This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why We Built Databricks One At Databricks, our mission is to democratize data and AI. For years, we’ve focused on helping technical teams—dataengineers, scientists, and analysts—build pipelines, develop advanced models, and deliver insights at scale.
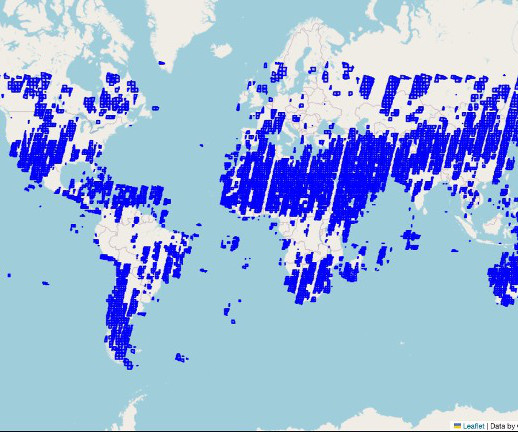
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and MLengineers to build, train, and deploy ML models using geospatial data. Identify areas of interest We begin by illustrating how SageMaker can be applied to analyze geospatial data at a global scale.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift data warehouse.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
Organizations need a unified, streamlined approach that simplifies the entire process from data preparation to model deployment. To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities.
Machine learning (ML) is the technology that automates tasks and provides insights. It allows data scientists to build models that can automate specific tasks. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It provides a large cluster of clusters on a single machine.
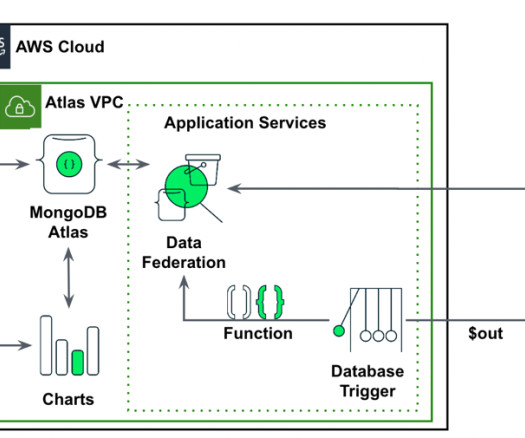
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
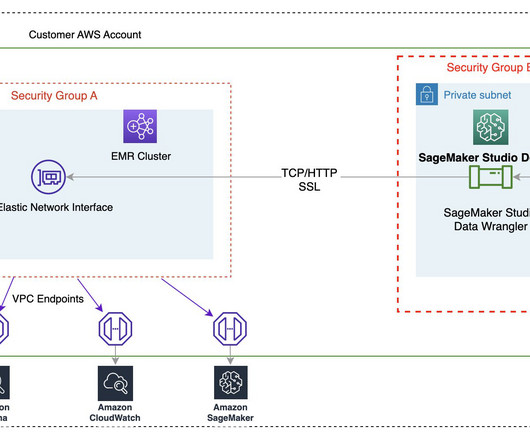
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
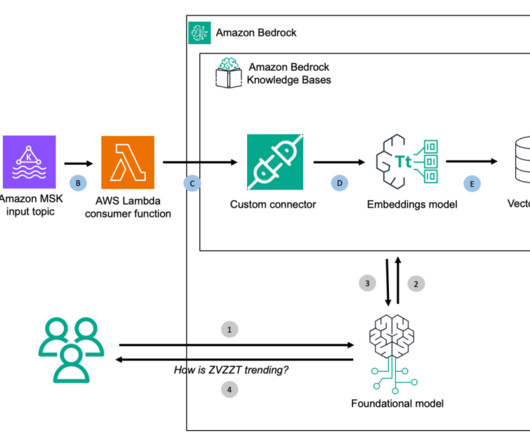
Amazon MSK is a streaming data service that manages Apache Kafka infrastructure and operations, making it straightforward to run Apache Kafka applications on Amazon Web Services (AWS). Configure the architecture To try this architecture, deploy the AWS CloudFormation template from this GitHub repository in your AWS account.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
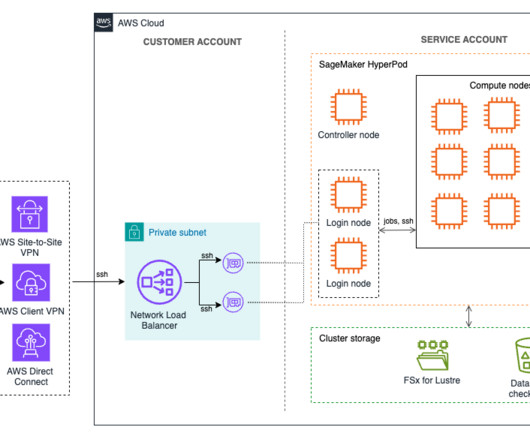
Amazon SageMaker HyperPod is designed to support large-scale machine learning (ML) operations, providing a robust environment for training foundation models (FMs) over extended periods. This blog post specifically applies to HyperPod clusters using Slurm as the orchestrator.
