This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As the world becomes more interconnected and data-driven, the demand for real-time applications has never been higher. Artificialintelligence (AI) and natural language processing (NLP) technologies are evolving rapidly to manage live data streams.
While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. This article dives into the core functionalities of dbt, exploring its unique strengths and how […] The post Transforming Your DataPipeline with dbt(data build tool) appeared first on Analytics Vidhya.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment?
Google Unveils its Latest AI Model Gemini Google has just introduced Gemini, its anticipated AI model that promises to reshape the landscape of artificialintelligence. Industry, Opinion, Career Advice 7 Data Science & AI Trends That Will Define 2024 2023 was a huge year for artificialintelligence, and 2024 will be even bigger.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Building a deployment pipeline for generative artificialintelligence (AI) applications at scale is a formidable challenge because of the complexities and unique requirements of these systems. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
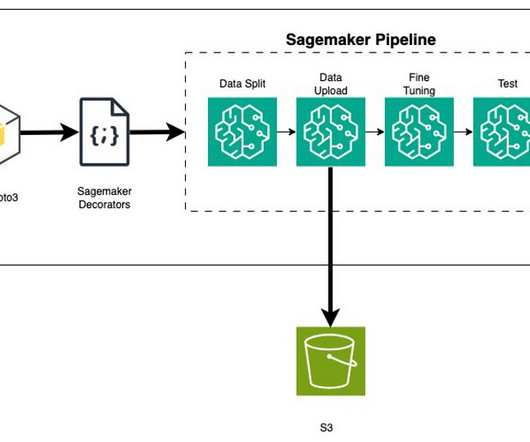
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Knowing some SQL is also essential.
You can easily: Store and process data using S3 and RedShift Create datapipelines with AWS Glue Deploy models through API Gateway Monitor performance with CloudWatch Manage access control with IAM This integrated ecosystem makes it easier to build end-to-end machine learning solutions.
On Wednesday, Peter Norvig, PhD, Engineering Director at Google and Education Fellow at the Stanford Institute for Human-Centered ArtificialIntelligence (HAI) spoke about the human side of AI and how we can focus on using AI for the greater good, improving all stakeholders’ lives and the needs of all users.
Automation Automating datapipelines and models ➡️ 6. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data. The Data Engineer Not everyone working on a data science project is a data scientist.
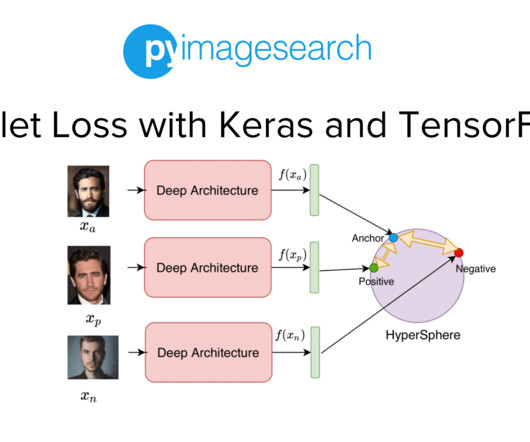
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
With the explosion of big data and advancements in computing power, organizations can now collect, store, and analyze massive amounts of data to gain valuable insights. Machine learning, a subset of artificialintelligence , enables systems to learn and improve from data without being explicitly programmed.
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. Output is a fully self-contained HTML application. You can watch it on demand here.
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
The field of artificialintelligence is growing rapidly and with it the demand for professionals who have tangible experience in AI and AI-powered tools. Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processing data. billion in 2021 to $331.2 billion by 2026.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage.
With AI credits, teams can streamline the annotation process using intelligent suggestions and quality control mechanisms. Confluent Confluent provides a robust data streaming platform built around Apache Kafka. Modal Modal offers serverless compute tailored for data-intensive workloads.
This doesn’t mean anything too complicated, but could range from basic Excel work to more advanced reporting to be used for data visualization later on. Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Purina used artificialintelligence (AI) and machine learning (ML) to automate animal breed detection at scale. Deployment with the AWS CDK The Step Functions state machine and associated infrastructure (including Lambda functions, CodeBuild projects, and Systems Manager parameters) are deployed with the AWS CDK using Python.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code.
