This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS’ Legendary Presence at DAIS: Customer Speakers, Featured Breakouts, and Live Demos! Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI.
The analyst can easily pull in the data they need, use natural language to clean up and fill any missing data, and finally build and deploy a machine learning model that can accurately predict the loan status as an output, all without needing to become a machine learning expert to do so. A SageMaker domain. Choose Create stack.
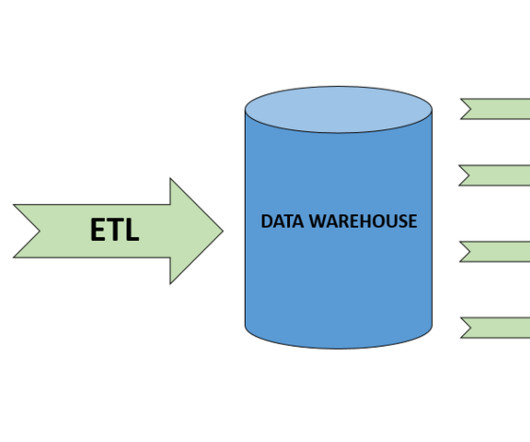
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Figure 1: Agent Bricks auto-optimizes agents for your data and task MLflow 3.0 Agents deployed on AWS, GCP, or even on-premise systems can now be connected to MLflow 3 for agent observability. Now with MLflow 3, you can monitor and observe agents that are deployed anywhere , even outside of Databricks.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Types of data integration methods There are several methods used for data integration, each suited for different scenarios. Extract, Transform, Load (ETL) The ETL process involves extracting data from various sources, transforming it into a suitable format, and loading it into datawarehouses, typically utilizing batch processing.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as businessintelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
Such infrastructure should not only address these issues but also scale according to the demands of AI workloads, thereby enhancing business outcomes. Native integrations with IBM’s data fabric architecture on AWS establish a trusted data foundation, facilitating the acceleration and scaling of AI across the hybrid cloud.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing businessintelligence (BI) tools.
Watsonx.data will allow users to access their data through a single point of entry and run multiple fit-for-purpose query engines across IT environments. Through workload optimization an organization can reduce datawarehouse costs by up to 50 percent by augmenting with this solution. [1]
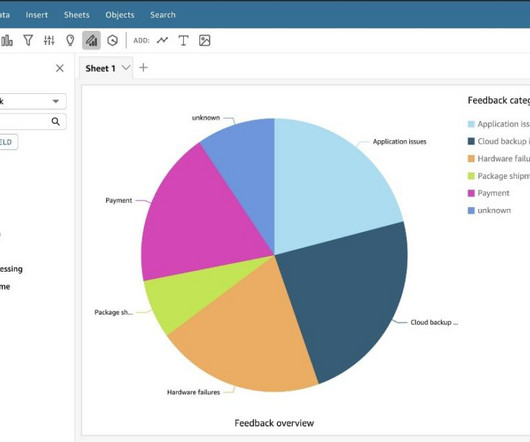
To create and share customer feedback analysis without the need to manage underlying infrastructure, Amazon QuickSight provides a straightforward way to build visualizations, perform one-time analysis, and quickly gain business insights from customer feedback, anytime and on any device. The Step Functions workflow starts.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. Following is a brief overview of each service.
In our recent webcast , IBM, AWS, customers and partners came together for an interactive session. In this session: IBM and AWS discussed the benefits and features of this new fully managed offering spanning availability, security, backups, migration and more. Can data capture for continuous updates still be performed?
Data models help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for businessintelligence. Ensure that data is clean, consistent, and up-to-date.
