This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
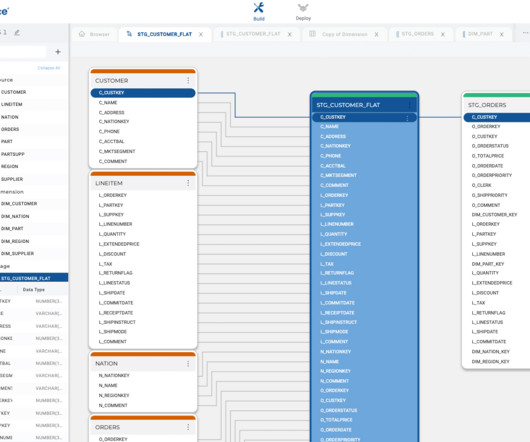
In this article, we will discuss use cases and methods for using ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes along with SQL to integrate data from various sources.
This article was published as a part of the Data Science Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and data integration service which allows you to create a data-driven workflow. In this article, I’ll show […]. In this article, I’ll show […].
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
AI Functions in SQL: Now Faster and Multi-Modal AI Functions enable users to easily access the power of generative AI directly from within SQL. Figure 3: Document intelligence arrives at Databricks with the introduction of ai_parse in SQL.
REGISTER Login Try Databricks Blog / Announcements / Article What Is a Lakebase? It eliminates fragile ETL pipelines and complex infrastructure, enabling teams to move faster and deliver intelligent applications on a unified data platform In this blog, we propose a new architecture for OLTP databases called a lakebase.
This article was published as a part of the Data Science Blogathon. This requires developing a lot of ETL jobs and transforming the data to guarantee a consistent structure for making it available at any next step in the […].
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
Structured query language (SQL) is one of the most popular programming languages, with nearly 52% of programmers using it in their work. SQL has outlasted many other programming languages due to its stability and reliability.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Introduction The ETL process is crucial in modern data management. What is ETL? ETL stands for Extract, Transform, Load.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Data engineers can create and manage extract, transform, and load (ETL) pipelines directly within Unified Studio using Visual ETL. It also supports unified access across different compute runtimes such as Amazon Redshift and Athena for SQL, Amazon EMR Serverless , Amazon EMR on EC2, and AWS Glue for Spark.
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provides a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. What is Matillion ETL?
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provide a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. If they are not, the query can be stopped.
