This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. With QuickSight, all users can meet varying analytic needs from the same source of truth through modern interactive dashboards, paginated reports, embedded analytics, and natural language queries.
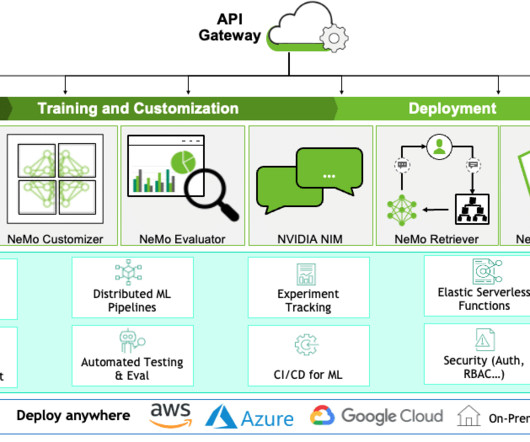
Then, we show how to use NVIDIA NIM with MLRun to productize gen AI applications at scale and reduce risks , including a demo of a multi-agent banking chatbot. Ensuring data security, lineage and risk controls. When developers and data scientists need a gen Al app/tech playground. What is a Gen AI Factory?
Increased datapipeline observability As discussed above, there are countless threats to your organization’s bottom line. That’s why datapipeline observability is so important. Realize the benefits of automated data lineage today. Schedule a demo with a MANTA engineer to learn more.
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications. However, this is only the first step.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml
A 2025 landscape analysis shows ApacheKafka , Flink , and Iceberg moving from niche tools to fundamental parts of modern data architecture, underscoring how ubiquitous realtime expectations have become. Because in 2025, the winners will be the brands whose data arrives in milliseconds not minutes.
Boost productivity – Empowers knowledge workers with the ability to automatically and reliably summarize reports and articles, quickly find answers, and extract valuable insights from unstructured data. The following demo shows Agent Creator in action.
It also enables operational capabilities including automated testing, conversation analytics, monitoring and observability, and LLM hallucination prevention and detection. “We An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. seconds or less.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. Optimize recruiting pipelines.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. Optimize recruiting pipelines.
Key Takeaways Data Mesh is a modern data management architectural strategy that decentralizes development of trusted data products to support real-time business decisions and analytics. It’s time to rethink how you manage data to democratize it and make it more accessible. What is Data Mesh?
Do we have end-to-end datapipeline control? What can we learn about our data quality issues? How can we improve and deliver trusted data to the organization? One major obstacle presented to data quality is data silos , as they obstruct transparency and make collaboration tough. Unified Teams. Get Started.
This is especially true for questions that require analytical reasoning across multiple documents. This task involves answering analytical reasoning questions. In this post, we show how to design an intelligent document assistant capable of answering analytical and multi-step reasoning questions in three parts.
Amazon SageMaker Canvas is a no-code ML workspace offering ready-to-use models, including foundation models, and the ability to prepare data and build and deploy custom models. In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics.
As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down data silos and power their streaming datapipelines with trusted data. Let’s cover some additional information to know before attending.
The rise of data lakes, IOT analytics, and big datapipelines has introduced a new world of fast, big data. This new world of analytics has introduced a different set of complexities that have propelled IT organizations to build new technology infrastructures. [2] -->.
To learn more, watch the webinar “Implementing Gen AI for Financial Services” with Larry Lerner, Partner & Global Lead - Banking and Securities Analytics, McKinsey & Company, and Yaron Haviv, Co-founder and CTO, Iguazio (acquired by McKinsey), which this blog post is based on. Let’s dive into the data management pipeline.
Databricks Databricks is a cloud-native platform for big data processing, machine learning, and analytics built using the Data Lakehouse architecture. It enables data scientists to log, compare, and visualize experiments, track code, hyperparameters, metrics, and outputs. Check out the Kedro’s Docs.
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure. 3) Data professionals come in all shapes and forms.
.” This user interface not only brings Apache Flink to anyone that can add business value, but it also allows for experimentation that has the potential to drive innovation speed up your dataanalytics and datapipelines. Request a live demo to see how working with real-time events can benefit your business.
For data science practitioners, productization is key, just like any other AI or ML technology. Successful demos alone just won’t cut it, and they will need to take implementation efforts into consideration from the get-go, and not just as an afterthought. What are their expectations from this hyped technology?
Thirdly, there are improvements to demos and the extension for Spark. Follow our GitHub repo , demo repository , Slack channel , and Twitter for more documentation and examples of the DJL! There is also work to support streaming inference requests in DJL Serving. Zach Kimberg is a Software Developer in the Amazon AI org.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. But good data—and actionable insights—are hard to get. What is Salesforce Data Cloud for Tableau?
