This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. A Ray cluster consists of a single head node and a number of connected worker nodes. Ray clusters and Kubernetes clusters pair well together.
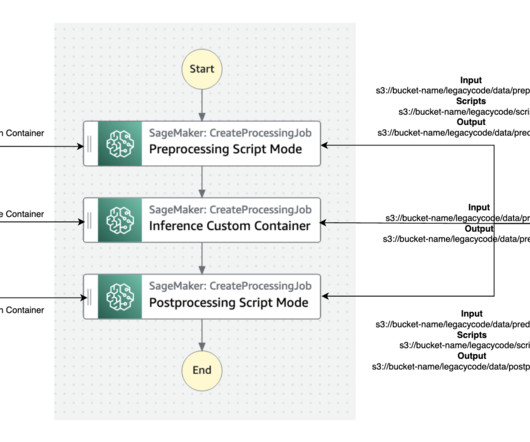
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. This type of data is often used in ML and artificialintelligence applications. Delete the MongoDB Atlas cluster. Solution overview The following diagram illustrates the solution architecture.
ArtificialIntelligence (AI) is all the rage, and rightly so. And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts. Its time to maximize the potential of your artificialintelligence (AI) initiatives.
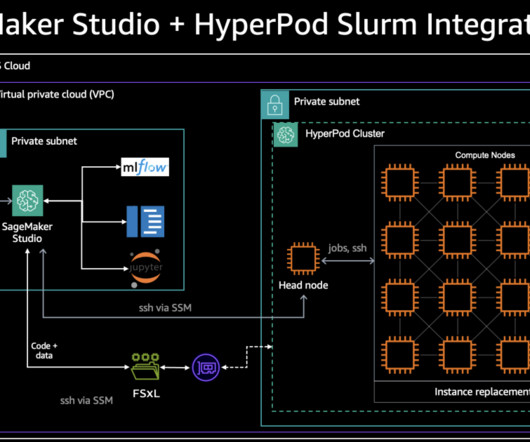
These services support single GPU to HyperPods (cluster of GPUs) for training and include built-in FMOps tools for tracking, debugging, and deployment. Task definition (count_task) This is a task that we want this agent to execute. This agent is equipped with a tool called BlocksCounterTool.
Summary: This guide explores ArtificialIntelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. It equips you to build and deploy intelligent systems confidently and efficiently.
Summary: This article compares ArtificialIntelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. While AI aims to replicate human intelligence across various domains, ML focuses on learning from data to improve performance. What is ArtificialIntelligence?
Deep learning is transforming the landscape of artificialintelligence (AI) by mimicking the way humans learn and interpret complex data. Deep learning is a subset of artificialintelligence that utilizes neural networks to process complex data and generate predictions. What is deep learning?
Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificialintelligence. Common types include: K-means clustering: Groups similar data points together based on specific metrics. What are machine learning algorithms?
Machine teaching is redefining how we interact with artificialintelligence (AI) and machine learning (ML). Definition of machine teaching At its core, machine teaching involves the interaction between human experts and AI systems, where the former provides context-specific knowledge to optimize the training process.
Definition and purpose of personalization engines Personalization engines enhance e-commerce by providing customized user experiences that allow businesses to cater to individual customer needs. Role of artificialintelligence in personalization engines AI plays a fundamental role in enhancing the capabilities of personalization engines.
Foundation Models (FMs) demand distributed training clusters — coordinated groups of accelerated compute instances , using frameworks like PyTorch — to parallelize workloads across hundreds of accelerators (like AWS Trainium and AWS Inferentia chips or NVIDIA GPUs). The likelihood of these failures increases with the size of the cluster.
This technique plays a crucial role in various applications, from image recognition to financial forecasting, showcasing its significance in the era of artificialintelligence. Definition of supervised learning At its core, supervised learning utilizes labeled data to inform a machine learning model. What is supervised learning?
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
The Mac Studio M3 Ultra may not sit in everyones home office its a $9,499 device and definitely high-end. Contemporary models of comparable size typically demand far larger GPU clusters chewing through power in dedicated data centers. Models like DeepSeek-V3-0324 are engineered to excel even without top-tier GPU clusters.
