
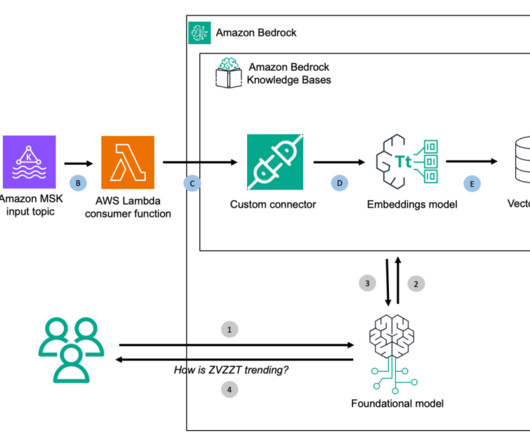
Stream ingest data from Kafka to Amazon Bedrock Knowledge Bases using custom connectors
AWS Machine Learning Blog
APRIL 18, 2025
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for Apache Kafka (Amazon MSK) for a user who may be interested to understand stock price trends.

















Let's personalize your content