This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering? Initially, we have the definition of Software […]. appeared first on Analytics Vidhya.
Data marts soon evolved as a core part of a DW architecture to eliminate this noise. Data marts involved the creation of built-for-purpose analytic repositories meant to directly support more specific business users and reporting needs (e.g., financial reporting, customer analytics, supply chain management). A datalake!
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Structured data is a fundamental component in the world of data management and analytics, playing a crucial role in how we store, retrieve, and process information. By organizing data into a predetermined format, it enables efficient access and manipulation, forming the backbone of many applications across various industries.
Microsoft has made good on its promise to deliver a simplified and more efficient Microsoft Fabric price model for its end-to-end platform designed for analytics and data workloads. Microsoft’s unified pricing model for the Fabric suite marks a significant advancement in the analytics and data market.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
The primary purpose of conformed dimensions is to provide clarity and uniformity, which are essential for effective reporting and analytics. Definition of conformed dimension In data warehousing, conformed dimensions represent standardized dimensions that different fact tables can reference.
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. It’s an integral part of dataanalytics and plays a crucial role in data science. Each stage is crucial for deriving meaningful insights from data.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Disruptive Trend #1: Hadoop.
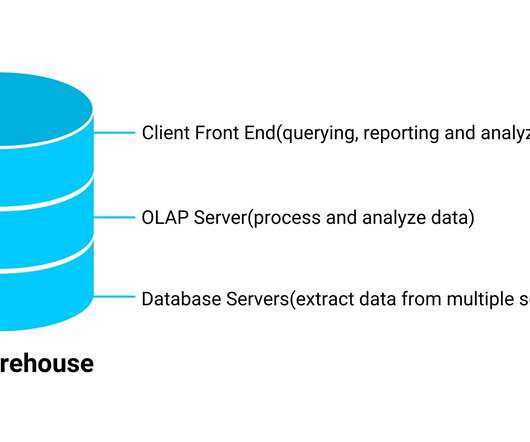
A data warehouse is a centralized and structured storage system that enables organizations to efficiently store, manage, and analyze large volumes of data for business intelligence and reporting purposes. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only). Query the vector data store You can query the vector data store using the Vector Search aggregation pipeline. It uses the Vector Search index and performs a semantic search on the vector data store.
Another IDC study showed that while 2/3 of respondents reported using AI-driven dataanalytics, most reported that less than half of the data under management is available for this type of analytics. from 2022 to 2026. New insights and relationships are found in this combination.
Other users Some other users you may encounter include: Data engineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. AIIA MLOps blueprints.
Instead of centralizing data stores, data fabrics establish a federated environment and use artificial intelligence and metadata automation to intelligently secure data management. . At Tableau, we believe that the best decisions are made when everyone is empowered to put data at the center of every conversation.
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
Instead of centralizing data stores, data fabrics establish a federated environment and use artificial intelligence and metadata automation to intelligently secure data management. . At Tableau, we believe that the best decisions are made when everyone is empowered to put data at the center of every conversation.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Today, modern travel and tourism thrive on data. For example, airlines have historically applied analytics to revenue management, while successful hospitality leaders make data-driven decisions around property allocation and workforce management. What is big data in the travel and tourism industry?
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you want to do the process in a low-code/no-code way, you can follow option C.
To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. Much of what we found was to be expected, though there were definitely a few surprises. You’ll see specific tools in the next section.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Analytical and transactional worlds come together.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
External Tables Create a Shared View of the DataLake. We’ve seen external tables become popular with our customers, who use them to provide a normalized relational schema on top of their datalake. Essentially, external tables create a shared view of the datalake, a single pane of glass everyone can reference.
A Data Catalog is a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses. Conclusion.
Quotes Data governance is going to play a large role in what data can go into an LLM. VP of Analytics, Finance Industry It will be increasingly important for organizations to understand how LLMs are trained -- whether on the company's own data or paired with others. No problem!
Azure ML supports various approaches to model creation: Automated ML : For beginners or those seeking quick results, Automated ML can generate optimized models based on your dataset and problem definition. Simply prepare your data, define your target variable, and let AutoML explore various algorithms and hyperparameters.
Between faster queries, better cost efficiency, and streamlined data management, there’s a lot to gain from a cost and performance perspective by optimizing your Snowflake account. Storage Costs Our first tip involves taking a closer look at managing how your data is stored, organized, and accessed.
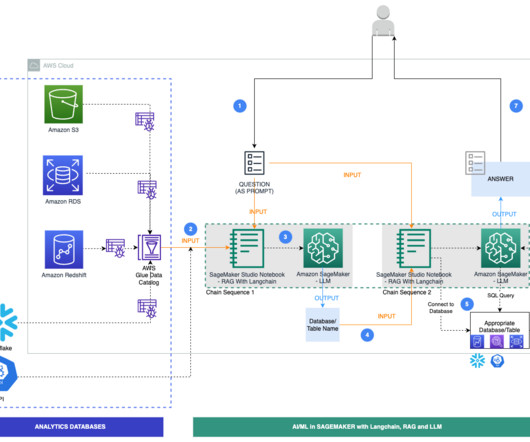
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
Dan Kirsch, Analyst, Hurwitz Associates, agrees that CISOs must take responsibility, when he says that “data protection is absolutely part of the CISO’s job. For this reason, smart CISOs are making sure that analytics and AI teams have data security in mind and are using secure data platforms.
The data warehouse and analyticaldata stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. This led me to Sanjeev Mohan.
The value of a data catalog means something different to each of these companies — meaning they will each expect something different out of its implementation. In fact, they likely have different definitions of what a data catalog even is. How do you define a data catalog? How do you derive value from a data catalog?
Reichental describes data governance as the overarching layer that empowers people to manage data well ; as such, it is focused on roles & responsibilities, policies, definitions, metrics, and the lifecycle of the data. In this way, data governance is the business or process side.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. About the authors Aruna Abeyakoon is the Senior Director of Data Science & Analytics at Light & Wonder Land-based Gaming Division.
Understanding Data Warehouse Functionality A data warehouse acts as a central repository for historical data extracted from various operational systems within an organization. This allows businesses to analyze trends, identify patterns, and make informed decisions based on historical data.
You’ll start by demystifying what vector databases are, with clear definitions, simple explanations, and real-world examples of popular vector databases. You will also gain a practical understanding of how vector databases work, including the processes involved in storing, retrieving, and managing data in high-dimensional vector spaces.
The first two use cases are primarily aimed at a technical audience, as the lineage definitions apply to actual physical assets. Data is touched and manipulated by a myriad of solutions, including on-premises and cloud transformation tools, databases and datalake houses.
Data discovery is also critical for data governance , which, when ineffective, can actually hinder organizational growth. And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. 8 Critical Analytics Tools for Cloud Environments. Predictive Transformation.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. This structured approach ensures that data moves efficiently through each stage, undergoing necessary modifications to become usable for analytics or other applications.
The Datamarts capability opens endless possibilities for organizations to achieve their dataanalytics goals on the Power BI platform. A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle. What is a Datamart?
For any data user in an enterprise today, data profiling is a key tool for resolving data quality issues and building new data solutions. In this blog, we’ll cover the definition of data profiling, top use cases, and share important techniques and best practices for data profiling today.
You can integrate existing data from AWS datalakes, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) instances with services such as Amazon Bedrock and Amazon Q. Role context – Start each prompt with a clear role definition.
Whether you’re building a team for master data management (MDM), implementing a composable customer data platform (CDP), or just having challenges identifying the unique customers for your analytical use cases—understanding the fundamentals of identity resolution will guide you in making the best decision possible for your organization.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content