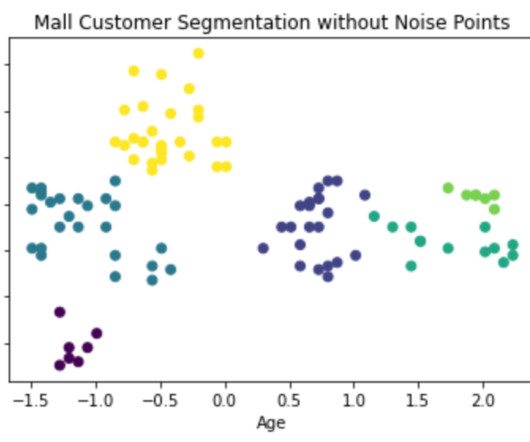
How Clustering Can Help You Understand Your Customers Better Customer segmentation is crucial for businesses to better understand their customers, target marketing efforts, and improve satisfaction. Clustering, a popular machine learning technique, identifies patterns in large datasets to group similar customers and gain insights.
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Machine Learning Operations (MLOps): Overview, Definition, and Architecture (by Kreuzberger, et al., AIIA MLOps blueprints.
Underpinning most artificialintelligence (AI) deep learning is a subset of machine learning that uses multi-layered neural networks to simulate the complex decision-making power of the human brain. FPGA programming and reprogramming can potentially delay deployments.
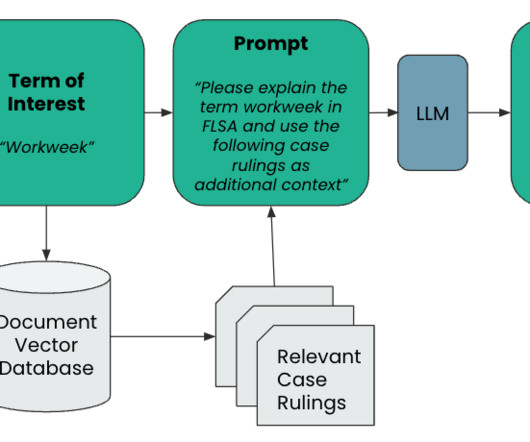
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. The following figure shows schema definition and model which reference it. For more information, see Zeta Global’s home page.
Amazon ECS configuration For Amazon ECS, create a task definition that references your custom Docker image. dkr.ecr.amazonaws.com/ : ", "essential": true, "name": "training-container", } ] } This definition sets up a task with the necessary configuration to run your containerized application in Amazon ECS. Delete your ECS cluster.
Let us now look at the key differences starting with their definitions and the type of data they use. Definition of Supervised Learning and Unsupervised Learning Supervised learning is a process where an ML model is trained using labeled data. In this case, every data point has both input and output values already defined.
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificialintelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications.
Compute Resources : Azure ML provides scalable compute options like training clusters, inference clusters, and compute instances that can be automatically scaled based on workload demands. Implement Auto-scaling : Configure compute clusters to scale down or shut down when not in use. Awesome, right? Ready to dive deeper?
An EMR cluster with EMR runtime roles enabled. Associating runtime roles with EMR clusters is supported in Amazon EMR 6.9. The EMR cluster should be created with encryption in transit. internal in the certificate subject definition. If your cluster resides in us-west-2 , you could specify CN=*.us-west-2.compute.internal.
Connection definition JSON file When connecting to different data sources in AWS Glue, you must first create a JSON file that defines the connection properties—referred to as the connection definition file. The following is a sample connection definition JSON for Snowflake.
Electronic design automation (EDA) is a market segment consisting of software, hardware and services with the goal of assisting in the definition, planning, design, implementation, verification and subsequent manufacturing of semiconductor devices (or chips). The primary providers of this service are semiconductor foundries or fabs.
__version__ Let's try clustering a sample dataset and compare the runtime of clustering functions by running it with CPU and then with GPU. host_data = device_data.get() host_labels = device_labels.get() Running KMeans clustering on CPU. . Hope you will definitely give it a try. Import the packages. The CPU took 5.15
I know similarities languages are not the sole and definite barometers of effectiveness in learning foreign languages. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them. this might be natural as clusters of data can be estimated with unsupervised learning.
The process of statistical modelling involves the following steps: Problem Definition: Here, you clearly define the research question first that you want to address using statistical modeling. This could be linear regression, logistic regression, clustering , time series analysis , etc.
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
Cluster resources are provisioned for the duration of your job, and cleaned up when a job is complete. You can edit the Step Functions definition directly by using the States Language. Shyam Namavaram is a senior artificialintelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS).
Introduction Data Science and ArtificialIntelligence (AI) are at the forefront of technological innovation, fundamentally transforming industries and everyday life. What is Data Science and ArtificialIntelligence? The impact is profound and far-reaching.
Machine learning, a subset of artificialintelligence , enables systems to learn and improve from data without being explicitly programmed. With the explosion of big data and advancements in computing power, organizations can now collect, store, and analyze massive amounts of data to gain valuable insights.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificialintelligence (ML/AI) system and reliably improve it over time. You can use artifacts to manage configuration, so everything from hyperparameters to cluster sizing can be managed in a single file, tracked alongside the results.