Summary: This article highlights the primary differences between JDBC and ODBC and their unique applications and use cases. This article clarifies the key distinctions between these two database connectivity options, helping readers choose the most suitable one for their projects. In 2022, the global ODBC market was valued at $1.2
The processes of SQL, Python scripts, and web scraping libraries such as BeautifulSoup or Scrapy are used for carrying out the data collection. Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for data preparation before analysis. How to Choose the Right Data Science Career Path?
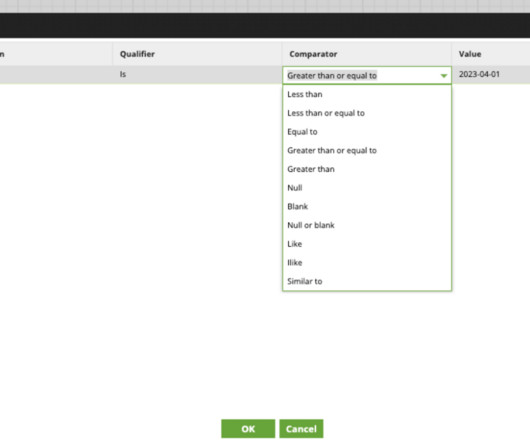
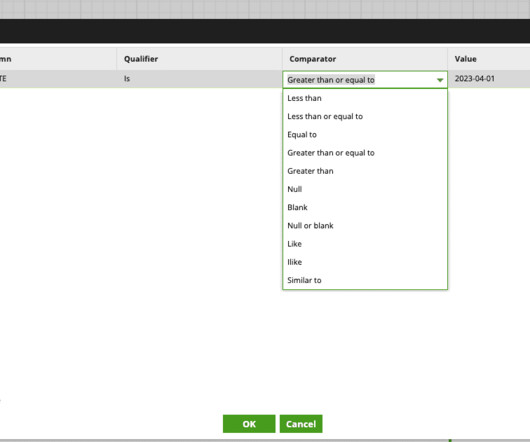
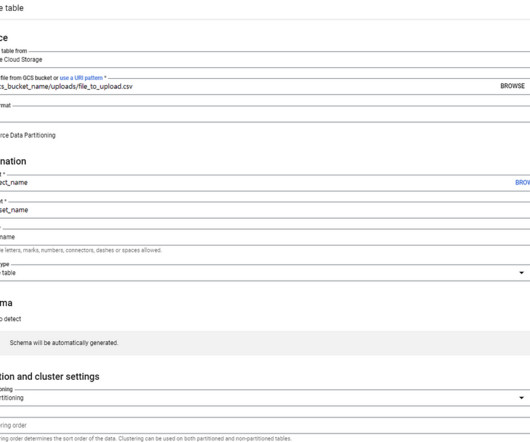
So if you are familiar with the Standard SQL queries, you are good to go!! The sample data used in this article can be downloaded from the link below, Fruit and Vegetable Prices How much do fruits and vegetables cost? Create a Glue Job to perform ETL operations on your data. For this article, we will run the job on demand.
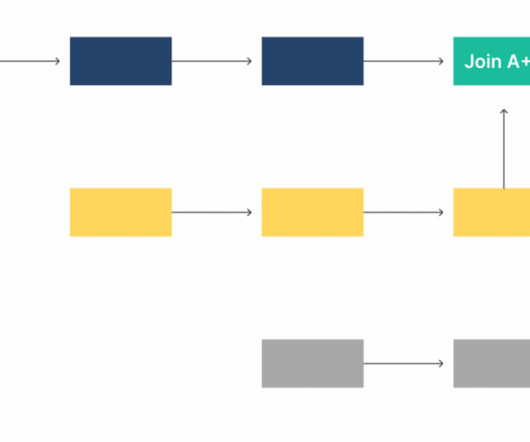
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud data warehouse like Snowflake. Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code.
This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling. Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts.
From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. Implementing these practices can enhance the efficiency and consistency of ETL workflows.
In this article, we will delve into the concept of data lakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Data warehouses use a “schema-on-write” approach. You can connect with her on Linkedin.
Putting the T for Transformation in ELT (ETL) is essential to any data pipeline. They let you create virtual tables from the results of an SQL query. Stored Procedures In any data warehousing solution, stored procedures encapsulate SQL logic into repeatable routines, but Snowflake has some tricks up its sleeve.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
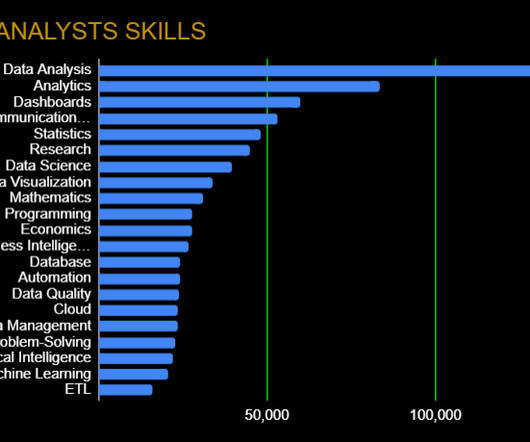
Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential. SQL excels with big data and statistics, making it important in order to query databases.
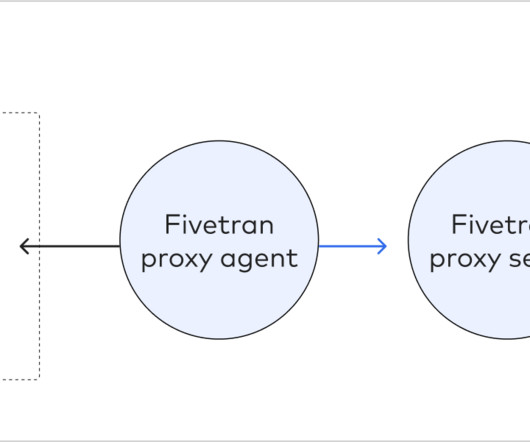
Some of the databases supported by Fivetran are: Snowflake Data Cloud (BETA) MySQL PostgreSQL SAP ERP SQL Server Oracle In this blog, we will review how to pull Data from on-premise Systems using Fivetran to a specific target or destination. HVA also allows the capture of changes directly from various DBMS articles.
