This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. It’s an integral part of dataanalytics and plays a crucial role in data science.
Predictive modeling plays a crucial role in transforming vast amounts of data into actionable insights, paving the way for improved decision-making across industries. By leveraging statistical techniques and machine learning, organizations can forecast future trends based on historical data. What is predictive modeling?
Introduction If you are learning DataAnalytics , statistics , or predictive modeling and want to have a comprehensive understanding of types of data sampling, then your searches end here. Throughout the field of dataanalytics, sampling techniques play a crucial role in ensuring accurate and reliable results.
Data science is an interdisciplinary field that utilizes advanced analytics techniques to extract meaningful insights from vast amounts of data. This helps facilitate data-driven decision-making for businesses, enabling them to operate more efficiently and identify new opportunities.
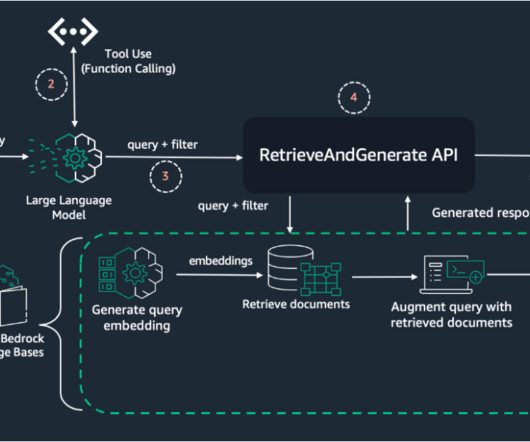
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
Hopefully, at the top, because it’s the very foundation of self-service analytics. We’re all trying to use more data to make decisions, but constantly face roadblocks and trust issues related to data governance. . Data certification: Duplicated data can create inconsistency and trust issues. Data modeling.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Hopefully, at the top, because it’s the very foundation of self-service analytics. We’re all trying to use more data to make decisions, but constantly face roadblocks and trust issues related to data governance. . Data certification: Duplicated data can create inconsistency and trust issues. Data modeling.
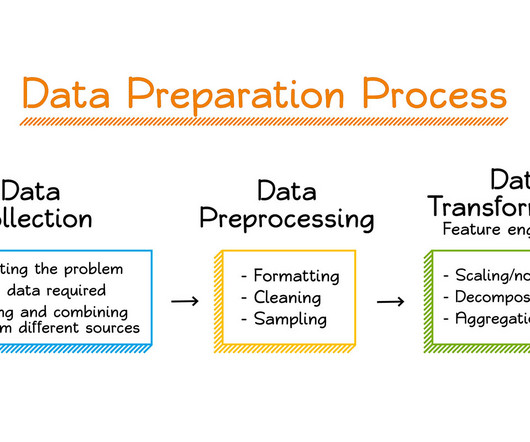
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. RPA uses a graphical user interface (GUI) to interact with applications and websites, while ML uses algorithms and statistical models to analyze data.
Instead of centralizing data stores, data fabrics establish a federated environment and use artificial intelligence and metadata automation to intelligently secure data management. . At Tableau, we believe that the best decisions are made when everyone is empowered to put data at the center of every conversation.
Instead of centralizing data stores, data fabrics establish a federated environment and use artificial intelligence and metadata automation to intelligently secure data management. . At Tableau, we believe that the best decisions are made when everyone is empowered to put data at the center of every conversation.
ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
(Or even better than that) Machine learning has transformed the way businesses operate by automating processes, analyzing data patterns, and improving decision-making. It plays a crucial role in areas like customer segmentation, fraud detection, and predictive analytics. These are known as supervised learning and unsupervised learning.
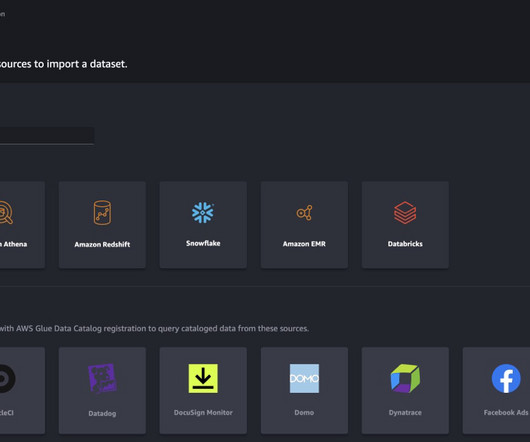
Connection definition JSON file When connecting to different data sources in AWS Glue, you must first create a JSON file that defines the connection properties—referred to as the connection definition file. The following is a sample connection definition JSON for Snowflake.
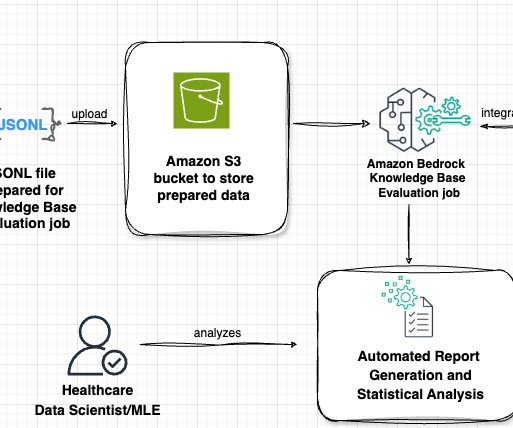
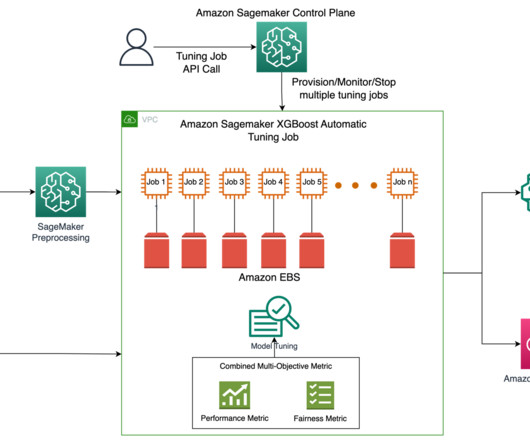
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions. No definite pneumonia.
In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail. Datapreparation Scalable Capital uses a CRM tool for managing and storing email data. She is responsible for data-driven approaches and use cases in the company together with her teams.
It provides a single web-based visual interface where you can perform all ML development steps, including preparingdata and building, training, and deploying models. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. compute.internal.
This includes duplicate removal, missing value treatment, variable transformation, and normalization of data. Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for datapreparation before analysis.
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. RPA uses a graphical user interface (GUI) to interact with applications and websites, while ML uses algorithms and statistical models to analyze data.
This approach was use case-specific and required datapreparation and manual work. The chain-of-thought prompting technique guides the LLMs to break down a problem into a series of intermediate steps or reasoning steps, explicitly expressing their thought process before arriving at a definitive answer or output.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
