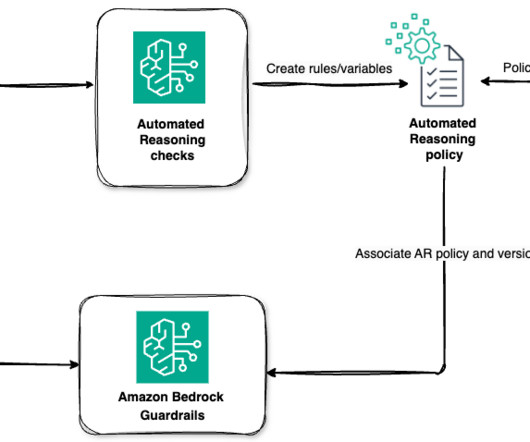
To improve factual accuracy of large language model (LLM) responses, AWS announced Amazon Bedrock Automated Reasoning checks (in gated preview) at AWS re:Invent 2024. For example, AWS customers have direct access to automated reasoning-based features such as IAM Access Analyzer , S3 Block Public Access , or VPC Reachability Analyzer.
Technical challenges with multi-modal data further include the complexity of integrating and modeling different data types, the difficulty of combining data from multiple modalities (text, images, audio, video), and the need for advanced computerscience skills and sophisticated analysis tools.
With this launch, you can now deploy NVIDIAs optimized reranking and embedding models to build, experiment, and responsibly scale your generative AI ideas on AWS. As part of NVIDIA AI Enterprise available in AWS Marketplace , NIM is a set of user-friendly microservices designed to streamline and accelerate the deployment of generative AI.
To access SageMaker Studio on the AWS Management Console , you need to set up an Amazon SageMaker domain. You also need an AWS Identity and Access Management (IAM) role with appropriate permissions. About the Author Vivek Gangasani is a Senior GenAI Specialist Solutions Architect at AWS.
run_opensearch.sh Running OpenSearch Locally A script to start OpenSearch using Docker for local testing before deploying to AWS. Implement and analyze search results using Python scripts. Now, lets implement a Python script to execute the neural search query in OpenSearch. These can be used for evaluation and comparison.
You can now use state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch. Prerequisites To try out Pixtral 12B in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
Prerequisites To run this step-by-step guide, you need an AWS account with permissions to SageMaker, Amazon Elastic Container Registry (Amazon ECR), AWS Identity and Access Management (IAM), and AWS CodeBuild. Complete the following steps: Sign in to the AWS Management Console and open the IAM console. base-ubuntu18.04
Home Table of Contents Introduction to GitHub Actions for Python Projects Introduction What Is CICD? For Python projects, CI/CD pipelines ensure that your code is consistently integrated and delivered with high quality and reliability. Git is the most commonly used VCS for Python projects, enabling collaboration and version tracking.
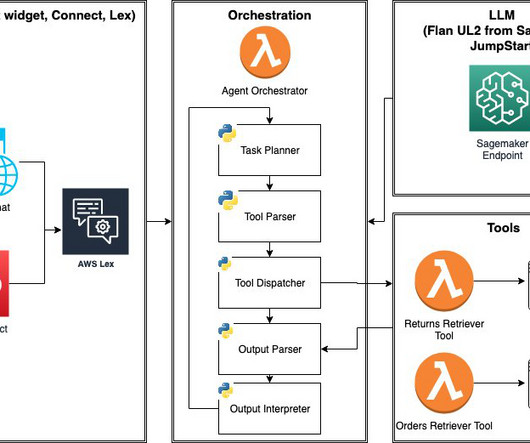
In this post, we introduce LLM agents and demonstrate how to build and deploy an e-commerce LLM agent using Amazon SageMaker JumpStart and AWS Lambda. To power the LLM agent, we use a Flan-UL2 model deployed as a SageMaker endpoint and use data retrieval tools built with AWS Lambda.
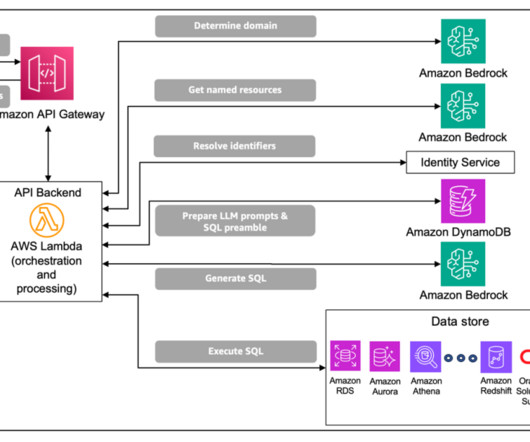
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Solution overview The following diagram provides a high-level overview of AWS services and features through a sample use case. The response only cites sources that are relevant to the query.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for data science, machine learning (ML), and computationalscience. Given the importance of Jupyter to data scientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
The solution also uses Amazon Bedrock , a fully managed service that makes foundation models (FMs) from Amazon and third-party model providers accessible through the AWS Management Console and APIs. Prerequisites For this tutorial, you need a bash terminal with Python 3.9 in computerscience. - Dr. Liskov earned her Ph.D.
