This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century.
Instead of writing the same cleaning code repeatedly, a well-designed pipeline saves time and ensures consistency across your data science projects. In this article, well build a reusable data cleaning and validation pipeline that handles common data quality issues while providing detailed feedback about what was fixed.
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
Introduction Managing a datapipeline, such as transferring data from CSV to PostgreSQL, is like orchestrating a well-timed process where each step relies on the previous one. Apache Airflow streamlines this process by automating the workflow, making it easy to manage complex data tasks.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. Use Amazon Athena SQL queries to provide insights. Use order dates and news article publishing dates as you look for trends.
Real-time data streaming pipelines play a crutial role in achieving this objective. Within this article, we will explore the significance of these pipelines and utilise robust tools such as Apache Kafka and Spark to manage vast streams of data efficiently. Next, we run an SQL query to extract the data.
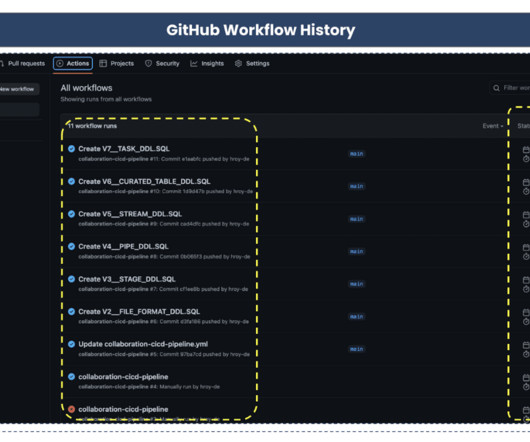
which play a crucial role in building end-to-end datapipelines, to be included in your CI/CD pipelines. Each migration SQL script is assigned a unique sequence number to facilitate the correct order of application. Additionally, we need to incorporate Flyway variables into the Flyway configuration file.
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provides a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. If they are not, the query can be stopped.
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provide a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. If they are not, the query can be stopped.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Knowing some SQL is also essential.
While machine learning frameworks and platforms like PyTorch, TensorFlow, and scikit-learn can perform data exploration well, it’s not their primary intent. There are also plenty of data visualization libraries available that can handle exploration like Plotly, matplotlib, D3, Apache ECharts, Bokeh, etc.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
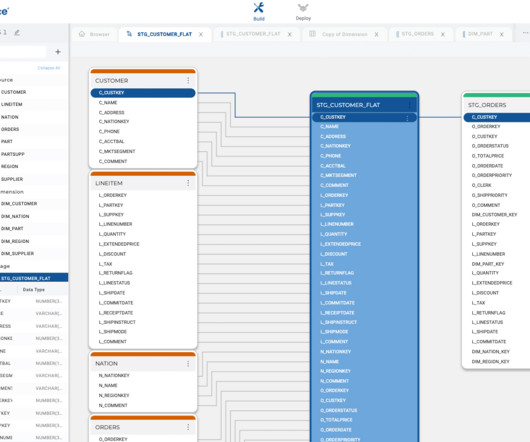
Putting the T for Transformation in ELT (ETL) is essential to any datapipeline. After extracting and loading your data into the Snowflake AI Data Cloud , you may wonder how best to transform it. Luckily, Snowflake answers this question with many features designed to transform your data for all your analytic use cases.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. What is Data Engineering? million by 2028. from 2025 to 2030.
Introduction In today’s hyper-connected world, you hear the terms “Big Data” and “Data Science” thrown around constantly. They pop up in news articles, job descriptions, and tech discussions. What exactly is Big Data? Database Knowledge: Like SQL for retrieving data.
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures.
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and of course, plenty related to large language models and generative AI. Originally posted on OpenDataScience.com Read more data science articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels!
Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code. WHERE d.name = 'Sales'; Matillion is designed as a no/low-code ELT tool, so lets leave the SQL deep dive for another time and focus on making workflows as clean and intuitive as possible!
That’s a problem when you’re trying to work with that data in pandas because you have to pull the dataset into the memory of your machine, which can be slow, expensive, and lead to fatal out-of-memory issues. Ponder solves this problem by translating your pandas code to SQL that can be understood by your data warehouse.
