This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
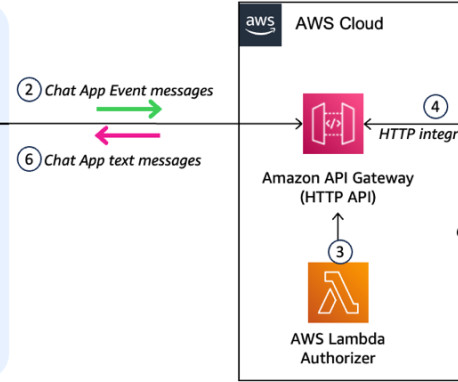
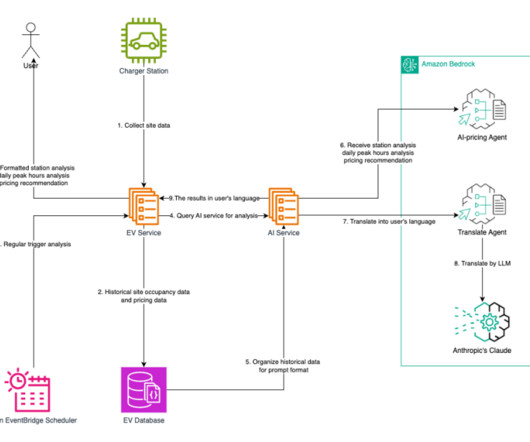
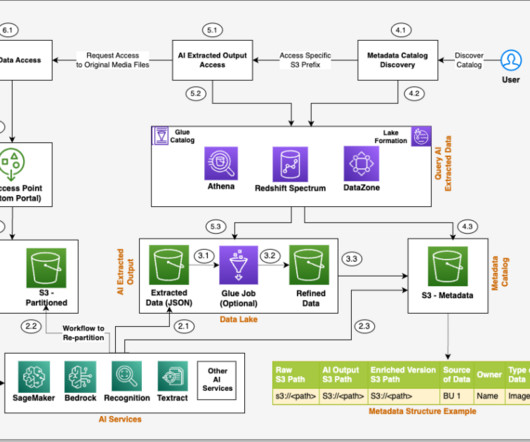
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments. Create dbt models in dbt Cloud.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). aligned identity provider (IdP).
Search solutions in modern bigdata management must facilitate efficient and accurate search of enterprise data assets that can adapt to the arrival of new assets. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context.
Expand to generative AI use cases with your existing AWS and Tecton architecture After you’ve developed ML features using the Tecton and AWS architecture, you can extend your ML work to generative AI use cases. You can also find Tecton at AWS re:Invent. This process is shown in the following diagram.
Summary: BigData refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. These stages are applicable to both use case and model stages.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
With this launch, you can now deploy NVIDIAs optimized reranking and embedding models to build, experiment, and responsibly scale your generative AI ideas on AWS. As part of NVIDIA AI Enterprise available in AWS Marketplace , NIM is a set of user-friendly microservices designed to streamline and accelerate the deployment of generative AI.
Extract, Transform, Load (ETL) The ETL process involves extracting data from various sources, transforming it into a suitable format, and loading it into data warehouses, typically utilizing batch processing. This approach allows organizations to work with large volumes of data efficiently.
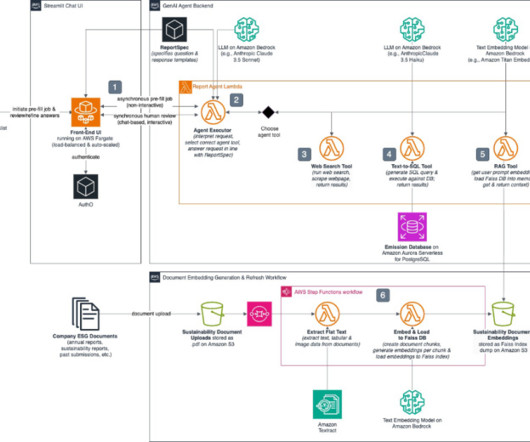
Gardenia Technologies, a data analytics company, partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop Report GenAI , a fully automated ESG reporting solution powered by the latest generative AI models on Amazon Bedrock.
Model cards are an essential component for registered ML models, providing a standardized way to document and communicate key model metadata, including intended use, performance, risks, and business information. The Amazon DataZone project ID is captured in the Documentation section.
Amazon Web Services (AWS) addresses this gap with Amazon SageMaker Canvas , a low-code ML service that simplifies model development and deployment. For a full list of custom model types, check out this documentation. You can also connect SageMaker Canvas to your document repository for information retrieval.
