This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Discover the ultimate guide to building a powerful datapipeline on AWS! In today’s data-driven world, organizations need efficient pipelines to collect, process, and leverage valuable data. With AWS, you can unleash the full potential of your data.
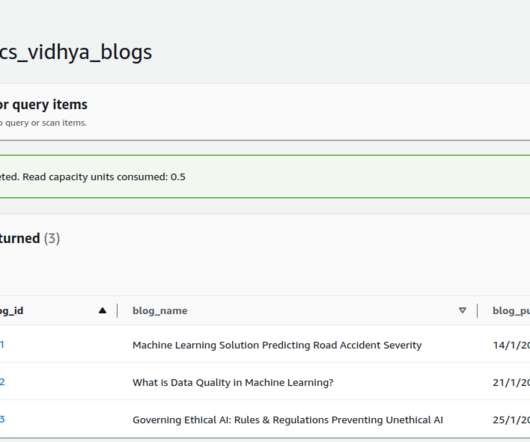
This article was published as a part of the Data Science Blogathon. Introduction In this blog, we will explore one interesting aspect of the pandas read_csv function, the Python Iterator parameter, which can be used to read relatively large input data.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
We are proud to announce two new analyst reports recognizing Databricks in the data engineering and data streaming space: IDC MarketScape: Worldwide Analytic.
🔗 Link to the code on GitHub Why Data Cleaning Pipelines? Think of datapipelines like assembly lines in manufacturing. Wrapping Up Datapipelines arent just about cleaning individual datasets. Each step performs a specific function, and the output from one step becomes the input for the next.
Artificial intelligence (AI) and natural language processing (NLP) technologies are evolving rapidly to manage live data streams. They power everything from chatbots and predictive analytics to dynamic content creation and personalized recommendations.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis.
Scheduled Analysis Replace the Manual Trigger with a Schedule Trigger to automatically analyze datasets at regular intervals, perfect for monitoring data sources that update frequently. This proactive approach helps you identify datapipeline issues before they impact downstream analysis or model performance.
Data must be combined and harmonized from multiple sources into a unified, coherent format before being used with AI models. Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. This process is known as data integration, one of the key components to a strong data fabric.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Orchestration platform Orq noted in a blog post that AI management systems include four key components: prompt management for consistent model interaction, integration tools, state management and monitoring tools to track performance. What do they need the AI application or agents to do, and how are these planned to support their work?
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
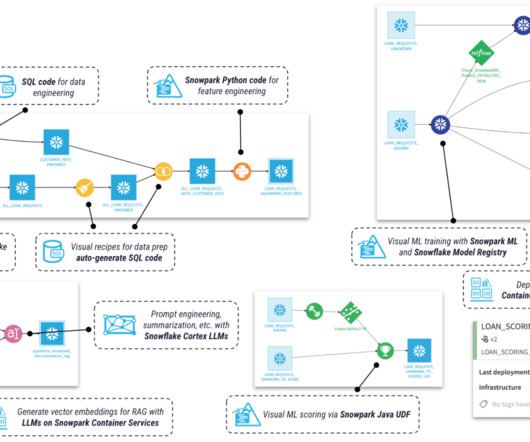
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
The modern data stack is defined by its ability to handle large datasets, support complex analytical workflows, and scale effortlessly as data and business needs grow. Two key technologies that have become foundational for this type of architecture are the Snowflake AI Data Cloud and Dataiku.
The machine sensor data can be monitored directly in real time via respective datapipelines (real-time stream analytics) or brought into an overall picture of aggregated key figures (reporting). Or maybe you are interested in an individual data strategy ? material flow analysis) for manufacturing and supply chain.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. With QuickSight, all users can meet varying analytic needs from the same source of truth through modern interactive dashboards, paginated reports, embedded analytics, and natural language queries.
Summary: “Data Science in a Cloud World” highlights how cloud computing transforms Data Science by providing scalable, cost-effective solutions for big data, Machine Learning, and real-time analytics. Advancements in data processing, storage, and analysis technologies power this transformation.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. You’ll use this file when setting up your function to query sales data.
Almost a year ago, IBM encountered a data validation issue during one of our time-sensitive mergers and acquisitions data flows. These changes impact workflows, which in turn affect downstream datapipeline processing, leading to a ripple effect.
Companies are spending a lot of money on data and analytics capabilities, creating more and more data products for people inside and outside the company. These products rely on a tangle of datapipelines, each a choreography of software executions transporting data from one place to another.
Understanding customer satisfaction and areas needing improvement from raw data is complex and often requires advanced analytical tools. He has successfully led numerous client engagements to deliver dataanalytics and AI/machine learning solutions.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements. ETL is one of the most integral processes required by Business Intelligence and Analytics use cases since it relies on the data stored in Data Warehouses to build reports and visualizations.
