This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
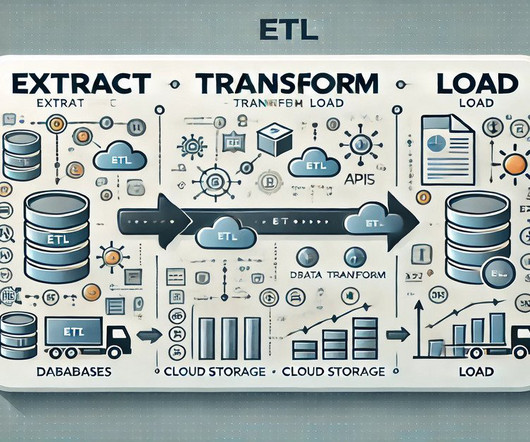
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring datapipelines. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL datapipeline in ML? Datapipelines often run real-time processing.
Boost productivity – Empowers knowledge workers with the ability to automatically and reliably summarize reports and articles, quickly find answers, and extract valuable insights from unstructured data. Data plane The data plane is where the actual data processing and integration take place.
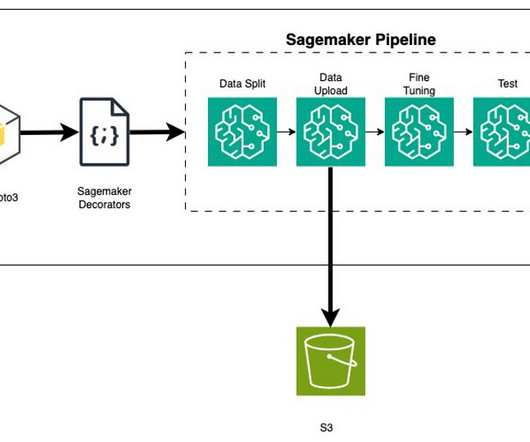
Photo by Markus Winkler on Unsplash This story explains how to create and orchestrate machine learning pipelines with AWS Step Functions and deploy them using Infrastructure as Code. This article is for data and ML Ops engineers who would want to deploy and update ML pipelines using CloudFormation templates.
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
If prompted, set up a user profile for SageMaker Studio by providing a user name and specifying AWS Identity and Access Management (IAM) permissions. AWS SDKs and authentication Verify that your AWS credentials (usually from the SageMaker role) have Amazon Bedrock access. Open a SageMaker Studio notebook: Choose JupyterLab.
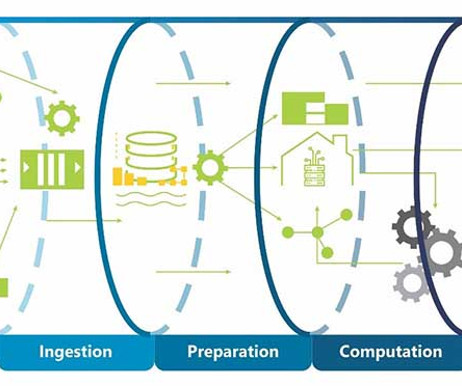
These procedures are central to effective data management and crucial for deploying machine learning models and making data-driven decisions. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline. What is a DataPipeline?
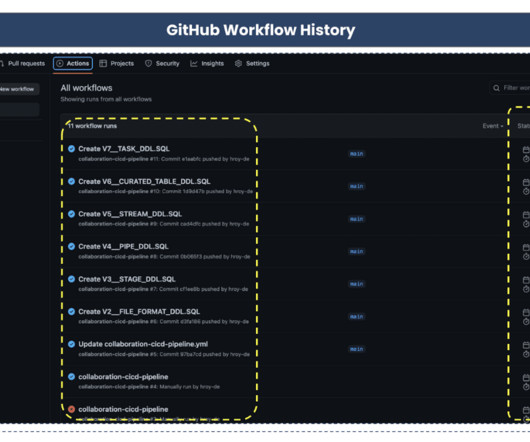
which play a crucial role in building end-to-end datapipelines, to be included in your CI/CD pipelines. Declarative Database Change Management Approaches For insights into database change management tool selection for Snowflake, check out this article.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Google Cloud is starting to make a name for itself as well.