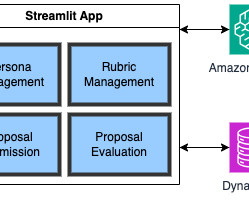
The AWS Social Responsibility & Impact (SRI) team recognized an opportunity to augment this function using generative AI. Historically, AWS Health Equity Initiative applications were reviewed manually by a review committee. Review the provided proposal document: {PROPOSAL} 2. Here are the steps to follow: 1.
More Read 5 Reasons Data-Savvy Accountants Are Becoming Vital to Businesses Here Are The Most Important Ways To Ensure Customer Data Protection Blasphemy? The growing need for bigdata is another. It is helpful to document how you used datasets, what the goal was, and what the model achieved. All Rights Reserved.
With a dramatic increase on supported context length from 128K in Llama 3 , Llama 4 is now suitable for multi-document summarization, parsing extensive user activity for personalized tasks, and reasoning over extensive codebases. Virginia) AWS Region. An AWS Identity and Access Management (IAM) role to access SageMaker AI.
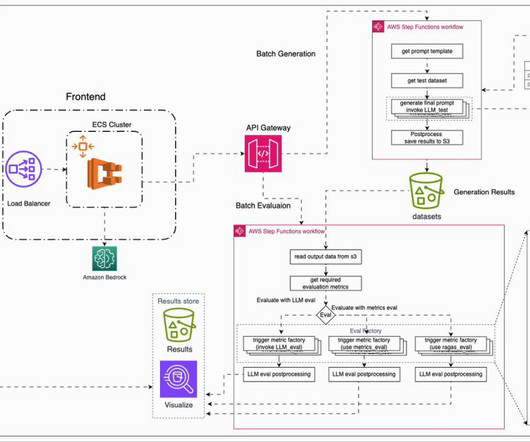
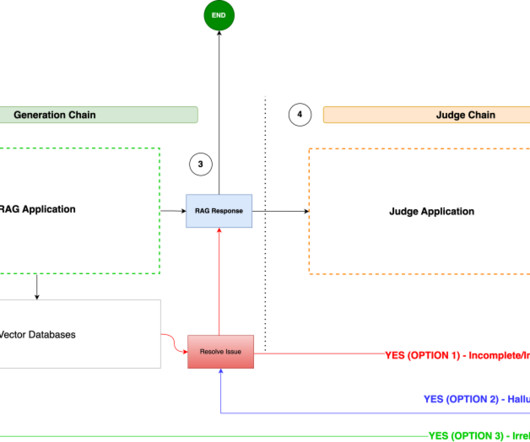
In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. The UI service can be run locally in a Docker container or deployed to AWS Fargate.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
Generative AI brings powerful capabilities to threat modeling, combining natural language processing with visual analysis to simultaneously evaluate system architectures, diagrams, and documentation. The solution is built on a serverless stack, using AWS managed services for automatic scaling, high availability, and cost-efficiency.
The dream is seductive: Autonomous systems that can handle anything you throw at them, no guardrails, no constraints, just give them your AWS credentials and they’ll solve all your problems. A document parsed accurately. Even if an agent is 99% accurate, that’s not always good enough. Or think about customer onboarding. It just runs.
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment.
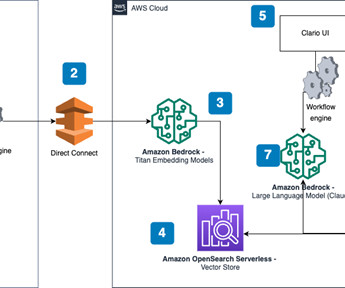
One of the critical challenges Clario faces when supporting its clients is the time-consuming process of generating documentation for clinical trials, which can take weeks. The content of these documents is largely derived from the Charter, with significant reformatting and rephrasing required.