As organizations increasingly deploy foundation models (FMs) and other machine learning (ML) models to production, they face challenges related to resource utilization, cost-efficiency, and maintaining high availability during updates. The minimum AWS service quota value for ml.g5.12xlarge is ROUNDUP(2 x 1 / 4) + 8 = 9.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Now, with the specialized geospatial container in SageMaker, managing and running clusters for geospatial processing has become more straightforward.
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. On the Import data page, for Data Source , choose DocumentDB and Add Connection.
By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs. Note we have two folders.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML.
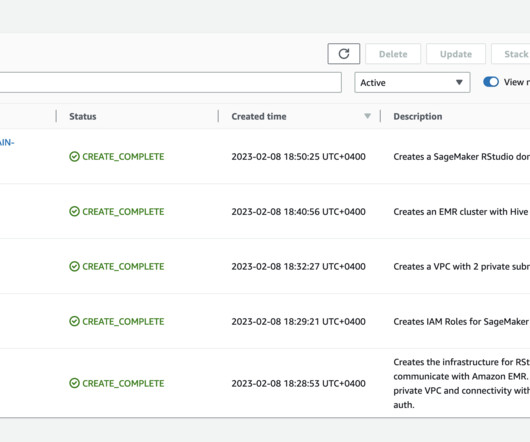
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Data scientists and dataengineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. 1 Public subnet.
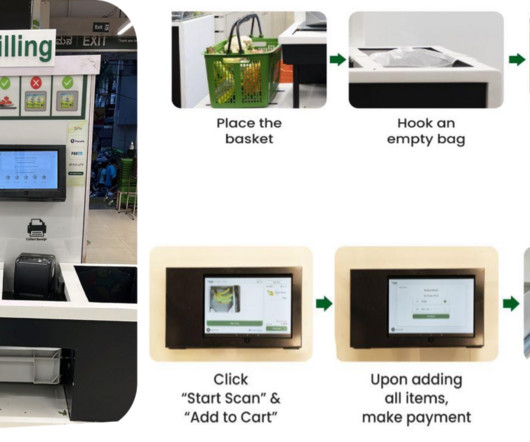
The BigBasket team was running open source, in-house ML algorithms for computer vision object recognition to power AI-enabled checkout at their Fresho (physical) stores. Their objective was to fine-tune an existing computer vision machine learning (ML) model for SKU detection. Their starting training data size was over 1.5
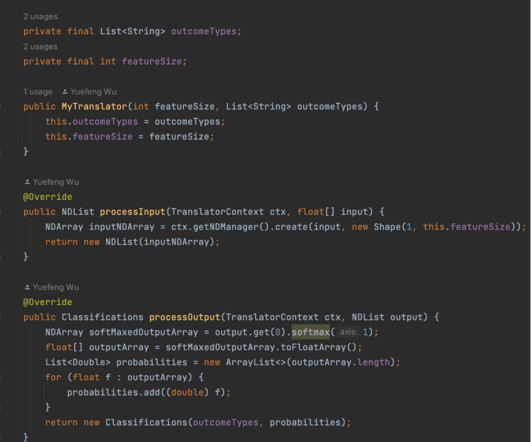
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. The architecture of DJL is engine agnostic.
