This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
inherits tags on the cluster definition, while serverless adheres to Serverless Budget Policies ( AWS | Azure | GCP ). Refer to this article ( AWS | AZURE | GCP ) for details about tagging different compute resources, and this article ( AWS | Azure | GCP ) for details about tagging Unity Catalog securables.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and data preparation activities.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
Creating professional AWS architecture diagrams is a fundamental task for solutions architects, developers, and technical teams. By using generative AI through natural language prompts, architects can now generate professional diagrams in minutes rather than hours, while adhering to AWS best practices.
It gives these users a single, intuitive entry point to interact with data and AI—without needing to understand clusters, queries, models, or notebooks. Databricks One is a new product experience designed specifically for business users.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
The key here is to focus on concepts like supervised vs. unsupervised learning, regression, classification, clustering, and model evaluation. Deploying & Managing LLM applications In Production Environments: How to deploy LLMs (Large Language Models) as APIs using Hugging Face + AWS - Covers deploying LLMs as APIs in the cloud.
They fine-tuned this model using their proprietary dataset and in-house datascience expertise. Integration with existing systems on AWS: Lumi seamlessly integrated SageMaker Asynchronous Inference endpoints with their existing loan processing pipeline. The pipeline leverages several AWS services familiar to Lumis team.
Managing access control in enterprise machine learning (ML) environments presents significant challenges, particularly when multiple teams share Amazon SageMaker AI resources within a single Amazon Web Services (AWS) account. Refer to the Operating model whitepaper for best practices on account structure.
Instead of running on a fixed schedule, maintenance now adapts to workload patterns and data layout to optimize cost and performance automatically. This reduces unnecessary rewrites, improving performance and lowering compute costs by avoiding full file rewrites during updates and deletes.
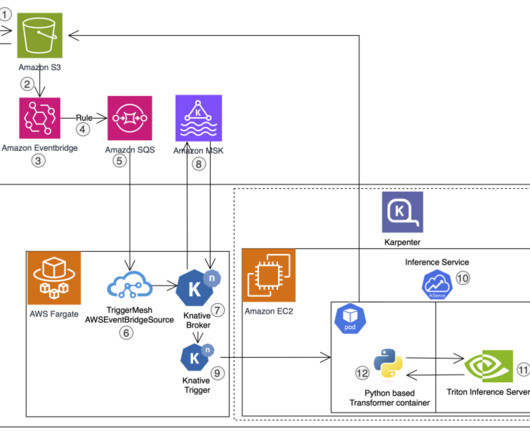
In this post, we dive deep into how CONXAI hosts the state-of-the-art OneFormer segmentation model on AWS using Amazon Simple Storage Service (Amazon S3), Amazon Elastic Kubernetes Service (Amazon EKS), KServe, and NVIDIA Triton. Our journey to AWS Initially, CONXAI started with a small cloud provider specializing in offering affordable GPUs.
The integration with Amazon Bedrock is achieved through the Boto3 Python module, which serves as an interface to the AWS, enabling seamless interaction with Amazon Bedrock and the deployment of the classification model. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
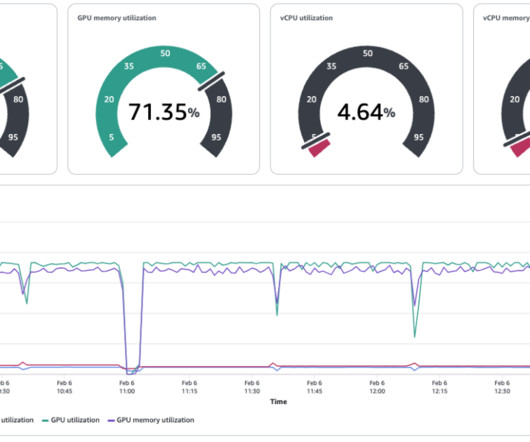
On a lightweight four-node cluster, the TTR and TTS analyses completed in 5 and 40 minutes respectively on the network described above (1,700 nodes)—all for under $10 in cloud spend. This highlights the solution’s impressive speed and cost-effectiveness.
