This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
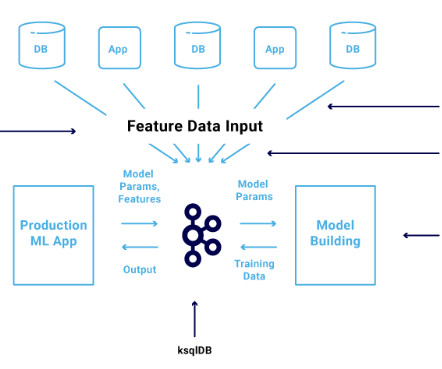
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
It offers full BI-Stack Automation, from source to data warehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models. It also supports a wide range of data warehouses, analytical databases, datalakes, frontends, and pipelines/ETL.
Recently we’ve seen lots of posts about a variety of different file formats for datalakes. There’s Delta Lake, Hudi, Iceberg, and QBeast, to name a few. It can be tough to keep track of all these datalake formats — let alone figure out why (or if!) And I’m curious to see if you’ll agree.
The post DataLakes for Non-Techies appeared first on DATAVERSITY. Moreover, complex usability helped in developing a network of certified (aka expensive and lucrative) consultancy workforce. IT has recently experienced […].
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
Among these, four primary use cases have emerged as especially prominent: intelligent process automation, anomaly detection, analytics, and operational assistance. Different types of data typically require different tools to access them. Cross account calls arent supported at the time of writing this blog.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “datalake.” While data warehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between DataLakes and Data Warehouses appeared first on DATAVERSITY.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. The Rise of the Data Catalog.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
… and your data warehouse / datalake / data lakehouse. A few months ago, I talked about how nearly all of our analytics architectures are stuck in the 1990s. Maybe an executive at your company read that article, and now you have a mandate to “modernize analytics.”
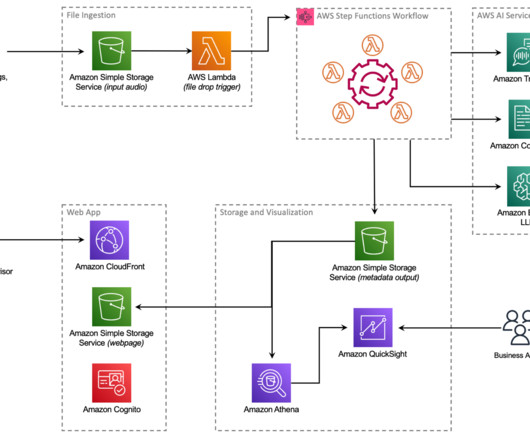
Principal is conducting enterprise-scale near-real-time analytics to deliver a seamless and hyper-personalized omnichannel customer experience on their mission to make financial security accessible for all. They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. Without business context, business users are less likely to use the datalake and insights will be hard to come by.
The data being talked about is useful for businesses to draw insights, formulate strategies, and understand trends and customer behavior, among others. […]. The post Maximize the ROI of Your Enterprise DataLake appeared first on DATAVERSITY.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? The most used open table formats currently are Apache Iceberg, Delta Lake, and Apache Hudi.
Most industries have seen tremendous change due to the pandemic over the past two years, which has brought new and ever-evolving data that businesses need to make sense of. The post Three Ways DataAnalytics Will Progress in 2022 and Beyond appeared first on DATAVERSITY.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
But what most people don’t realize is that behind the scenes, Uber is not just a transportation service; it’s a data and analytics powerhouse. Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. Consider the magnitude of Uber’s footprint.
This blog was originally written by Keith Smith and updated for 2024 by Justin Delisi. Snowflake’s Data Cloud has emerged as a leader in cloud data warehousing. What is a DataLake? A DataLake is a location to store raw data that is in any format that an organization may produce or collect.
Managing, storing, and processing data is critical to business efficiency and success. Modern data warehousing technology can handle all data forms. Significant developments in big data, cloud computing, and advanced analytics created the demand for the modern data warehouse.
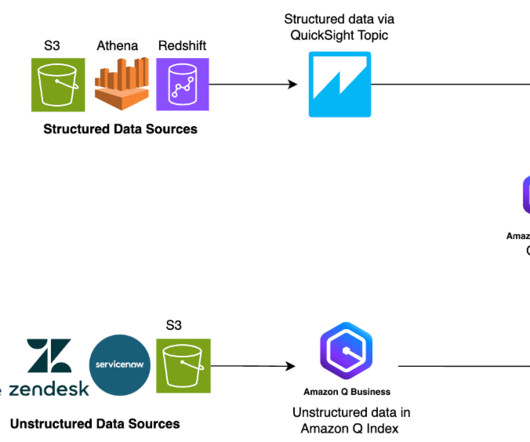
Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
Most enterprises today store and process vast amounts of data from various sources within a centralized repository known as a data warehouse or datalake, where they can analyze it with advanced analytics tools to generate critical business insights.