Software patterns in data science and ML engineering | Source: Author In this listicle of articles, I will go through all these different types of codebases from a very honest and pragmatic point of view, trying to give advice and tips to produce high-quality ML production code.
Increase your productivity in software development with Generative AI As I mentioned in Generative AI use case article, we are seeing AI-assisted developers. I include some reference for this field in that article, but as time goes by, it is necessary to dedicate a particular article to survey this field in-depth.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. The following article explains each of these in more detail with code.
This also consists of the ability to perform root cause analysis on data problems, optimize datapipelines for performance, and enable data integrity and quality. In this article, let’s understand an explanation of how to enhance problem-solving skills as a data engineer.
Summary: This article provides a comprehensive guide on Big Data interview questions, covering beginner to advanced topics. Introduction Big Data continues transforming industries, making it a vital asset in 2025. The global Big Data Analytics market, valued at $307.51 billion in 2023, is projected to grow to $348.21
Some of the databases supported by Fivetran are: Snowflake Data Cloud (BETA) MySQL PostgreSQL SAP ERP SQL Server Oracle In this blog, we will review how to pull Data from on-premise Systems using Fivetran to a specific target or destination. HVA also allows the capture of changes directly from various DBMS articles.
Get a Demo DATA + AI SUMMIT Data + AI Summit Happening Now Watch the free livestream of the keynotes! This standard simplifies pipeline development across batch and streaming workloads. Years of real-world experience have shaped this flexible, Spark-native approach for both batch and streaming pipelines.
For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. An ML system needs to transform the data into features, train models, and make predictions. This can seem daunting.
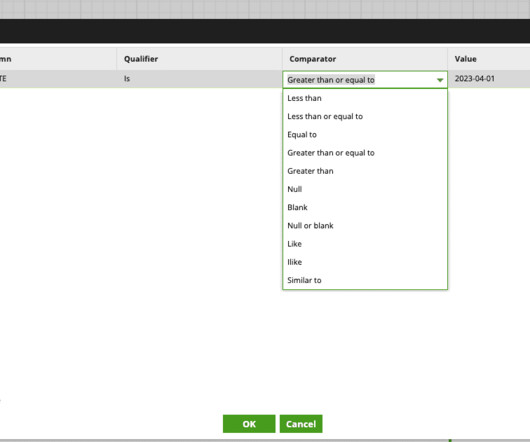
Click here for link to Part 1 of this article Continuing the Beginner’s Guide to GCP BigQuery series; in Part 2, we will take a look at the advantages and use cases of key features in BigQuery. To create a Scheduled Query, the initial step is to ensure your SQL is accurately entered in the Query Editor.
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
It involves extracting data from various sources, transforming it into a suitable format, and loading it into a target system for analysis and reporting. As organisations increasingly rely on data-driven insights, effective ETL processes ensure data integrity and quality, enabling informed decision-making.
Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines. These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment. It is lightweight.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
In this article, you’ll discover what a Snowflake data warehouse is, its pros and cons, and how to employ it efficiently. The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. Data warehousing is a vital constituent of any business intelligence operation.
Furthermore, we’ve developed data encryption and governance solutions for HPCC Systems to help secure data, ensure it is only accessed by appropriate personnel, and to create audit trails to ensure data security SLAs and regulations are met. It truly is an all-in-one data lake solution. Tell me more about ECL.
Though scripted languages such as R and Python are at the top of the list of required skills for a data analyst, Excel is still one of the most important tools to be used. Because they are the most likely to communicate data insights, they’ll also need to know SQL, and visualization tools such as Power BI and Tableau as well.
sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support. Presto engine: Incorporates the latest performance enhancements to the Presto query engine.
When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?” ” through a truly data literate organization. What is data democratization?
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination. The biggest reason is the ease of use.
Image generated with Midjourney Organizations increasingly rely on data to make business decisions, develop strategies, or even make data or machine learning models their key product. As such, the quality of their data can make or break the success of the company. What is a data quality framework?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content