This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
as described via the relevant Wikipedia article here: [link] ) and other factors, the digital age will keep producing hardware and software tools that are both wondrous, and/or overwhelming (e.g., For instance, in the table below, we juxtapose four authors’ professional opinions with DS-Dojo’s curriculum. IoT, Web 3.0,
Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations. This article delves into the essential components of data mining, highlighting its processes, techniques, tools, and applications. What is data mining?
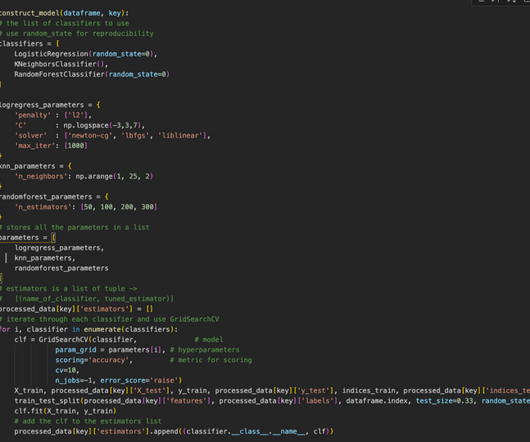
We shall look at various types of machine learning algorithms such as decisiontrees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. R Studios and GIS In a previous article, I wrote about GIS and R., DecisionTree and R.
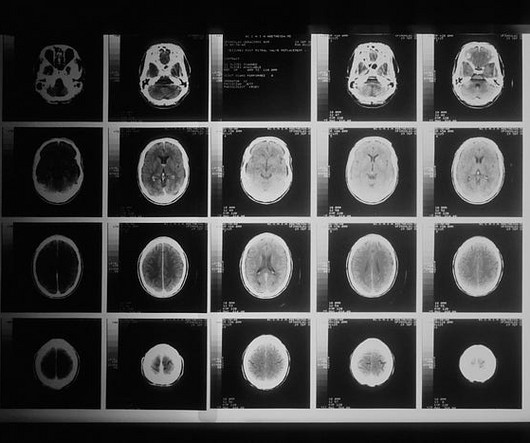
Photo by National Cancer Institute on Unsplash This article delves into medical image analysis, specifically focusing on the classification of brain tumors. The three weak learner models used for this implementation were k-nearestneighbors, decisiontrees, and naive Bayes.
Hopefully, this article will serve as a roadmap for leveraging the power of R, a versatile programming language, for spatial analysis, data science and visualization within GIS contexts. R, GIS and Machine learning I have written about the amazing wonders of R for GIS in my previous articles, but I will sum it up.
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. DecisionTrees AI This AI methodology is not only easy to understand but also quite effective.
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. DecisionTrees AI This AI methodology is not only easy to understand but also quite effective.
This article will explain the concept of hyperparameter tuning and the different methods that are used to perform this tuning, and their implementation using python Photo by Denisse Leon on Unsplash Table of Content Model Parameters Vs Model Hyperparameters What is hyperparameter tuning?
The prediction is then done using a k-nearestneighbor method within the embedding space. Distance preserving embeddings: The name of this method is straightforward. The embedding space is generated by preserving the distances between the labels.
In this article, we will delve into the differences and characteristics of these two methods, shedding light on their unique advantages and use cases. Random Forest : Random Forest is an ensemble learning method that combines multiple DecisionTrees to improve prediction accuracy and reduce overfitting.
In this article, we will discuss some of the factors to consider while selecting a classification & Regression machine learning algorithm based on the characteristics of the data. For example, if you have binary or categorical data, you may want to consider using algorithms such as Logistic Regression, DecisionTrees, or Random Forests.
In this article, I will cover all of them. Simple linear regression Multiple linear regression Polynomial regression DecisionTree regression Support Vector regression Random Forest regression Classification is a technique to predict a category. It’s a fantastic world, trust me!
In this article, I will provide my top five reasons for using the Seaborn library to create data visualizations with Python. Originally posted on OpenDataScience.com Read more data science articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels! Not a bad list right?
The article also addresses challenges like data quality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. For example, linear regression is typically used to predict continuous variables, while decisiontrees are great for classification and regression tasks.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success.
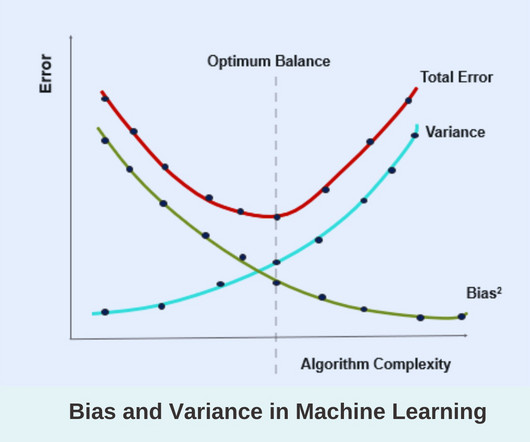
Here are some examples of variance in machine learning: Overfitting in DecisionTreesDecisiontrees can exhibit high variance if they are allowed to grow too deep, capturing noise and outliers in the training data.
Some important things that were considered during these selections were: Random Forest : The ultimate feature importance in a Random forest is the average of all decisiontree feature importance. A random forest is an ensemble classifier that makes predictions using a variety of decisiontrees.
In this article, we will explore some common data science interview questions that will help you prepare and increase your chances of success. Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc. Variance: Variance is also a kind of error.
In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? index.add(xb) # xq are query vectors, for which we need to search in xb to find the knearestneighbors. #
They are: Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decisiontrees, or k-nearestneighbors (kNN). Relies on explicit decision boundaries or feature representations for sample selection. different architectures or initializations).
Dealing with imbalanced data is pretty common in the real-world and these articles by German Lahera and on DataCamp are good places to learn about them. Feel free to try other algorithms such as Random Forests, DecisionTrees, Neural Networks, etc., among supervised models and k-nearestneighbors, DBSCAN, etc.,
The figure below shows the byte distribution of some file types: Please note that all codes and input/output data examples in this article are derived from Clarity Consultings MigNon tool. Overfitting can occur when the model uses too many features, causing it to make decisions faster, for example, at the endpoints of decisiontrees.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content