This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
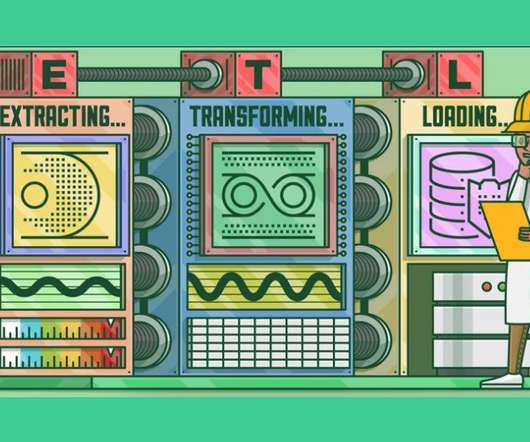
Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a data warehouse. Extraction, transformation, and loading are three interdependent procedures used to pull data from one database and place […].
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
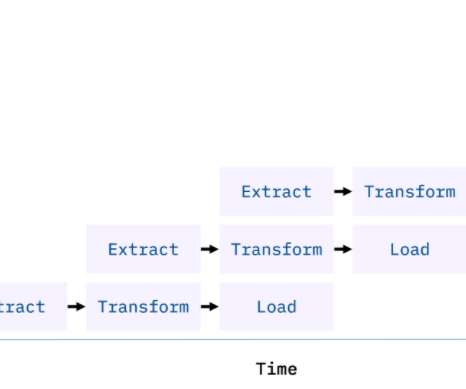
Introduction The data integration techniques ETL (Extract, Transform, Load) and ELT pipelines (Extract, Load, Transform) are both used to transfer data from one system to another.
Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya. Many companies prefer to work with serverless tools and codeless solutions to minimize costs and streamline their processes.
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
Introduction Organizations with a separate transactional database and data warehouse typically have many data engineering activities. The post Apache Airflow used for Performing ETL appeared first on Analytics Vidhya. The post Apache Airflow used for Performing ETL appeared first on Analytics Vidhya.
Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. The post ETL Pipeline using Shell Scripting | Data Pipeline appeared first on Analytics Vidhya.
Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and data integration service which allows you to create a data-driven workflow. The post From Blob Storage to SQL Database Using Azure Data Factory appeared first on Analytics Vidhya. In this article, I’ll show […].
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
Users of Oozie can describe dependencies between various jobs […] The post Difference between ETL and ELT Pipeline appeared first on Analytics Vidhya. It enables users to plan and carry out complex data processing workflows while handling several tasks and operations throughout the Hadoop ecosystem.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […]. The post Developing an End-to-End Automated Data Pipeline appeared first on Analytics Vidhya.
ETL pipelines are revolutionizing the way organizations manage data by transforming raw information into valuable insights. In a world where data is constantly generated, understanding how ETL pipelines function is essential for organizations aiming to thrive in their industries. What is an ETL pipeline?
Context Manager Pattern for Resource Management When working with resources like files, database connections, or network sockets, you need to ensure they’re properly opened and closed, even if an error occurs. Example: Suppose you’re fetching user data from a database and want to provide context when a database error occurs.
Enter the realm of data science careers—a domain that harnesses the power of advanced analytics, cutting-edge technologies, and domain expertise to unravel the untapped potential hidden within data. They require strong analytical skills, knowledge of statistical analysis, and expertise in data visualization.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
It also supports a wide range of data warehouses, analyticaldatabases, data lakes, frontends, and pipelines/ETL. Support for Various Data Warehouses and Databases : AnalyticsCreator supports MS SQL Server 2012-2022, Azure SQL Database, Azure Synapse Analytics dedicated, and more.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
Introduction SQL is a database programming language created for managing and retrieving data from Relational databases like MySQL, Oracle, and SQL Server. SQL(Structured Query Language) is the common language for all databases. In other terms, SQL is a language that communicates with databases.
Skills and Training Familiarity with ethical frameworks like the IEEE’s Ethically Aligned Design, combined with strong analytical and compliance skills, is essential. Database Analyst Description Database Analysts focus on managing, analyzing, and optimizing data to support decision-making processes within an organization.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
ETL (Extract, Transform, Load) is a crucial process in the world of data analytics and business intelligence. In this article, we will explore the significance of ETL and how it plays a vital role in enabling effective decision making within businesses. What is ETL? Let’s break down each step: 1.