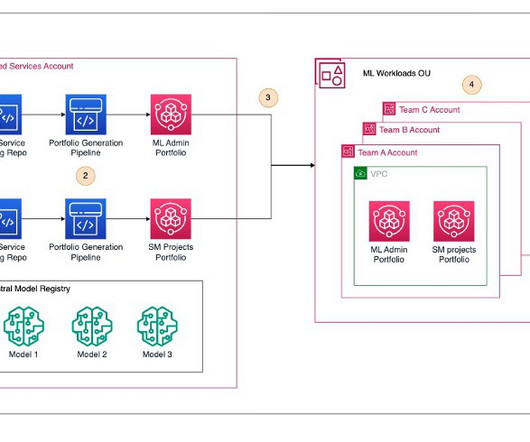
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
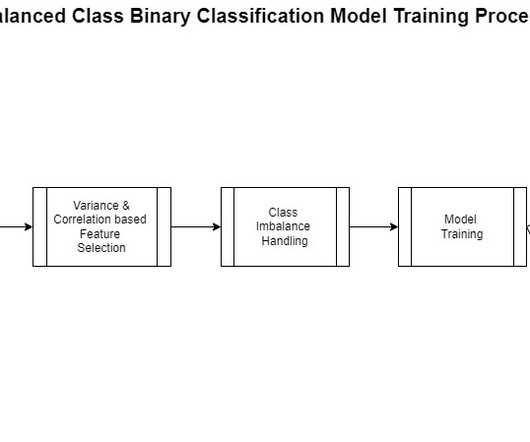
For any machine learning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
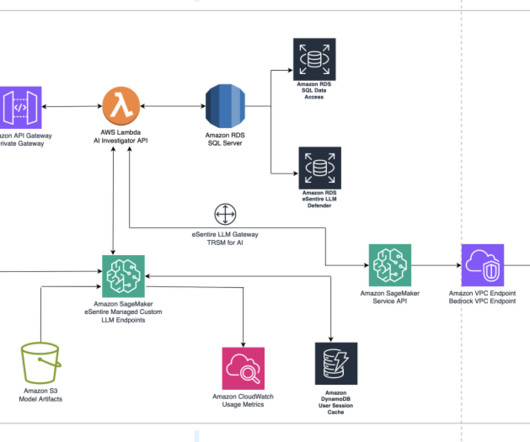
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake.
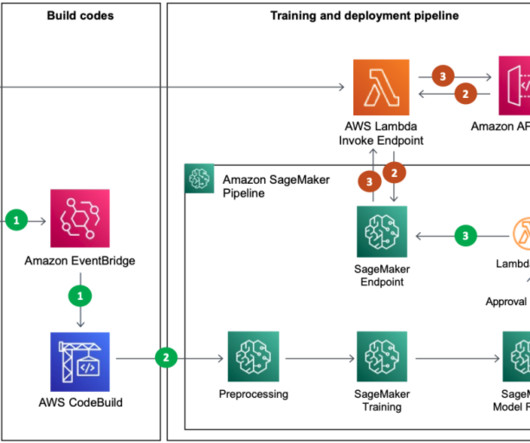
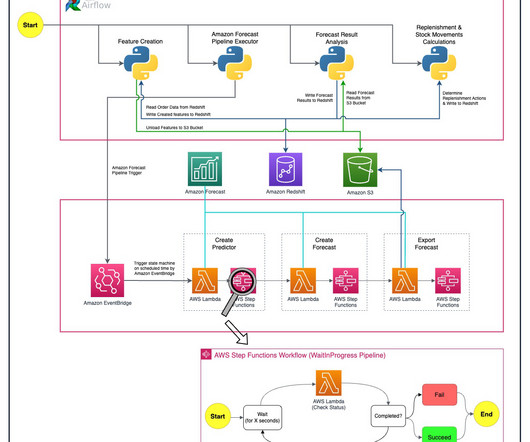
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. When the preprocessing batch was complete, the training/test data needed for training was partitioned based on runtime and stored in Amazon S3.
