This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! REGISTER Ready to get started?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding? You’ll use Python, end of story.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! For more details, see the Agent Bricks deep dive blog.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! REGISTER Ready to get started?
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! Join now Ready to get started?
Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. Thus, we use an Extract-Transform-Load (ETL) process to ingest the data.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
It also supports a wide range of data warehouses, analytical databases, data lakes, frontends, and pipelines/ETL. Support for Various Data Warehouses and Databases : AnalyticsCreator supports MS SQL Server 2012-2022, Azure SQL Database, Azure Synapse Analytics dedicated, and more. Data Lakes : It supports MS Azure Blob Storage.
By the end of this blog, you will also be able to understand how Snowflake […]. The post Snowflake Architecture & Key Concepts for Data Warehouse appeared first on Analytics Vidhya.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Error Handling Patterns in Python (Beyond Try-Except) Stop letting errors crash your app.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! REGISTER Ready to get started?
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
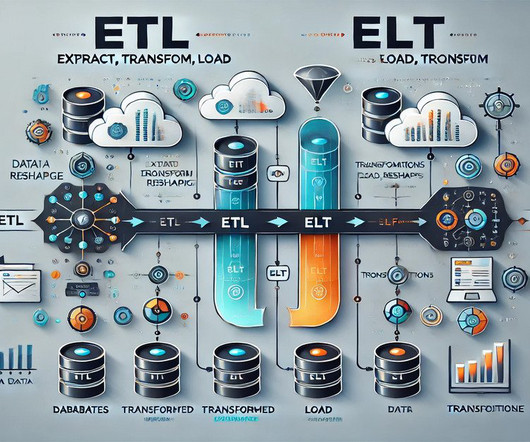
Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. The remote engine allows ETL/ELT jobs to be designed once and run anywhere.
This blog covers the top 20 data warehouse interview questions that you should be well-versed in, along with detailed explanations to help you prepare effectively. Familiarise yourself with ETL processes and their significance. ETL Process: Extract, Transform, Load processes that prepare data for analysis.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. This blog explores the fundamental concepts of ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform), two pivotal methods in modern data architectures. What is ETL?
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! New Podcast Episode: The AI-Powered Analyst: Skills You Need to StayRelevant In this episode of ODSCs Ai X Podcast, we explore how AI is revolutionizing analytics, decision-making, and careerpaths.
Traditionally, data transformation was relegated to specialized engineering teams employing complex extract, transform, and load (ETL) processes using highly complex tooling and code. […] The post How to Achieve Self-Service Data Transformation for AI and Analytics appeared first on DATAVERSITY.
In the contemporary age of Big Data, Data Warehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
In the data analytics processes, choosing the right tools is crucial for ensuring efficiency and scalability. Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration. Today we will focus on Snowflake as our cloud product.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed data engine Daft [link] is open-sourced and runs on 800k CPU cores daily.
She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management. He has experience across analytics, big data, and ETL. He has experience across analytics, big data, and ETL. Akchhaya Sharma is a Sr. Data Engineer at Amazon Ads.
Up until recently, feedback forms and […] The post How Reverse ETL Powers Modern Customer Marketing: Concrete Examples appeared first on DATAVERSITY. If you’re part of a customer marketing team, you know that most people would say “not very often.” This is precisely the plight of the average customer marketer.
The post How to Plan a Threat Hunt: Using Log Analytics to Manage Data in Depth appeared first on DATAVERSITY. Only 46% of security operations leaders are satisfied with their team’s ability to detect threats, and 82% of decision-makers report that their responses to threats […].
IBM watsonx.data facilitates scalable analytics and AI endeavors by accommodating data from diverse sources, eliminating the need for migration or cataloging through open formats. This approach enables centralized access and sharing while minimizing extract, transform and load (ETL) processes and data duplication.
To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities. Data engineers can create and manage extract, transform, and load (ETL) pipelines directly within Unified Studio using Visual ETL.
Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. As AI and analytics use cases converge, transform how data teams work together with SageMaker Unified Studio.
This proactive approach helps maintain optimal system performance, ensuring users execute analytical queries efficiently and deliver insights without delay. This process replaces sensitive data with realistic but fictional data, ensuring that privacy is maintained while still allowing data to be used for development, testing, or analytics.