In that sense, data modernization is synonymous with cloud migration. Modern data architectures, like cloud data warehouses and cloud data lakes , empower more people to leverage analytics for insights more efficiently. Access the resources your data applications need — no more, no less. Advanced Tooling.
Confluent data streams help accelerate innovation for data and analytics initiatives – but only when sourcing from data you can trust. Precisely – the global leader in data integrity and a proud Connect with Confluent program member – helps you build trust in your data to derive the insights your business users need.
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. conda activate snowflake-demo ). Validating the Deployment in Snowflake Existence – The newly created Python UDF should be present under the Analytics schema under the HOL_DB database.
For data science practitioners, productization is key, just like any other AI or ML technology. Successful demos alone just won’t cut it, and they will need to take implementation efforts into consideration from the get-go, and not just as an afterthought. What are their expectations from this hyped technology?
Get a DemoDATA + AI SUMMIT Data + AI Summit Happening Now Watch the free livestream of the keynotes! This standard simplifies pipeline development across batch and streaming workloads. Years of real-world experience have shaped this flexible, Spark-native approach for both batch and streaming pipelines.
Request a demo to see how watsonx can put AI to work There’s no AI, without IA AI is only as good as the data that informs it, and the need for the right data foundation has never been greater. Data lakehouses improve the efficiency of deploying AI and the generation of datapipelines.
AI-ready data comes with comprehensive metadata (schema, definitions) to be understandable by humans and AI alike, it maintains a consistent format across historical and real-time streams, and it includes governance/lineage to ensure accuracy and trust. In short, its analytics-grade data prepared for AI.
We’ll explore how factors like batch size, framework selection, and the design of your datapipeline can profoundly impact the efficient utilization of GPUs. We need a well-optimized datapipeline to achieve this goal. The pipeline involves several steps. What should be the GPU usage?
Consider a datapipeline that detects its own failures, diagnoses the issue, and recommends the fix—all automatically. This is the potential of self-healing pipelines, and this blog explores how to implement them using dbt, Snowflake Cortex , and GitHub Actions. This leads to a prompt like: final_question = " ".join([
The most critical and impactful step you can take towards enterprise AI today is ensuring you have a solid data foundation built on the modern data stack with mature operational pipelines, including all your most critical operational data.
An ML platform standardizes the technology stack for your data team around best practices to reduce incidental complexities with machine learning and better enable teams across projects and workflows. We ask this during product demos, user and support calls, and on our MLOps LIVE podcast. Why are you building an ML platform?
Patil also highlighted the need for pragmatic, data-driven leadership, saying “Every boardroom needs a Spock.” For those unfamiliar with Star Trek, Spock is known for his logical, analytical, and unemotional approach to making decisions – making him an ideal advisor in high-pressure situations.
For the past four years, Gartner has hosted a BI Bake Off competition at the Gartner Data and Analytics Summit in Texas. Selected vendors are given the opportunity to highlight their solutions and show how data and analytics can be harnessed for social good. Alation BI Bake Off Demo.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls.
From May 13th to 15th, ODSC East 2025 will bring together the brightest minds and most innovative companies in AI for three days of cutting-edge insights, hands-on demos, and one-on-one conversations. Dive into tools like Perspective , DuckDB , and InfluxDB for lightning-fast analytics without the server overhead.
Demos & tutorials: Harness Builder → https://www.youtube.com/watch?v=JfQVB_iTD1I reply efromvt 7 hours ago | prev | next [–] Continuing to plug away at Trilogy, a better SQL for data consumption and analytics. Happy to chat if you're into VMs, query engines, or DSLs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















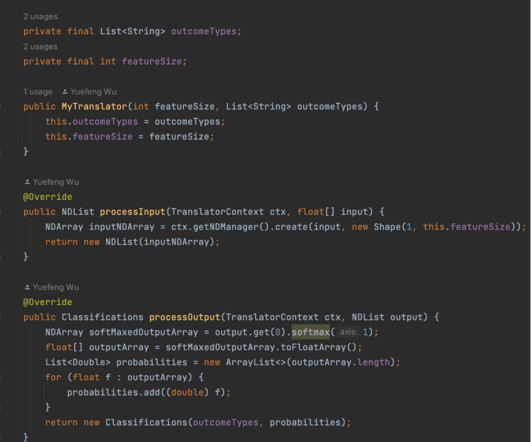





















Let's personalize your content