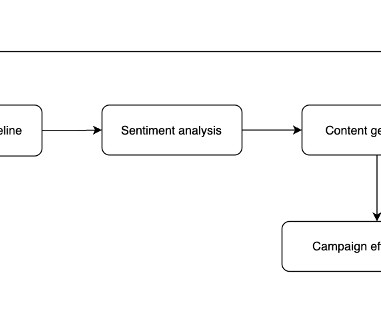
This pattern creates a comprehensive solution that transforms raw social media data into actionable businessintelligence (BI) through advanced AI capabilities. 3B Instruct Amazon Bedrock, the system provides tailored marketing content that adds business value. By integrating LLMs such as Anthropics Claude 3.5
Unfortunately, the current landscape of our consuming systems, especially businessintelligence tools, just wont work withAPIs. He is the founder of Data Futures, a consultancy focused on cloud-native data modernization, and an AWS DataHero.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. SharePoint.
It helps data engineers collect, store, and process streams of records in a fault-tolerant way, making it crucial for building reliable data pipelines. Amazon Redshift Amazon Redshift is a cloud-based datawarehouse that enables fast query execution for large datasets.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses. What are ETL Tools?
Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments. Cut costs by consolidating datawarehouse investments.
Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments. Cut costs by consolidating datawarehouse investments.
In the fast-moving world of data, the Snowflake AI Data Cloud has established itself as an essential part of the Modern Data Stack. Through its versatile platform, organizations can build efficient datawarehouses and harness the power of data monetization via Secure Data Shares, accessible through the Snowflake Marketplace.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
Statistics : A survey by Databricks revealed that 80% of Spark users reported improved performance in their data processing tasks compared to traditional systems. Google Cloud BigQuery Google Cloud BigQuery is a fully-managed enterprise datawarehouse that enables super-fast SQL queries using the processing power of Googles infrastructure.
It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark).
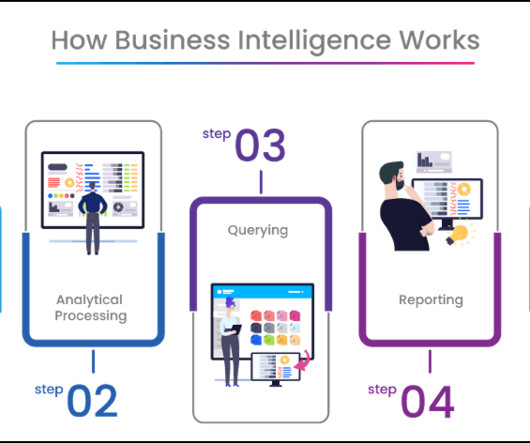
Data platform architecture has an interesting history. Towards the turn of millennium, enterprises started to realize that the reporting and businessintelligence workload required a new solution rather than the transactional applications. A read-optimized platform that can integrate data from multiple applications emerged.
Datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as businessintelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics that enable faster decision making and insights.
Don Haderle, a retired IBM Fellow and considered to be the “father of Db2,” viewed 1988 as a seminal point in its development as D B2 version 2 proved it was viable for online transactional processing (OLTP)—the lifeblood of business computing at the time. Db2 (LUW) was born in 1993, and 2023 marks its 30th anniversary.
This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that data pipelines are efficient, reliable, and capable of handling massive volumes of data in real-time. Each platform offers unique features and benefits, making it vital for data engineers to understand their differences.
Focus Area ETL helps to transform the raw data into a structured format that can be easily available for data scientists to create models and interpret for any data-driven decision. A data pipeline is created with the focus of transferring data from a variety of sources into a datawarehouse.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments. Salesforce Data Cloud for Tableau solves those challenges.
Introduction In the rapidly evolving landscape of data analytics, BusinessIntelligence (BI) tools have become indispensable for organizations seeking to leverage their big data stores for strategic decision-making. Compared to Power BI or Tableau, it has fewer pre-built connectors outside the Google Cloud ecosystem.
How to Optimize Power BI and Snowflake for Advanced Analytics Spencer Baucke May 25, 2023 The world of businessintelligence and data modernization has never been more competitive than it is today. Microsoft Power BI has been the leader in the analytics and businessintelligence platforms category for several years running.
The glossary experience will be fundamentally enhanced by improving the UI and discoverability of glossaries and related business terms. Related data objects, such as tables, businessintelligence, and related terms, can be directly linked for easier discovery and context. Accelerate governance with Stewardship Workbench.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content