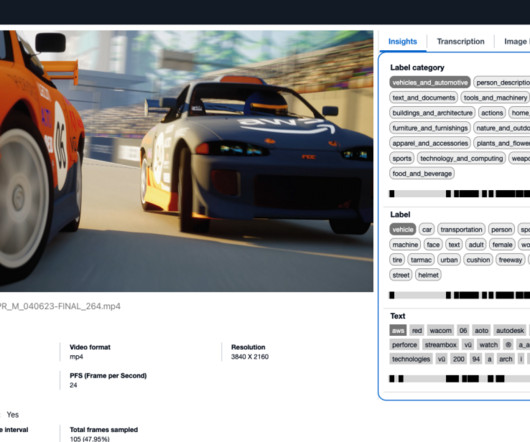
Generative artificialintelligence (AI) has unlocked fresh opportunities for these use cases. An Amazon OpenSearch Service cluster stores the extracted video metadata and facilitates users’ search and discovery needs. Therefore, you don’t even need to include the taxonomy definitions as part of the LLM prompt.
Points clustered closely on the y-axis indicate similar ground conditions; sudden and persistent discontinuities in the embedding values signal significant change. While this method performs well in our analyses, it is also quite rigid in that it requires a careful tuning of error thresholds and the definition of a baseline period.
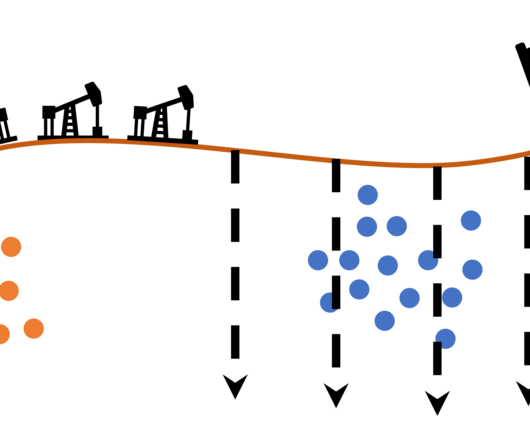
And finally, some activities, such as those involved with the latest advances in artificialintelligence (AI), are simply not practically possible, without hardware acceleration. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
The pace of development in artificialintelligence (AI) has become an all-out sprint, with breakthroughs being released on almost a daily basis. Understanding Retrieval Augmented Generation (RAG) Generative ArtificialIntelligence ( Gen AI) has witnessed significant advancements, including the rise of large language models (LLMs).
Central limit theorem The basic definition of the central limit theorem can be stated as, “The sums or averages of a large number of independent and identically distributed random variables will be approximately normally distributed, regardless of the underlying distribution of the individual random variables.”
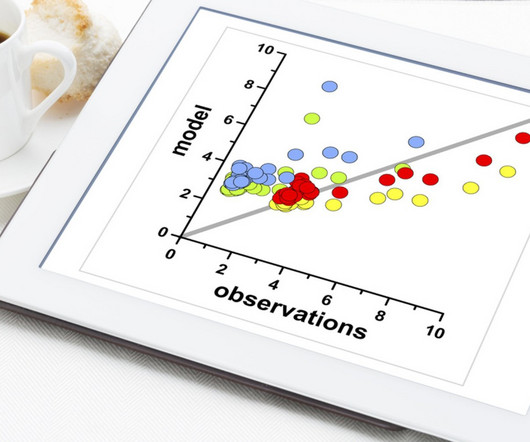
ClusteringClustering is a class of algorithms that segregates the data into a set of definiteclusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g., Figure 9: K -means clustering algorithm (source: Javatpoint ).
I realized that the algorithm assumes that we like a particular genre and artist and groups us into these clusters, not letting us discover and experience new music. It gives us this final result: Conclusion The app definitely isn’t perfect. While scrolling through my recommended playlist.
This step-function instantiated a cluster of instances to extract and process data from S3 and the further steps of pre-processing, training, evaluation would run on a single large EC2 instance. For each training job run, we generate four different models to Amazon S3 based on our custom business definition. cpu-py39-ubuntu20.04-sagemaker",
Unsupervised Learning: Evaluating Clusters 25 Excellent Machine Learning OpenDatasets Want to become the next writer to get thousands of views on an article? Even non-AI practitioners are talking about GenAI, ChatGPT, and image generatorsdiscussions that definitely werent a thing just a few yearsago.
If you’re training one model, you’re probably training a dozen — hyperparameter optimization, multi-user clusters, & iterative exploration all motivate multi-model training, blowing up compute demands further still. Increasing the size of our models has definitely boosted our accuracy. Why train large models?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content