This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
inherits tags on the cluster definition, while serverless adheres to Serverless Budget Policies ( AWS | Azure | GCP ). Refer to this article ( AWS | AZURE | GCP ) for details about tagging different compute resources, and this article ( AWS | Azure | GCP ) for details about tagging Unity Catalog securables.
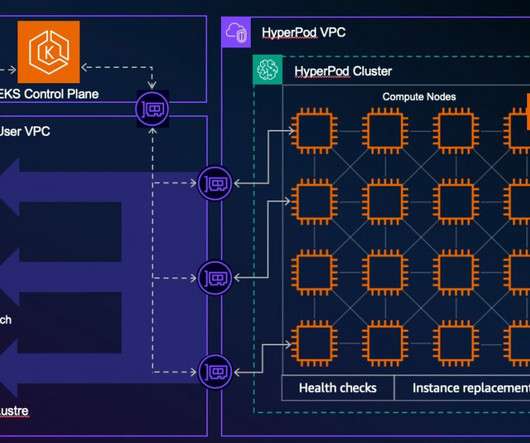
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Solution overview The steps to implement the solution are as follows: Create the EKS cluster.
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.
As Kubernetes clusters grow in complexity, managing them efficiently becomes increasingly challenging. Integrating advanced generative AI tools like K8sGPT and Amazon Bedrock can revolutionize Kubernetes cluster operations and maintenance.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
To implement this solution, complete the following steps: Set up Zero-ETL integration from the AWS Management Console for Amazon Relational Database Service (Amazon RDS). An AWS Identity and Access Management (IAM) user with sufficient permissions to interact with the AWS Management Console and related AWS services.
This service offers numerous advantages for building and deploying generative AI applications, including access to a wide range of pre-trained models with ready-to-use artifacts, a user-friendly interface, and seamless scalability within the AWS ecosystem. Choose Store to save your secret.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. Technical architecture The overall solution is implemented using AWS services and LangChain. AWS Glue AWS Glue is used for data cataloging.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain. Database name : Enter dev.
The complexity of Kubernetes manifests and cluster management can pose significant challenges, potentially slowing down development cycles and resource utilization. Solution overview Implementing this solution is straightforward, whether you’re working with existing SageMaker HyperPod clusters or setting up a new deployment.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
At ByteDance, we collaborated with Amazon Web Services (AWS) to deploy multimodal large language models (LLMs) for video understanding using AWS Inferentia2 across multiple AWS Regions around the world. Solution overview Weve collaborated with AWS since the first generation of Inferentia chips.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
Creating professional AWS architecture diagrams is a fundamental task for solutions architects, developers, and technical teams. By using generative AI through natural language prompts, architects can now generate professional diagrams in minutes rather than hours, while adhering to AWS best practices.
You can chat with your structured data by setting up structured data ingestion from AWS Glue Data Catalog tables and Amazon Redshift clusters in a few steps, using the power of Amazon Bedrock Knowledge Bases structured data retrieval. Prerequisites To implement the solution provided in this post, you must have an AWS account.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
DGX Cloud on Amazon Web Services (AWS) represents a significant leap forward in democratizing access to high-performance AI infrastructure. By combining NVIDIA GPU expertise with AWS scalable cloud services, organizations can accelerate their time-to-train, reduce operational complexity, and unlock new business opportunities.
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
Solution overview Implementing the solution consists of the following high-level steps: Set up your environment and the permissions to access Amazon HyperPod clusters in SageMaker Studio. You can now use SageMaker Studio to discover the SageMaker HyperPod clusters, and view cluster details and metrics.
Amazon Web Services (AWS) provides the essential compute infrastructure to support these endeavors, offering scalable and powerful resources through Amazon SageMaker HyperPod. To offer a more concrete look at these trends, the following is a deep dive into how climate tech startups are building FMs on AWS.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. Surya Kari is a Senior Generative AI Data Scientist at AWS.
For deployment, we containerized Open WebUI and orchestrated it on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster, using automatic scaling to dynamically adjust resources based on demand while maintaining high availability. This data lakehouse, internally referred to as Luna, is built using Apache Spark and Apache Hudi.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Responsibility for maintenance and troubleshooting: Rockets DevOps/Technology team was responsible for all upgrades, scaling, and troubleshooting of the Hadoop cluster, which was installed on bare EC2 instances.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
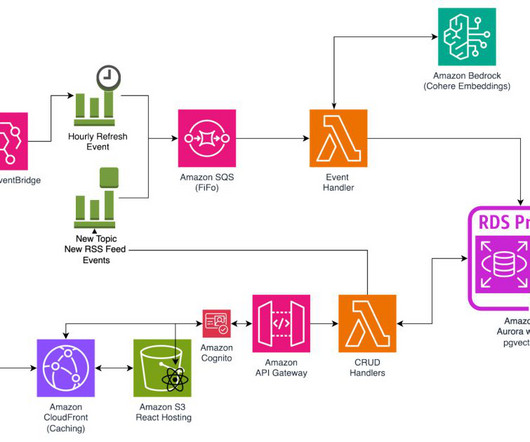
At AWS re:Invent 2024, we announced Amazon Bedrock Knowledge Bases support for natural language querying to retrieve structured data from Amazon Redshift and Amazon SageMaker Lakehouse. Users can interact with Amazon Bedrock Knowledge Bases using the AWS Management Console or an AWS SDK client, which sends natural language queries.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. Choose Create database. aligned identity provider (IdP).
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. You can train foundation models (FMs) for weeks and months without disruption by automatically monitoring and repairing training clusters.
The potential for such large business value is galvanizing tens of thousands of enterprises to build their generative AI applications in AWS. This post addresses these cost considerations so you can optimize your generative AI costs in AWS. Annual costs (directional)*. These costs are based on assumptions.
Managing access control in enterprise machine learning (ML) environments presents significant challenges, particularly when multiple teams share Amazon SageMaker AI resources within a single Amazon Web Services (AWS) account. Refer to the Operating model whitepaper for best practices on account structure.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
Operational complexity – Teams are forced to divert valuable engineering resources toward managing and tuning dedicated vector database clusters. Prerequisites To perform the solution, you need to have these prerequisites: An AWS account with billing enabled. Seamless integration – Works with familiar Amazon S3 APIs and AWS services.
Integration with existing systems on AWS: Lumi seamlessly integrated SageMaker Asynchronous Inference endpoints with their existing loan processing pipeline. Using Databricks on AWS for model training, they built a pipeline to host the model in SageMaker AI, optimizing data flow and results retrieval. Follow him on LinkedIn.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
Prerequisites You should have the following prerequisites: An AWS account A SageMaker notebook instance An S3 bucket to store the input data Process the data To start, upload the log dataset to an S3 bucket in your AWS account. aws ecr get-login --region $region --registry-ids $account_id --no-include-email) !aws client("sts").get_caller_identity().get("Account")
It supports AWS services such as Amazon Simple Storage Service (Amazon S3), Elastic Fabric Adapter (EFA), and Amazon Elastic Kubernetes Service (Amazon EKS), and can be deployed on NVIDIA GPU-accelerated Amazon Elastic Compute Cloud (Amazon EC2) instances, including P6 instances accelerated by NVIDIA Blackwell.
To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities. It’s available as a standalone service on the AWS Management Console , or through APIs. For setup instructions, see Set up an AWS account and create an administrator user.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). To address customers’ requirements about data privacy and sovereignty, SnapLogic deploys the data plane within the customer’s VPC on AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content