The proliferation of data silos also inhibits the unification and enrichment of data which is essential to unlocking the new insights. Moreover, increased regulatory requirements make it harder for enterprises to democratize data access and scale the adoption of analytics and artificial intelligence (AI).
A lot of people in our audience are looking at implementing datalakes or are in the middle of big datalake initiatives. I know in February of 2017 Munich Re launched their own innovative platform as a cornerstone for analytics that involved a big datalake and a data catalog.
Whether it’s data management, analytics, or scalability, AWS can be the top-notch solution for any SaaS company. Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps.
Another IDC study showed that while 2/3 of respondents reported using AI-driven dataanalytics, most reported that less than half of the data under management is available for this type of analytics. from 2022 to 2026.
The problem statement sought to harness the combination of Caltrans’ asset, crash, and points-of-interest (POI) data and INRIX’s 50 petabyte (PB) datalake to anticipate high-risk locations and quickly generate empirically validated safety measures to mitigate the potential for crashes.
Were seeing a remarkable convergence of data, analytics, and generative AI. With the next generation of Amazon SageMaker announced at re:Invent, were introducing an integrated experience to access, govern, and act on all your data by bringing together widely adopted AWS data, analytics, and AI capabilities.
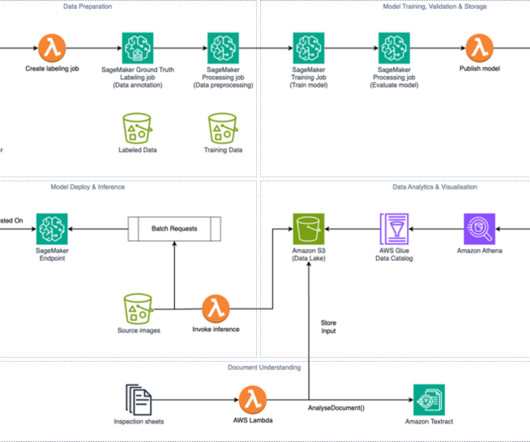
Amazon Simple Storage Service (Amazon S3) stores the model artifacts and creates a datalake to host the inference output, document analysis output, and other datasets in CSV format. The model is then trained using a fully managed infrastructure, validated, and published to the Amazon SageMaker Model Registry.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
To achieve the desired accuracy in KPI calculations, the data pipeline was refined to achieve consistent and precise performance, which leads to meaningful insights. At this point, it became possible for the calculator agent to forego the Pandas or Spark data processing implementation.
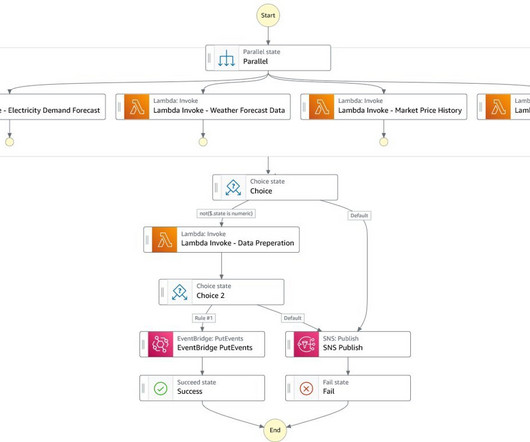
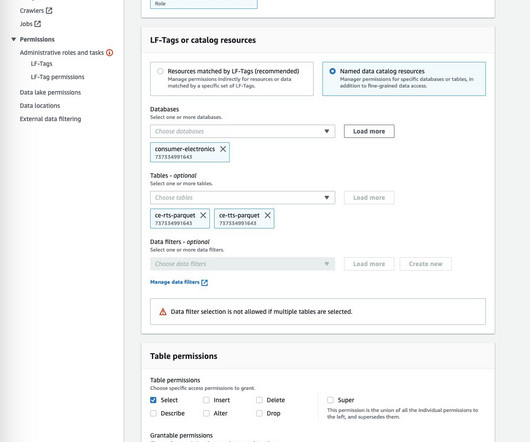
In this post, we describe how to query Parquet files with Athena using AWS Lake Formation and use the output Canvas to train a model. Solution overview Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open table and file formats. Create a datalake with Lake Formation.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
Usage of data is tracked through the data consumers, such as Amazon Athena , Amazon Redshift , or Amazon SageMaker. AWS Lake Formation – AWS Lake Formation helps manage datalakes and integrate them with other AWS analytics services.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content