Managing and optimizing AWS infrastructure costs is a critical challenge for organizations of all sizes. In this post, we explore how to use Amazon Q CLI with the AWS Cost Analysis MCP server to perform sophisticated cost analysis that follows AWS best practices.
Scenario 1: Multiple single GPU cluster In this scenario, assume youre running an endpoint with three ml.g5.2xlarge instances, each with a single GPU. The existing instances can still serve traffic, but to move the endpoint out of the failed status, you need to contact your AWS support team.
The following code imports the necessary libraries, including Boto3 for AWS services, LangChain components, and Streamlit. Clean up When you have finished experimenting with this solution, clean up your resources to prevent AWS charges from being incurred: Empty the S3 buckets. Clone the GitHub repo to make a local copy.
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. They were also able to use the familiar AWS SDK to quickly and effortlessly integrate Amazon Bedrock into their application.
At AWS re:Invent 2024, we launched a new innovation in Amazon SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS) that enables you to run generative AI development tasks on shared accelerated compute resources efficiently and reduce costs by up to 40%.
Popular cloud load balancers like AWS ELB, Google Cloud Load Balancer, and Azure Load Balancer enhance cloud performance. Learning cloud computing and datascience through Pickl.AI It balances the load among multiple servers in a cluster, ensuring no single server gets overwhelmed.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/DataScience knowledge would be good. On the backend we're using 100% Go with AWS primitives. Where you live means something. City vs. Countryside.
This article was published as a part of the DataScience Blogathon. Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
Welcome to the first beta edition of Cloud DataScience News. This will cover major announcements and news for doing datascience in the cloud. Azure Synapse Analytics This is the future of data warehousing. If you are at a University or non-profit, you can ask for cash and/or AWS credits. Microsoft Azure.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
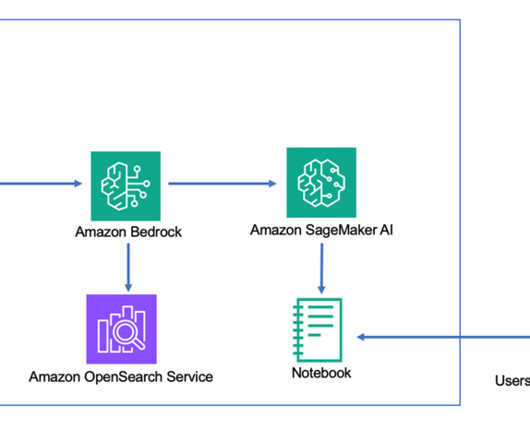
Amazon Bedrock Knowledge Bases has extended its vector store options by enabling support for Amazon OpenSearch Service managed clusters, further strengthening its capabilities as a fully managed Retrieval Augmented Generation (RAG) solution. Why use OpenSearch Service Managed Cluster as a vector store?
It provides a large cluster of clusters on a single machine. Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like data analysis, fraud detection, and machine learning. AWS SageMaker also has a CLI for model creation and management.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Health Insurance Portability and Accountability Act (HIPAA) eligibility and General Data Protection Regulation (GDPR) compliance.
Datascience is a growing profession. Standards and expectations are rapidly changing, especially in regards to the types of technology used to create datascience projects. Most data scientists are using some form of DevOps interface these days. Benefits of Kubernetes for DataScience.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
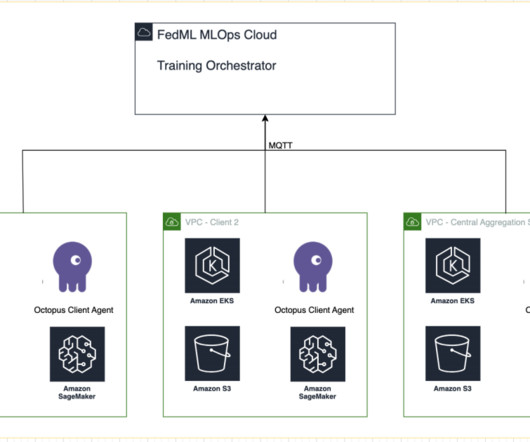
The need for federated learning in healthcare Healthcare relies heavily on distributed data sources to make accurate predictions and assessments about patient care. Limiting the available data sources to protect privacy negatively affects result accuracy and, ultimately, the quality of patient care.