The computer use agent demo powered by Amazon Bedrock Agents provides the following benefits: Secure execution environment Execution of computer use tools in a sandbox environment with limited access to the AWS ecosystem and the web. Prerequisites AWS Command Line Interface (CLI), follow instructions here. Require Node.js
Implementation details We spin up the cluster by calling the SageMaker control plane through APIs or the AWS Command Line Interface (AWS CLI) or using the SageMaker AWS SDK. In response, SageMaker spins up training jobs with the requested number and type of compute instances. 24xlarge compute instance.
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. Alternatively, you can also use AWS Systems Manager and run a command like the following to start the session.
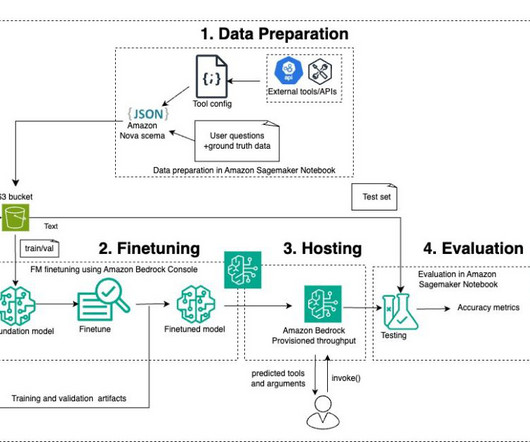
Amazon Nova models and Amazon Bedrock Amazon Nova models , unveiled at AWS re:Invent in December 2024, are optimized to deliver exceptional price-performance value, offering state-of-the-art performance on key text-understanding benchmarks at low cost. Choose us-east-1 as the AWS Region. gpus 2'] Ground truth pattern: python(3?)
Deploying a Falcon 3 model through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK. About the authors Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS.
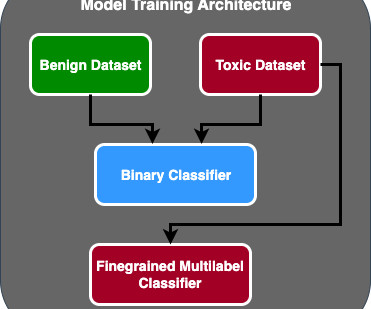
In an effort to create and maintain a socially responsible gaming environment, AWS Professional Services was asked to build a mechanism that detects inappropriate language (toxic speech) within online gaming player interactions. Unfortunately, as in the real world, not all players communicate appropriately and respectfully.
Solution overview Starting today, with SageMaker JumpStart and its private hub feature, administrators can create repositories for a subset of models tailored to different teams, use cases, or license requirements using the Amazon SageMaker Python SDK. For a list of filters you can apply, refer to SageMaker Python SDK.
The workflow steps are as follows: Set up a SageMaker notebook and an AWS Identity and Access Management (IAM) role with appropriate permissions to allow SageMaker to access Amazon Elastic Container Registry (Amazon ECR), Secrets Manager, and other services within your AWS account. AWS Region Link us-east-1 (N.
Beyond the out-of-control cost, there is evidence that degrees do not map to the skills needed in today’s job market, and there’s an increasing disconnect—particularly in computerscience—between the skills employers want and the skills colleges teach. We won’t name names, but we challenge you to do your own research.
Some examples include extracting players and positions in an NFL game summary, products mentioned in an AWS keynote transcript, or key names from an article on a favorite tech company. We extract the default generic entities through the AWS SDK for Python (Boto3) as follows: import pandas as pd comprehend_client = boto3.client("comprehend")
You can discover and deploy the Falcon 2 11B model with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines , Amazon SageMaker Debugger , or container logs.
You can now discover and deploy Mistral models in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with Amazon SageMaker features such as Amazon SageMaker Pipelines , Amazon SageMaker Debugger , or container logs. Preston Tuggle is a Sr.
For instance, faculty in an educational institution belongs to different departments, and if a professor belonging to the computerscience department signs in to the application and searches with the keywords “ faculty courses ,” then documents relevant to the same department come up as the top results, based on data source availability.
You can execute each step in the training pipeline by initiating the process through the SageMaker control plane using APIs, AWS Command Line Interface (AWS CLI), or the SageMaker ModelTrainer SDK. In response, SageMaker launches training jobs with the requested number and type of compute instances to run specific tasks.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content