This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
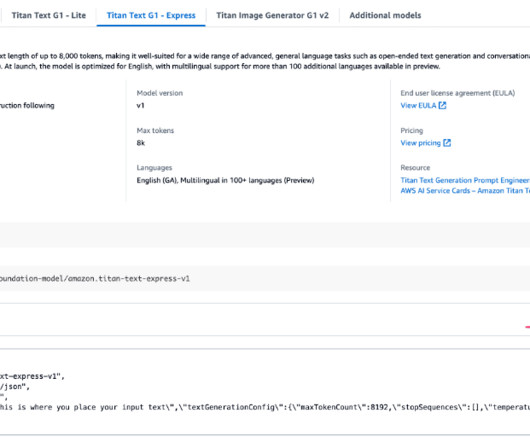
The rise of large language models (LLMs) and foundation models (FMs) has revolutionized the field of natural language processing (NLP) and artificialintelligence (AI). These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks.
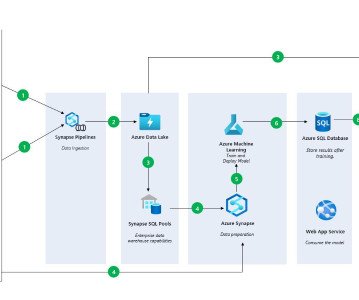
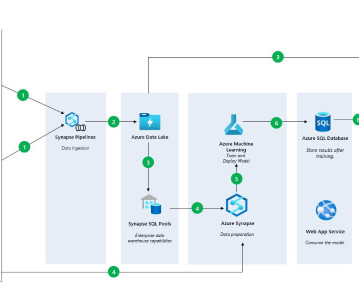
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
To get the data, you will need to follow the instructions in the article: Create a Data Solution on Azure Synapse Analytics with Snapshot Serengeti — Part 1 — Microsoft Community Hub, where you will load data into Azure DataLake via Azure Synapse. Lastly, upload the data from Azure Subscription.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificialintelligence and machine learning to unify and securely manage disparate data sources without migrating them to a centralized location.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificialintelligence and machine learning to unify and securely manage disparate data sources without migrating them to a centralized location.
A data fabric is an emerging data management design that allows companies to seamlessly access, integrate, model, analyze, and provision data. Monitor data sources according to policies you customize to help users know if fresh, quality data is ready for use. Datamodeling. Data preparation.
A data fabric is an emerging data management design that allows companies to seamlessly access, integrate, model, analyze, and provision data. Monitor data sources according to policies you customize to help users know if fresh, quality data is ready for use. Datamodeling. Data preparation.
Apache HBase was employed to offer real-time key-based access to data. Model training and scoring was performed either from Jupyter notebooks or through jobs scheduled by Apaches Oozie orchestration tool, which was part of the Hadoop implementation. HBase is employed to offer real-time key-based access to data.
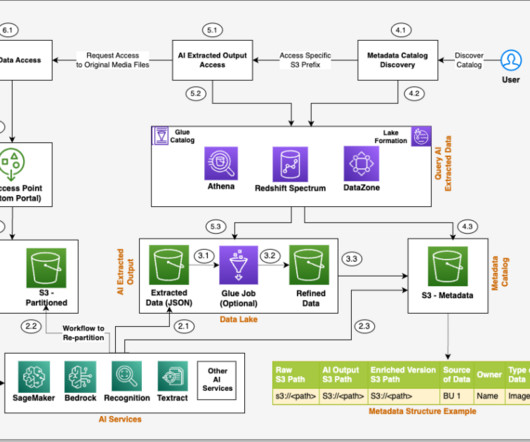
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
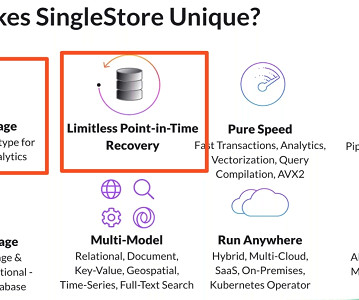
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how datamodels and algorithms rely on powerful and versatile data infrastructure.
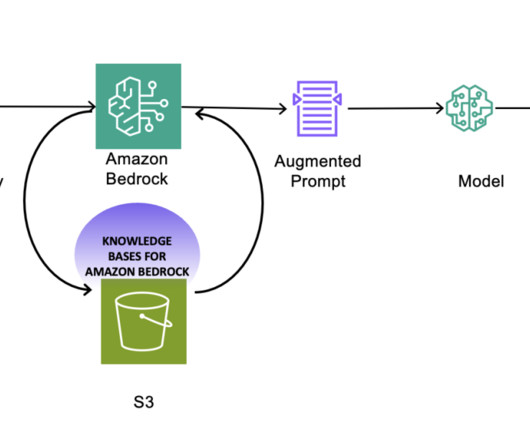
Artificialintelligence (AI) adoption is still in its early stages. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Businesses must feel confident in the predictions and content that large foundation model providers generate.
This means that individuals can ask companies to erase their personal data from their systems and from the systems of any third parties with whom the data was shared. Krishna Prasad is a Senior Solutions Architect in Strategic Accounts Solutions Architecture team at AWS.
AI is quickly scaling through dozens of industries as companies, non-profits, and governments are discovering the power of artificialintelligence. Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. So, what are you waiting for?
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. No-code/low-code experience using a diagram view in the data preparation layer similar to Dataflows.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machine learning. Many find themselves swamped by the volume and complexity of unstructured data.
Dimensional DataModeling in the Modern Era Dustin Dorsey |Principal Data Architect |Onix With the emergence of big data, cloud computing, and AI-driven analytics, many wonder if the traditional principles of dimensional modeling still hold value. This session provides a gentle introduction to vector databases.
Self-Service Analytics User-friendly interfaces and self-service analytics tools empower business users to explore data independently without relying on IT departments. This might involve data validation rules, data cleansing procedures, and ongoing monitoring to maintain data integrity.
You’ll own and work with everything from distributed queues and datalakes to prompt evaluation and agentic orchestration. Whether it’s about leveraging LLMs to improve customer support, building datalakes on cloud platforms to improve storage or implementing models using sensor data for quality control.
The advantages can be summed up as follows: Forced normalization and enrichment – In Open XDR, the system ensures that all data are similar or compatible with each other (normalized) before they are stored in a datalake. If the data is incomplete, additional information is sourced and appended (enrichment).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content