These areas may include SQL, database design, data warehousing, distributed systems, cloud platforms (AWS, Azure, GCP), and data pipelines. ETL (Extract, Transform, Load) This is a core data engineering process for moving data from one or more sources to a destination, typically a data warehouse or data lake. First, articles.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. Now let’s get into the main topic of the article. For the part 1 of this article, I wanted to cover Tables, Views, Stored Procedures, and Materialized Views.
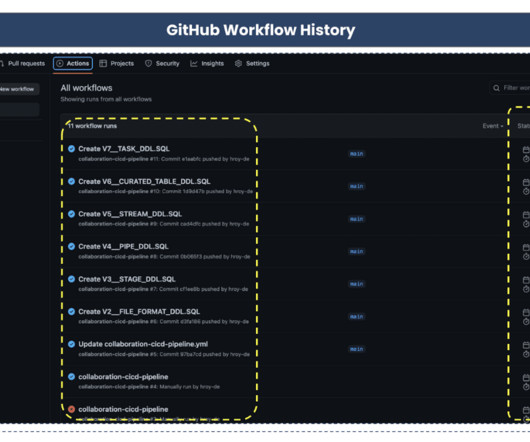
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. In this article, we’ll talk about Jupyter notebooks specifically from a business and product point of view. There are several ways to use SQl wit Jupyter notebooks. documentation.
In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. Reverse ETL tools. The modern data stack is also the consequence of a shift in analysis workflow, fromextract, transform, load (ETL) to extract, load, transform (ELT). A Note on the Shift from ETL to ELT.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. This article explores Spark vs. Hadoop, focusing on their strengths, weaknesses, and use cases. Spark SQL Spark SQL is a module that works with structured and semi-structured data.
Enables users to trigger their custom transformations via SQL and dbt. Talend Overview While Talend’s Open Studio for Data Integration is free-to-download software to start a basic data integration or an ETL project, it also comes powered with more advanced features which come with a price tag. Uses secure protocols for data security.
It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques. This article aims to guide you through the intricacies of Data Analyst interviews, offering valuable insights with a comprehensive list of top questions. How do you join tables in SQL?
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity.
In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. Related article How to Build ETL Data Pipelines for ML See also MLOps and FTI pipelines testing Once you have built an ML system, you have to operate, maintain, and update it.
This article was co-written by Lynda Chao & Tess Newkold With the growing interest in AI-powered analytics, ThoughtSpot stands out as a leader among legacy BI solutions known for its self-service search-driven analytics capabilities. Suppose your business requires more robust capabilities across your technology stack. Why Use ThoughtSpot?
In this Importing Data in Python Cheat Sheet article, we will explore the essential techniques and libraries that will make data import a breeze. Importing from SQL databases Python has excellent support for interacting with databases. In pandas, we can import data from various file formats like JSON, SQL, Microsoft Excel, etc.
In this article, we will explore the importance of BI in today’s business landscape, the skills and qualifications needed for a career in BI, and the opportunities available in this growing field. A career path in BI can be a lucrative and rewarding choice for those with interest in data analysis and problem-solving.
In this article, we will explore the importance of BI in today’s business landscape, the skills and qualifications needed for a career in BI, and the opportunities available in this growing field. A career path in BI can be a lucrative and rewarding choice for those with interest in data analysis and problem-solving.
Over the past decade, we’ve seen Apache Spark evolve from a powerful general-purpose compute engine into a critical layer of the Open Lakehouse Architecture - with Spark SQL, Structured Streaming, open table formats, and unified governance serving as pillars for modern data platforms. Join now Ready to get started?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content