This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They are also used in machine learning, such as supportvectormachines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations.
10 Python packages for data science and machine learning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
as described via the relevant Wikipedia article here: [link] ) and other factors, the digital age will keep producing hardware and software tools that are both wondrous, and/or overwhelming (e.g., For instance, in the table below, we juxtapose four authors’ professional opinions with DS-Dojo’s curriculum. IoT, Web 3.0,
10 Python packages for data science and machine learning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
Rustic Learning: Machine Learning in Rust — Part 2: Regression and Classification An Introduction to Rust’s Machine Learning crates Photo by Malik Skydsgaard on Unsplash Rustic Learning is a series of articles that explores the use of Rust programming language for machine learning tasks.
In this article, I will show you what algorithm to use for each purpose and attain the desirable outcome you want without spending time going through each algorithm trying to figure out which one you want. . – Algorithms: SupportVectorMachines (SVM), Random Forest, Neural Networks. filterBounds(aoi).median().clip(aoi);//
Summary: The article explores the differences between data driven and AI driven practices. Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decision trees, neural networks, and supportvectormachines. Adapt models to new data and include the latest trends or patterns.
Understanding their differences is essential for businesses looking to implement machine learning effectively. This article provides a clear comparison between supervised and unsupervised learning, covering their unique characteristics, applications, and key differences. Unsupervised learning outputs are not as direct.
The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering. The idea is to sort the labels into clusters to create a meta-label space.
Basically, Machine learning is a part of the Artificial intelligence field, which is mainly defined as a technic that gives the possibility to predict the future based on a massive amount of past known or unknown data. In this article, I will cover all of them. Clustering is similar to classification, but the basis is different.
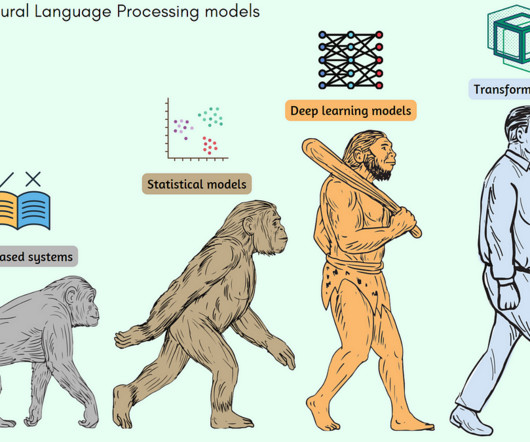
In this article, we’ll look at the evolution of these state-of-the-art (SOTA) models and algorithms, the ML techniques behind them, the people who envisioned them, and the papers that introduced them. Evolution of SOTA models in NLP and factors affecting them Here is the evolutionary map for this article.
The goal of unsupervised learning is to identify structures in the data, such as clusters, dimensions, or anomalies, without prior knowledge of the expected output. Some popular classification algorithms include logistic regression, decision trees, random forests, supportvectormachines (SVMs), and neural networks.
In the subsequent sections of this article, we will explore the challenges and limitations associated with artificial intelligence in IoT, as well as the key technologies and techniques driving this convergence. Unsupervised learning Unsupervised learning involves training machine learning models with unlabeled datasets.
In this article, we will explore the concept of applied text mining in Python and how to do text mining in Python. It helps in discovering hidden patterns and organizing text data into meaningful clusters. Topic Modeling and Document Clustering: Build a text mining project that performs topic modeling and document clustering.
To address this challenge, data scientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. Are there clusters of customers with different spending patterns? #3. SupportVectorMachine (svm): Versatile model for linear and non-linear data.
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. This technique is based on the concept that related information tends to cluster together.
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. This technique is based on the concept that related information tends to cluster together.
Hidden secret to empower semantic search This is the third article of building LLM-powered AI applications series. From the previous article , we know that in order to provide context to LLM, we need semantic search and complex query to find relevant context (traditional keyword search, full-text search won’t be enough).
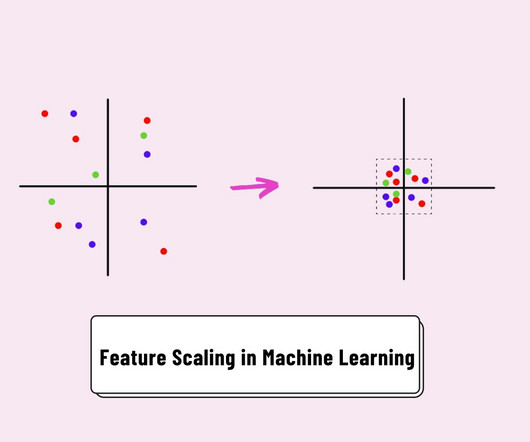
In this comprehensive article, we delve into the depths of feature scaling in Machine Learning, uncovering its importance, methods, and advantages while showcasing practical examples using Python. Understanding Feature Scaling in Machine Learning: Feature scaling stands out as a fundamental process.
With advances in machine learning, deep learning, and natural language processing, the possibilities of what we can create with AI are limitless. In this article, we will explore the essential steps involved in creating AI and the tools and techniques required to build robust and reliable AI systems.
Applications : Stock price prediction and financial forecasting Analysing sales trends over time Demand forecasting in supply chain management Clustering Models Clustering is an unsupervised learning technique used to group similar data points together. Popular clustering algorithms include k-means and hierarchical clustering.
scikit-learn – The most widely Machine learning for text used for Python, scikit-learn is an open-source, free machine learning library. It has many useful tools for stats modeling and machine learning including regression, classification, and clustering.
Photo by the author Recently I was given a Myo armband, and this article aims to describe how such a device could be exploited to control a robotic manipulator intuitively. I tried several other machine learning classifiers, but SVM turned out to be the best. The label of a cluster was set as a label for every one of its samples.
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. It covers types of Machine Learning, key concepts, and essential steps for building effective models. The global Machine Learning market was valued at USD 35.80 billion by 2031 at a CAGR of 34.20%.
This comprehensive article explores the pivotal role of bioinformatics in advancing biological research, focusing on its real-life applications, remarkable achievements, and the machine learning tools that have propelled the field forward.
This blog explores the difference between Machine Learning and Deep Learning , highlighting their unique characteristics, benefits, and challenges. This article aims to provide a clear comparison, helping you understand when to use Machine Learning and when to opt for Deep Learning based on specific needs and resources.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success.
This allows it to evaluate and find relationships between the data points which is essential for clustering. Supports batch processing for quick processing for the images. For instance, clustering algorithms like k-means can identify distinct groups within data, or distance-based methods can prioritize outliers.
We are going to discuss all of them later in this article. In this article, you will delve into the key principles and practices of MLOps, and examine the essential MLOps tools and technologies that underpin its implementation. Conclusion After reading this article, you now know about MLOps and its role in the machine learning space.
This article explores how AI and Data Science complement each other, highlighting their combined impact and potential. Machine Learning Supervised Learning includes algorithms like linear regression, decision trees, and supportvectormachines.
In this article, we will explore some common data science interview questions that will help you prepare and increase your chances of success. There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content