This entails breaking down the large raw satellite imagery into equally-sized 256256 pixel chips (the size that the mode expects) and normalizing pixel values, among other datapreparation steps required by the GeoFM that you choose. This routine can be conducted at scale using an Amazon SageMaker AI processing job.
The Datamarts capability opens endless possibilities for organizations to achieve their dataanalytics goals on the Power BI platform. A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle. What is a Datamart? A replacement for datasets.
It provides a unified, web-based interface where data scientists and developers can perform ML tasks, including datapreparation, model building, training, tuning, evaluation, deployment, and monitoring. This makes it ideal for workloads demanding rapid data access and processing.
A Data Catalog is a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses.
SageMaker Studio allows data scientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. The following excerpt from the code shows the model definition and the train function: # define network class Net(nn.Module): def __init__(self): super(Net, self).__init__()
Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering. Datapreparation To extract data efficiently for training and testing, we utilize Amazon Athena and the AWS Glue Data Catalog.
These statistics underscore the significant impact that Data Science and AI are having on our future, reshaping how we analyse data, make decisions, and interact with technology. Key Takeaways Data-driven decisions enhance efficiency across various industries. Predictive analytics improves customer experiences in real-time.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Data is split into a training dataset and a testing dataset. Both the training and validation data are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket for model training in the client account, and the testing dataset is used in the server account for testing purposes only.
Why will other data people be interested in these case studies? Andrea Levy, Technical Lead, Data Science & Analytics, Alation: First of all: impact! The query reuse case study , especially demonstrates the value of collaboration and centralization of analytics teams. Naveen: Definitely! Talo: And you, Naveen?
It’s crucial to grasp these concepts, considering the exponential growth of the global Data Science Platform Market, which is expected to reach 26,905.36 Similarly, the Data and Analytics market is set to grow at a CAGR of 12.85% , reaching 15,313.99 More to read: How is Data Visualization helpful in Business Analytics?
Efficient data transformation and processing are crucial for dataanalytics and generating insights. Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the data pipeline.
Amazon SageMaker Clarify can detect potential bias during datapreparation, after model training, and in your deployed model. The definition of these hyperparameters and others available with SageMaker AMT can be found here. His current areas of focus are AI/ML, DataAnalytics and Observability.
The financial services industry (FSI) is no exception to this, and is a well-established producer and consumer of data and analytics. These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). The union of advances in hardware and ML has led us to the current day.
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes.
We don’t claim this is a definitive analysis but rather a rough guide due to several factors: Job descriptions show lagging indicators of in-demand prompt engineering skills, especially when viewed over the course of 9 months. The definition of a particular job role is constantly in flux and varies from employer to employer.
Companies like Netflix and Uber use Keras for recommendation systems and predictive analytics. Launched by Microsoft, Azure ML provides a comprehensive suite of tools and services to support the entire machine learning lifecycle, from datapreparation to model deployment and management.
AI-ready data comes with comprehensive metadata (schema, definitions) to be understandable by humans and AI alike, it maintains a consistent format across historical and real-time streams, and it includes governance/lineage to ensure accuracy and trust. In short, its analytics-grade dataprepared for AI.
Carrier is making more precise energy analytics and insights accessible to customers so they reduce energy consumption and cut carbon emissions. Clariant is empowering its team members with an internal generative AI chatbot to accelerate R&D processes, support sales teams with meeting preparation, and automate customer emails.
There are definitely compelling economic reasons for us to enter into this realm. Datapreparation, train and tune, deploy and monitor. We have data pipelines and datapreparation. Because that’s the data that’s going to be training the model. It can cover the gamut.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