This article was published as a part of the DataScience Blogathon. Introduction In machine learning, the data is an essential part of the training of machine learning algorithms. The amount of data and the data quality highly affect the results from the machine learning algorithms.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. These include dbt pipelines, data gathering jobs, training, evaluation, and batch inference jobs for smaller models.
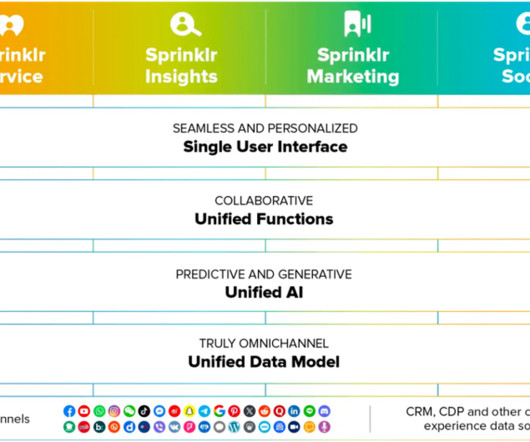
Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity. During this journey, we collaborated with our AWS technical account manager and the Graviton software engineering teams.
This article was published as a part of the DataScience Blogathon. Introduction on Amazon Elasticsearch Service Amazon Elasticsearch Service is a powerful tool that allows you to perform a number of functions. Let us examine how this powerful tool works behind the scenes.
In April 2023, AWS unveiled Amazon Bedrock , which provides a way to build generative AI-powered apps via pre-trained models from startups including AI21 Labs , Anthropic , and Stability AI. Amazon Bedrock also offers access to Titan foundation models, a family of models trained in-house by AWS. Deploy the AWS CDK application.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
By using the Livy REST APIs , SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined datascience experience within the Amazon SageMaker ecosystem. This same interface is also used for provisioning EMR clusters.
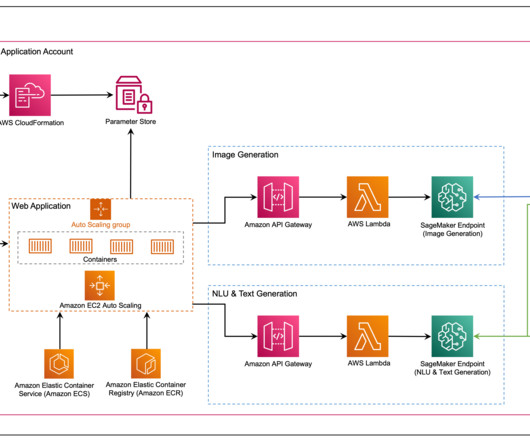
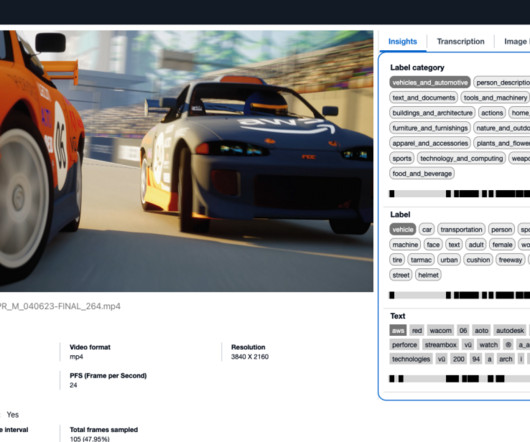
In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes. This solution, powered by AWS AI and generative AI services, meets these needs.
Datascience teams working with artificial intelligence and machine learning (AI/ML) face a growing challenge as models become more complex. Provided at no additional cost, the DLCs come pre-packaged with CUDA libraries, popular ML frameworks, and the Elastic Fabric Adapter (EFA) plug-in for distributed training and inference on AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content