This blog post explores effective strategies for gathering requirements in your data project. Example: For a project to optimize supply chain operations, the scope might include creating dashboards for inventory tracking but exclude advanced predictive analytics in the first phase. Key questions to ask: What data sources are required?
If you ever wonder how predictions and forecasts are made based on the raw data collected, stored, and processed in different formats by website feedback, customer surveys, and media analytics, this blog is for you. To learn more about visualizations, you can refer to one of our many blogs on data visualization for a glance.
Summary: Choosing the right ETL tool is crucial for seamless data integration. At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. What is ETL?
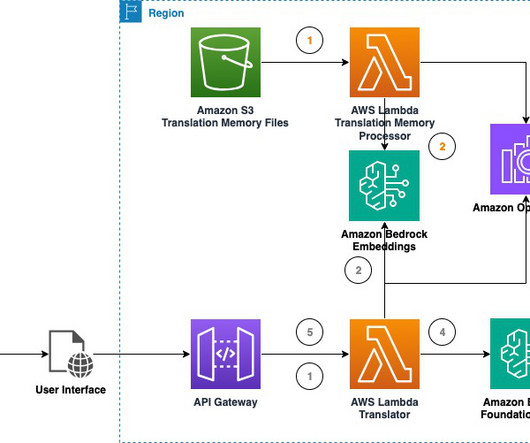
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. This involves extract, transform, and load (ETL) pipelines able to parse the XML structure, handle encoding issues, and add metadata.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. The post A Look Inside the Modern Analytics Stack appeared first on DATAVERSITY.
The machine sensor data can be monitored directly in real time via respective data pipelines (real-time stream analytics) or brought into an overall picture of aggregated key figures (reporting). The post How Cloud Data Platforms improve Shopfloor Management appeared first on Data Science Blog. Then get in touch with me!
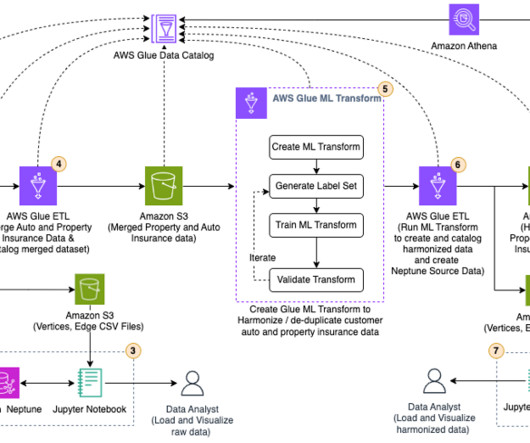
These sources are often related but use different naming conventions, which will prolong cleansing, slowing down the data processing and analytics cycle. Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. This will open the ML transforms page.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics. Real-time analytics has real-time benefits.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. It enables secure data sharing for analytics and AI across your ecosystem.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Data refinement: Raw data is refined into consumable layers (raw, processed, conformed, and analytical) using a combination of AWS Glue extract, transform, and load (ETL) jobs and EMR jobs.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
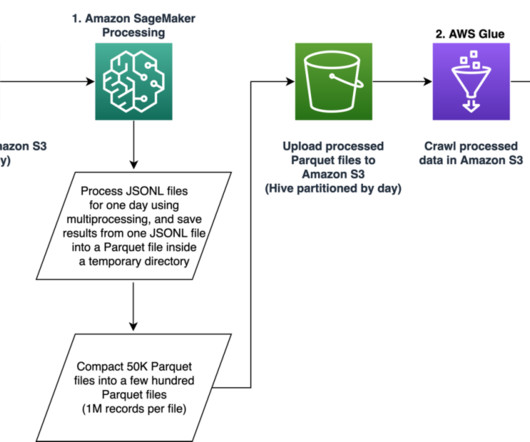
This post is co-written with Suhyoung Kim, General Manager at KakaoGames Data Analytics Lab. To solve this problem, we build an extract, transform, and load (ETL) pipeline that can be run automatically and repeatedly for training and inference dataset creation. But there is still an engineering challenge.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content