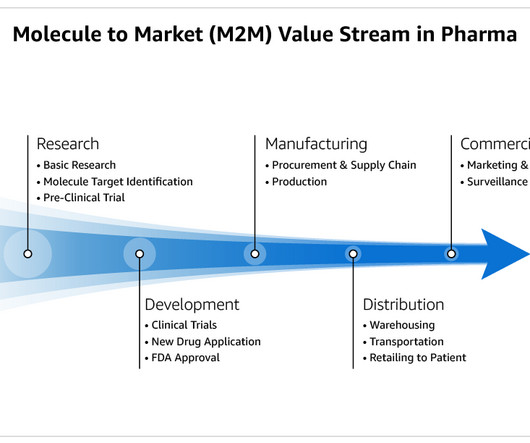



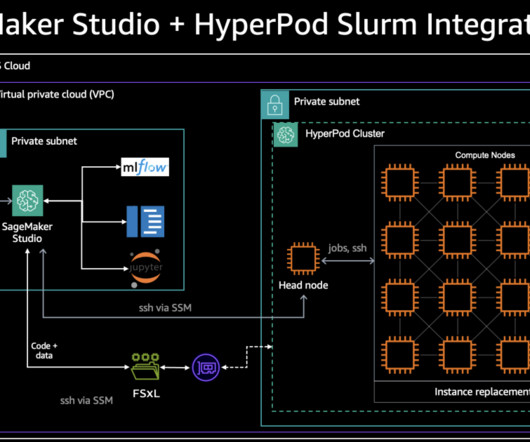

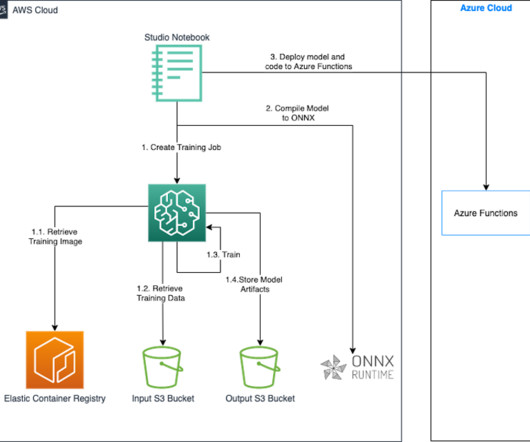



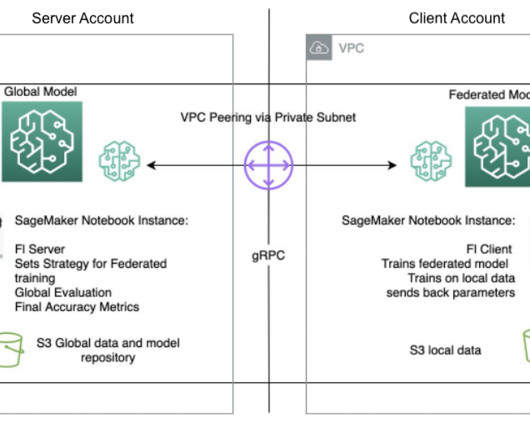














Let's personalize your content