

Essential data engineering tools for 2023: Empowering for management and analysis
Data Science Dojo
JULY 6, 2023
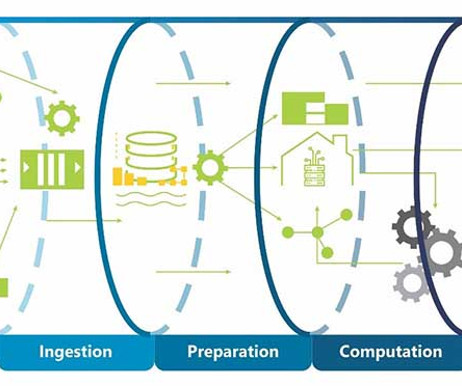
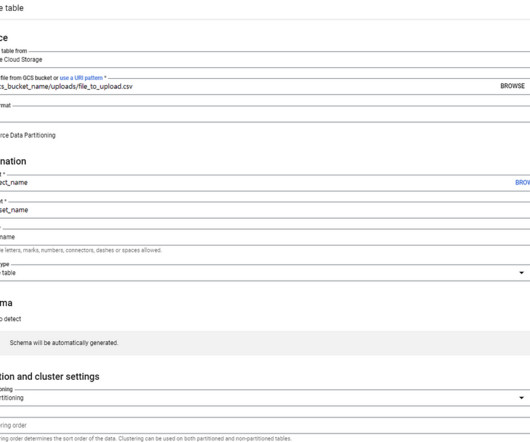
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. It integrates well with other Google Cloud services and supports advanced analytics and machine learning features.














Let's personalize your content