Cloud analytics is one example of a new technology that has changed the game. Let’s delve into what cloud analytics is, how it differs from on-premises solutions, and, most importantly, the eight remarkable ways it can propel your business forward – while keeping a keen eye on the potential pitfalls. What is cloud analytics?
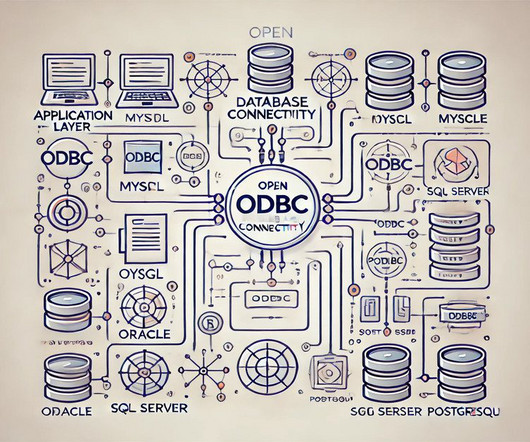
Summary: Open Database Connectivity (ODBC) is a standard interface that simplifies communication between applications and database systems. It enhances flexibility and interoperability, allowing developers to create database-agnostic code. What is Open Database Connectivity (ODBC)?
JDBC, for Java-specific environments, offers efficient Java-based database connectivity, while ODBC provides a versatile, language-independent solution. Introduction Database connectivity is a crucial link between applications and databases , allowing seamless data exchange. What is JDBC? billion by 2024 at a CAGR of 15.2%.
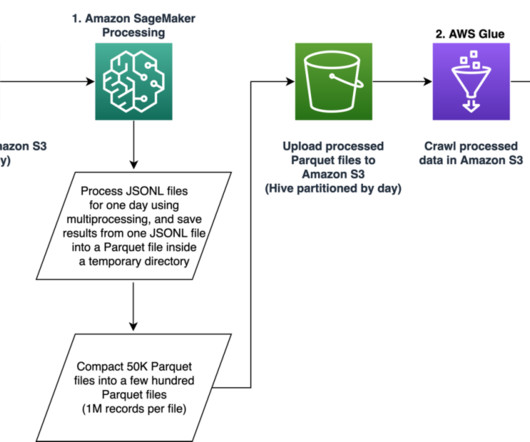
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
ETL processes ETL, or Extract, Transform, Load, plays a pivotal role in the creation of data marts. With efficient ETL practices, organizations can maintain high data quality and relevant structures. Database replication Alongside ETL, database replication ensures that data marts are updated consistently.
Familiarise yourself with ETL processes and their significance. Unlike operational databases, which support daily transactions, data warehouses are optimised for read-heavy operations and analytical processing. How Does a Data Warehouse Differ from a Database? Can You Explain the ETL Process?
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
In the contemporary age of Big Data, Data Warehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
By understanding how to effectively ingest data, businesses can maximize their operational efficiency and leverage analytics for informed decision-making. Data ingestion refers to the process of obtaining and importing data for immediate use or storage in a database. What is data ingestion?
Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. The remote engine allows ETL/ELT jobs to be designed once and run anywhere.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
The ingestion pipeline (3) ingests metadata (1) from services (2), including Amazon DataZone, AWS Glue, and Amazon Athena , to a Neptune database after converting the JSON response from the service APIs into an RDF triple format. Run SPARQL queries in the Neptune database to populate additional triples from inference rules.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. This blog explores the fundamental concepts of ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform), two pivotal methods in modern data architectures. What is ETL?
High-performance, low-footprint SQL database written in C++. Supports powerful features like JOIN, CDC, UPSERT, and LOOKUP, enabling real-time analytics and ETL at scale. Process millions of rows per second from Kafka, Pulsar, or ClickHouse, and seamlessly write results back.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Introduction The ETL process is crucial in modern data management. What is ETL? ETL stands for Extract, Transform, Load.
The ETL (extract, transform, and load) technology market also boomed as the means of accessing and moving that data, with the necessary translations and mappings required to get the data out of source schemas and into the new DW target schema. financial reporting, customer analytics, supply chain management).
We’re well past the point of realization that big data and advanced analytics solutions are valuable — just about everyone knows this by now. With databases, for example, choices may include NoSQL, HBase and MongoDB but its likely priorities may shift over time. In fact, there’s no escaping the increasing reliance on such technologies.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content