Prime_otter_86438 is working on a Python library to make ML training and running models on any microcontroller in real time for classification easy for beginners. They are seeking assistance from an expert to improve the model and make the Python package easier for the end user. If this sounds fun, connect with them in the thread!
This field is often referred to as explainable artificialintelligence (XAI). Amazon SageMaker Clarify is a feature of Amazon SageMaker that enables data scientists and ML engineers to explain the predictions of their ML models. Solution overview SageMaker algorithms have fixed input and output data formats.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
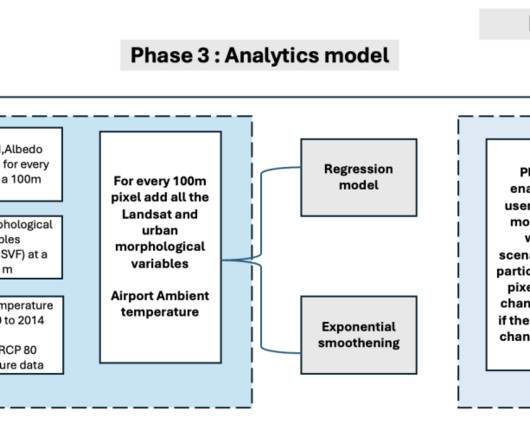
Phase 1: Datapipeline The Landsat 8 satellite captures detailed imagery of the area of interest every 15 days at 11:30 AM, providing a comprehensive view of the city’s landscape and environment. Data acquisition and preprocessing To implement the modules, Gramener used the SageMaker geospatial notebook within Amazon SageMaker Studio.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. Sandeep holds an MSc.
This blog will cover creating customized nodes in Coalesce, what new advanced features can already be used as nodes, and how to create them as part of your datapipeline. They’re essentially an entire datapipeline within itself. Snowflake even handles the orchestration and scheduling of the refresh.
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. And that’s exactly what I do.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
Python When it comes to a powerful and versatile programming language, Python takes the lead. Python , with libraries such as NumPy, Pandas, and SciPy, is increasingly used for statistical analysis. Its versatility allows integration with web applications and datapipelines, making it a favourite among data scientists.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? What Is Keras Core?
The salary of an ArtificialIntelligence Architect in India ranges between ₹ 18.0 An AI Architect is a skilled professional responsible for designing and implementing artificialintelligence solutions within an organization. from 2023 to 2030. Lakhs to ₹ 56.7 Their average annual salary is ₹ 31.8 Who is an AI Architect?
SageMaker pipeline SageMaker Pipelines offers a user-friendly Python SDK to create integrated machine learning (ML) workflows. Our endpoint provides a single-step forecast for the provided time series data, presented as percentiles and the median, as shown in the following figure and table.
Celebrating ODSCs 10-year milestone, McGovern delved into industry trends, in-demand skills, and emerging roles shaping the field of artificialintelligence as we approach2025. LLM Engineers: With job postings far exceeding the current talent pool, this role has become one of the hottest inAI.
Although data scientists rightfully capture the spotlight, future-focused teams also include engineers building datapipelines, visualization experts, and project managers who integrate efforts across groups. Selecting Technologies The technology landscape enables advanced analytics and artificialintelligence to evolve quickly.
Machine learning (ML), a subset of artificialintelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
Implementing Precision and Recall Calculations in Python Now that we have defined and segregated our samples into True Positives , True Negatives , False Positives , and False Negatives , let us try to use them to compute specific metrics to evaluate our model. label_pred !=1 1 ), and their ground-truth label was positive ( label_gt =1 ).
Monday, May 12thAI Bootcamp Day (VirtualOnly) The sessions, conducted entirely online, will focus on core data science topics, including Python programming, machine learning basics, statistical analysis, AI Agents, and everything needed to excel as an AI engineer.
JuMa is a service of BMW Group’s AI platform for its data analysts, ML engineers, and data scientists that provides a user-friendly workspace with an integrated development environment (IDE). It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R.
The effect is that you get to use your favorite pandas API, but your datapipelines run on one of the most battle-tested and heavily-optimized data infrastructures today — databases. You can start running your Pythondata workflows in your data warehouse today by signing up here !
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content