This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
as described via the relevant Wikipedia article here: [link] ) and other factors, the digital age will keep producing hardware and software tools that are both wondrous, and/or overwhelming (e.g., For instance, in the table below, we juxtapose four authors’ professional opinions with DS-Dojo’s curriculum. IoT, Web 3.0,
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations. What is data mining?
Oil and gas dataanalysis – Before beginning operations at a well a well, an oil and gas company will collect and process a diverse range of data to identify potential reservoirs, assess risks, and optimize drilling strategies. Structured data consists of stock prices, financial statements, and economic indicators.
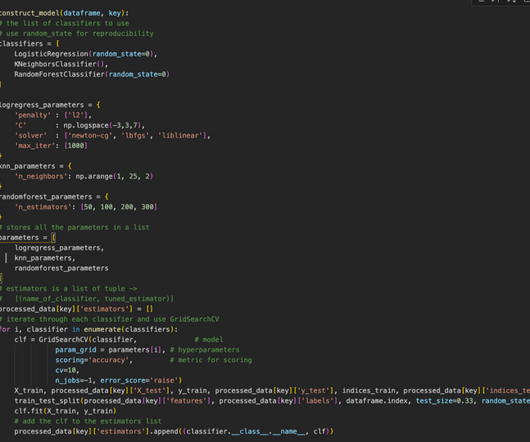
In this article, we will discuss the KNN Classification method of analysis. The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel.
Therefore, it mainly deals with unlabelled data. The ability of unsupervised learning to discover similarities and differences in data makes it ideal for conducting exploratory dataanalysis. It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean.
Without this library, dataanalysis wouldn’t be the same without pandas, which reign supreme with its powerful data structures and manipulation tools. Pandas provides a fast and efficient way to work with tabular data. It is widely used in data science, finance, and other fields where dataanalysis is essential.
By the end of the lesson, readers will have a solid grasp of the underlying principles that enable these applications to make suggestions based on dataanalysis. Text Mining Text mining ( Figure 6 ) is a powerful tool for extracting valuable information from textual data.
More detailed explanations of this task will be described in a different article. More details of this approach will be described in a different article. Some common quantitative evaluations are linear probing , Knearestneighbors (KNN), and fine-tuning. It allows us to perform big dataanalysis.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
The article also addresses challenges like data quality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. K-NearestNeighbors), while others can handle large datasets efficiently (e.g., The global Machine Learning market was valued at USD 35.80
K-Nearest Neighbou r: The k-NearestNeighbor algorithm has a simple concept behind it. The method seeks the knearest neighbours among the training documents to classify a new document and uses the categories of the knearest neighbours to weight the category candidates [3].
To land a coveted data science role, you must excel in the interview process, which often includes a series of challenging questions to assess your technical skills, problem-solving abilities, and domain knowledge. Read the full blog here — [link] Data Science Interview Questions for Freshers 1. What is the main advantage of sampling?
That post was dedicated to an exploratory dataanalysis while this post is geared towards building prediction models. Dealing with imbalanced data is pretty common in the real-world and these articles by German Lahera and on DataCamp are good places to learn about them. This is clearly an imbalanced dataset!
With time series data often being used in areas like economics, finance, and environmental science, understanding and addressing these gaps is crucial for informed decision-making. Missing data can lead to biased results and misinterpretations, making it vital for data scientists to develop strategies for handling them.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content