Meme shared by bin4ry_d3struct0r TAI Curated section Article of the week Graph Neural Networks (GNN) — Concepts and Applications by Tan Pengshi Alvin Graph Neural Networks (GNN) are a very interesting application in deep learning and have strong potential for important use cases, albeit a less well-known and more niche domain.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
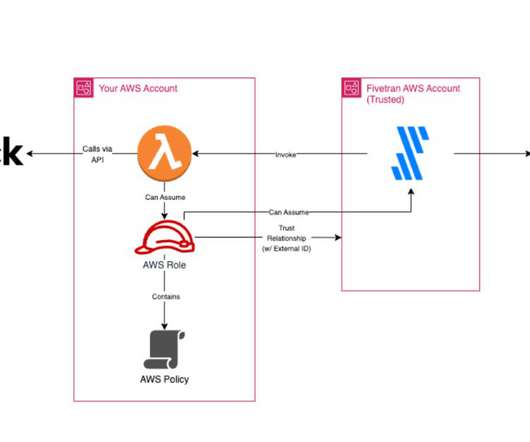
*This article is authored by both Arnab Mondal and Samuel Hall. In a previous post , we talked about setting up all the components necessary to create a pipeline for ingesting data from a custom source into the Snowflake Data Cloud using Fivetran. What is Infrastructure As Code?
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. What is Data Engineering? million by 2028. from 2025 to 2030.
This article is a real-life study of building a CI/CD MLOps pipeline. AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. An example would be AWS recognition. S3 buckets.
Cloud Services The only two to make multiple lists were Amazon Web Services (AWS) and Microsoft Azure. Most major companies are using one of the two, so excelling in one or the other will help any aspiring data scientist. Saturn Cloud is picking up a lot of momentum lately too thanks to its scalability.
Solution overview SageMaker algorithms have fixed input and output data formats. But customers often require specific formats that are compatible with their datapipelines. Option A In this option, we use the inference pipeline feature of SageMaker hosting. Dhawal Patel is a Principal Machine Learning Architect at AWS.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
This article explores the Pile Dataset, highlighting its composition, applications, and unique attributes. Diversity of Sources : The Pile integrates 22 distinct datasets, including scientific articles, web content, books, and programming code. Massive Scale : With over 800GB of data, the Pile offers unparalleled richness and variety.
Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors. These tools enable seamless data integration across multiple sources, streamlining data workflows. What is Data Transformation?
Introduction In today’s hyper-connected world, you hear the terms “Big Data” and “Data Science” thrown around constantly. They pop up in news articles, job descriptions, and tech discussions. What exactly is Big Data? It can be confusing!
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination. The biggest reason is the ease of use.
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
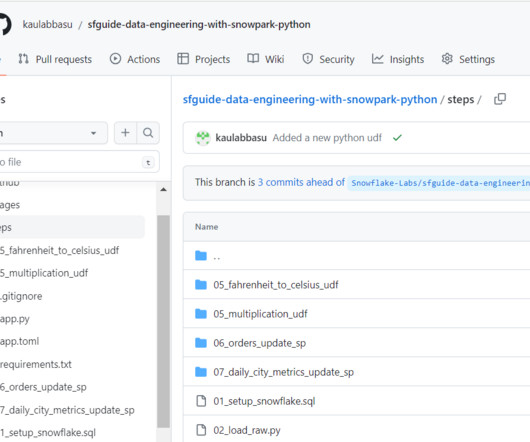
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. You can set up your own environment in your local system and then check in/deploy the code back to Snowflake using Snowpark (more on this later in the article).
Review the following article for detailed steps on managing and setting up Snowflake Cortex LLM or AWS Bedrock functions. Currently, Copilot is only available for transformation pipelines for Enterprise Edition customers and is exclusive to Snowflake projects. No customer data is shared with the large language model.
The right ETL platform ensures data flows seamlessly across systems, providing accurate and consistent information for decision-making. Effective integration is crucial to maintaining operational efficiency and data accuracy, as modern businesses handle vast amounts of data. What is ETL in Data Integration?
sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
We hope our experience dealing with these challenges can help you understand the complexity of the crypto world and perhaps give you cool insights on how to deal with your own data problems and team management. 3 To redesign and rewrite the architecture as Infrastructure as Code (using AWS Cloudformation).
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines. These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment. It is lightweight.
Increase your productivity in software development with Generative AI As I mentioned in Generative AI use case article, we are seeing AI-assisted developers. I include some reference for this field in that article, but as time goes by, it is necessary to dedicate a particular article to survey this field in-depth.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
Learn from the practical experience of four ML teams on collaboration in this article. Data scientists and machine learning engineers need an infrastructure layer that lets them scale their work without having to be networking experts. (in This article defines architecture as the way the highest-level components are wired together.
In this article, you will learn about version control for ML models, and why it is crucial in ML. We will demonstrate how you can use any of these tools in a later section of the article. Data Versioning In ML projects, keeping track of datasets is very important because the data can change over time.
We are going to discuss all of them later in this article. In this article, you will delve into the key principles and practices of MLOps, and examine the essential MLOps tools and technologies that underpin its implementation. Conclusion After reading this article, you now know about MLOps and its role in the machine learning space.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content