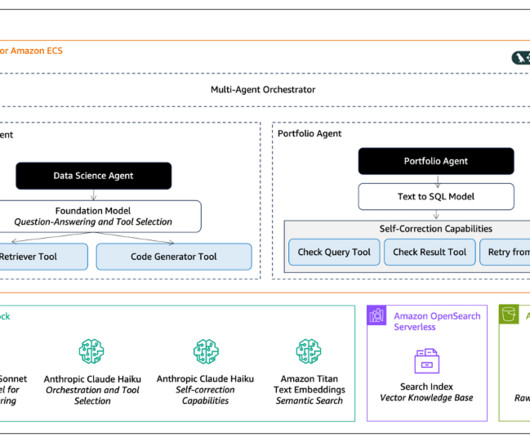
It aims to boost team efficiency by answering complex technical queries across the machine learning operations (MLOps) lifecycle, drawing from a comprehensive knowledge base that includes environment documentation, AI and data science expertise, and Python code generation.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
They are available at no additional charge in AWS Regions where the Amazon Q Business service is offered. Log groups prefixed with /aws/vendedlogs/ will be created automatically. Choose Enable logging to start streaming conversation and feedback data to your logging destination. For more information, see Policy evaluation logic.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigData analytics provides a competitive advantage and drives innovation across various industries.
I've created docker containers from scratch and set up AWS Fargate and all the related services to run them and connect them to a public IP address. Proficient in Python, Java, React, AWS, Snowflake, and distributed systems. Résumé/CV: https://www.dropbox.com/scl/fi/5j9r1z2uaaq7hz50v1kfl/Resume.
In the following section, we dive deep into these steps and the AWS services used. They needed a solution that could support rapid expansion, handle high data volumes, and deliver consistent performance across AWS Regions. About the Authors Ray Wang is a Senior Solutions Architect at AWS.
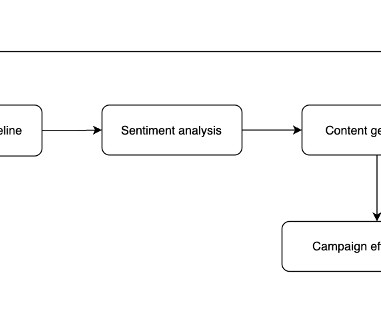
Prerequisites This solution requires you to have an AWS account with the appropriate permissions. The following code is an example using the AWS SDK for Python (Boto3) that prompts the LLM for sentiment analysis: import boto3 import json # Initialize Bedrock Runtime client bedrock = boto3.client('bedrock-runtime')
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. By segment, North America revenue increased 12% Y oY from $316B to $353B, International revenue grew 11% Y oY from$118B to $131B, and AWS revenue increased 13% Y oY from $80B to $91B.
MongoDB MongoDB is a NoSQL database that stores data in flexible, JSON-like documents. It is ideal for handling unstructured or semi-structured data, making it perfect for modern applications that require scalability and fast access. It simplifies data processing by providing an SQL-like interface for querying BigData.
To define the term, let’s first say that structured data includes spreadsheets with their formalized rows and columns, “form-based” data resources where we know the fields in a document and so we know what values to expect… and of course relational databases, the purest form of an ordered and structured data repository.
It extends beyond access to who has permissions to specific resources, such as databases, documents, internal sites, wiki pages, other tools/systems, and other agents. The bottom line for developers is all about keeping the IT stack secure, enabling new agent-to-agent intercourse to happen… and still keep the existing operational lights on.
A growing number of companies are discovering the benefits of investing in bigdata technology. Companies around the world spent over $160 billion on bigdata technology last year and that figure is projected to grow 11% a year for the foreseeable future. Unfortunately, bigdata technology is not without its challenges.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Click here to open the AWS console and follow along. To use one of these models, AWS offers the fully managed service Amazon Bedrock. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
By using AWS services, our architecture provides real-time visibility into LLM behavior and enables teams to quickly identify and address any issues or anomalies. In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda.
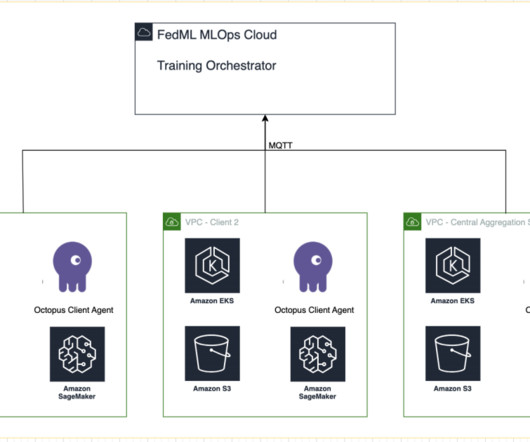
The need for federated learning in healthcare Healthcare relies heavily on distributed data sources to make accurate predictions and assessments about patient care. Limiting the available data sources to protect privacy negatively affects result accuracy and, ultimately, the quality of patient care.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. These include dbt pipelines, data gathering jobs, training, evaluation, and batch inference jobs for smaller models.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As always, AWS welcomes feedback. Before testing, choose the gear icon.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content