This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction The bigdata industry is growing daily and needs tools to process vast volumes of data. That’s why you need to know about ApacheKafka, a publish-subscribe messaging system you can use to build distributed applications.
This article was published as a part of the Data Science Blogathon. Introduction When we mention BigData, one of the types of data usually talked about is the Streaming Data. Streaming Data is generated continuously, by multiple data sources say, sensors, server logs, stock prices, etc.
This article was published as a part of the Data Science Blogathon. The post ApacheKafka Use Cases and Installation Guide appeared first on Analytics Vidhya. Introduction Today, we expect web applications to respond to user queries quickly, if not immediately. Source: kafka.apache.org Caching is used to solve […].
This article was published as a part of the Data Science Blogathon. The post Introduction to ApacheKafka: Fundamentals and Working appeared first on Analytics Vidhya. All these sites use some event streaming tool to monitor user activities. […]. . […].
This article was published as a part of the Data Science Blogathon. Dale Carnegie” ApacheKafka is a Software Framework for storing, reading, and analyzing streaming data. Introduction “Learning is an active process. We learn by doing. Only knowledge that is used sticks in your mind.-
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. They must also ensure that data privacy regulations, such as GDPR and CCPA , are followed.
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdata pipeline.
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
In this contributed article, Sijie Guo, Founder and CEO of Streamnative, believes that with remote work entrenched in the post-pandemic enterprise, organizations are restructuring their technology stack and software strategy for a new, distributed workforce.
In this contributed article, Sijie Guo, Founder and CEO of Streamnative, believes that with remote work entrenched in the post-pandemic enterprise, organizations are restructuring their technology stack and software strategy for a new, distributed workforce.
Business success is based on how we use continuously changing data. That’s where streaming data pipelines come into play. This article explores what streaming data pipelines are, how they work, and how to build this data pipeline architecture. What is a streaming data pipeline? Now, information is dynamic.
Originally posted on OpenDataScience.com Read more data science articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels! The session participants will learn the theory behind compound sparsity, state-of-the-art techniques, and how to apply it in practice using the Neural Magic platform.
There are many platforms and sources that generate this kind of data. In this article, we will go through the basics of streaming data, what it is, and how it differs from traditional data. We will also get familiar with tools that can help record this data and further analyse it.
As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. The global BigData and Data Engineering Services market, valued at USD 51,761.6 Its ability to handle vast amounts of data makes it a cornerstone in bigdata environments.
Text Analytics and Natural Language Processing (NLP) Projects: These projects involve analyzing unstructured text data, such as customer reviews, social media posts, emails, and news articles. NLP techniques help extract insights, sentiment analysis, and topic modeling from text data.
Summary: This article highlights the significance of Database Management Systems in social media giants, focusing on their functionality, types, challenges, and future trends that impact user experience and data management. They provide flexibility in data models and can scale horizontally to manage large volumes of data.
Data engineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in data engineering that are used to solve different data-related problems.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
Most large technology businesses collect data from their consumers in a variety of methods, and the majority of the time, this data is in its raw form. However, when data is presented in an understandable and accessible style, it may assist and drive business requirements.
Listed below are some of the common types of data pipeline tools: Commercial vs open-source data pipeline tools When a business needs full control over the development process and wants to build highly customizable complex solutions, open-source tools come in handy. No built-in data quality functionality. No expert support.
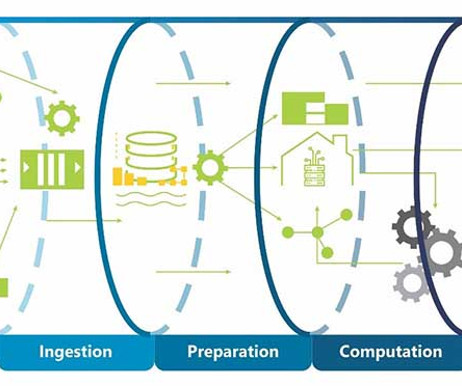
1 Data Ingestion (e.g., ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., Conclusion This article covered various aspects, including pipeline architecture, design considerations, standard practices in leading tech corporations, common patterns, and typical components of ML pipelines. 2022, January 18).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content