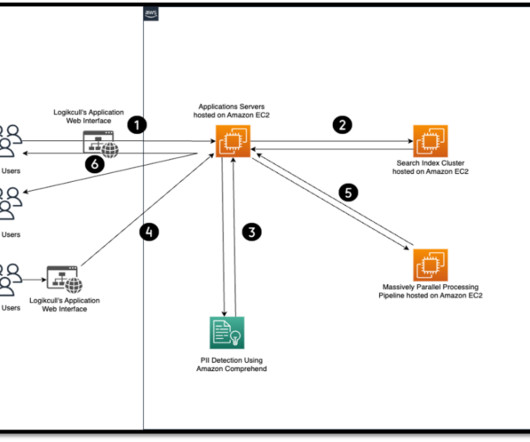
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
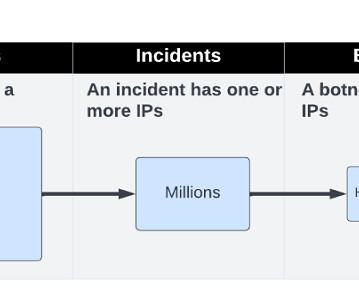
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. ML Governance: A Lean Approach Ryan Dawson | Principal DataEngineer | Thoughtworks Meissane Chami | Senior MLEngineer | Thoughtworks During this session, you’ll discuss the day-to-day realities of ML Governance.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
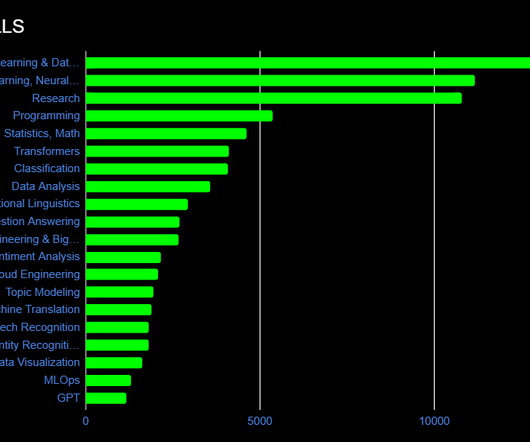
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve.
We use an example of an illustrative ServiceNow platform to discuss technical topics related to AWS services. When preparing to connect Amazon Q Business applications to AWS IAM Identity Center , you need to enable ACL indexing and identity crawling and re-synchronize your connector. John has access to all ServiceNow document types.
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. Mutlu Polatcan is a Staff DataEngineer at Getir, specializing in designing and building cloud-native data platforms.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data.
Build Classification and Regression Models with Spark on AWS Suman Debnath | Principal Developer Advocate, DataEngineering | Amazon Web Services This immersive session will cover optimizing PySpark and best practices for Spark MLlib.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
Theyre looking for people who know all related skills, and have studied computer science and software engineering. As MLOps become more relevant to ML demand for strong software architecture skills will increase aswell. Environments Data science environments encompass the tools and platforms where professionals perform their work.
Strategies for Overcoming Challenges Now that we understand the hurdles, let’s explore strategies to overcome them and successfully scale Data Science projects. Embrace Distributed Processing Frameworks Frameworks like Apache Spark and Spark Streaming enable distributed processing of large datasets across clusters of machines.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. This versatility allows prompt engineers to adapt it to different projects and needs.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a dataengineering team as one of the first engineers. We were focused on building data pipelines and models to protect our users from malicious phonecalls.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content