If you ever wonder how predictions and forecasts are made based on the raw data collected, stored, and processed in different formats by website feedback, customer surveys, and media analytics, this blog is for you. To learn more about visualizations, you can refer to one of our many blogs on data visualization for a glance.
However, a data lake functions for one specific company, the data warehouse, on the other hand, is fitted for another. This blog will reveal or show the difference between the data warehouse and the data lake. Data Warehouse. Engineers make use of data lakes in storing incoming data.
Leaders feel the pressure to infuse their processes with artificial intelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement. Indeed, IDC has predicted that by the end of 2024, 65% of CIOs will face pressure to adopt digital tech , such as generative AI and deep analytics.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service.
KNIME , a popular open-source dataanalytics, reporting, and integration platform, offers an excellent solution for implementing low-barrier yet high-value automations that many businesses will find useful with its Business Hub. This platform allows users to create, share, and manage data workflows effortlessly across teams.
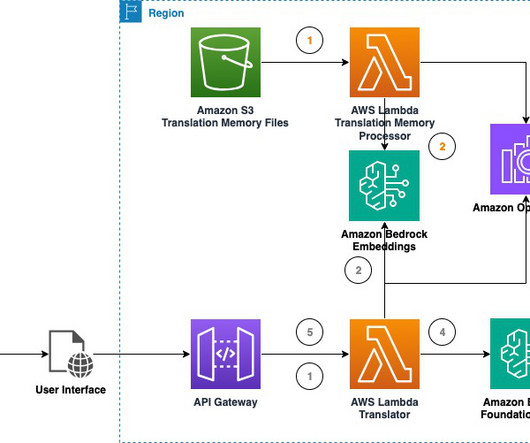
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. It can help collect more data on the value of LLMs for your content translation use cases. He helps customers in the Northeast U.S.
How to Optimize Power BI and Snowflake for Advanced Analytics Spencer Baucke May 25, 2023 The world of business intelligence and data modernization has never been more competitive than it is today. Much of what is discussed in this guide will assume some level of analytics strategy has been considered and/or defined. No problem!
This following diagram illustrates the enhanced data extract, transform, and load (ETL) pipeline interaction with Amazon Bedrock. To achieve the desired accuracy in KPI calculations, the datapipeline was refined to achieve consistent and precise performance, which leads to meaningful insights.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics.
In this blog, we will explore the top 10 AI jobs and careers that are also the highest-paying opportunities for individuals in 2024. Big data engineer Potential pay range – US$206,000 to 296,000/yr They operate at the backend to build and maintain complex systems that store and process the vast amounts of data that fuel AI applications.
Alteryx and the Snowflake Data Cloud offer a potential solution to this issue and can speed up your path to Analytics. In this blog post, we will explore how Alteryx and Snowflake can accelerate your journey to Analytics by sharing use cases and best practices. What is Alteryx? What is Snowflake?
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
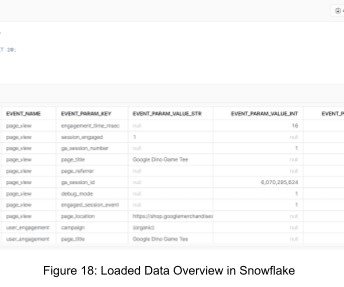
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw event data from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
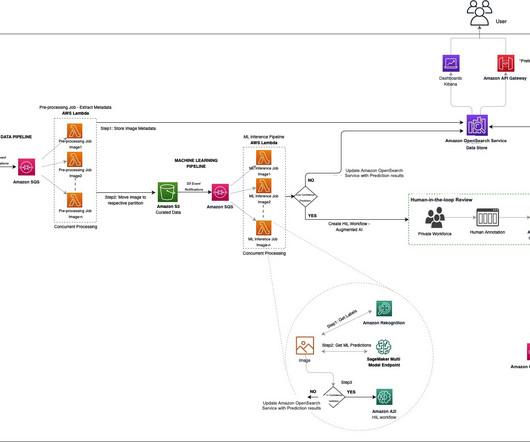
Solution overview In brief, the solution involved building three pipelines: Datapipeline – Extracts the metadata of the images Machine learning pipeline – Classifies and labels images Human-in-the-loop review pipeline – Uses a human team to review results The following diagram illustrates the solution architecture.
Increased datapipeline observability As discussed above, there are countless threats to your organization’s bottom line. That’s why datapipeline observability is so important. Realize the benefits of automated data lineage today. Schedule a demo with a MANTA engineer to learn more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content