This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The post AWS Redshift: Cloud DataWarehouse Service appeared first on Analytics Vidhya.
Introduction Source – pexels.com Are you struggling to manage and analyze large amounts of data? Are you looking for a cost-effective and scalable solution for your datawarehouse needs? Look no further than AWS Redshift. AWS Redshift is a fully managed, petabyte-scale datawarehouse […].
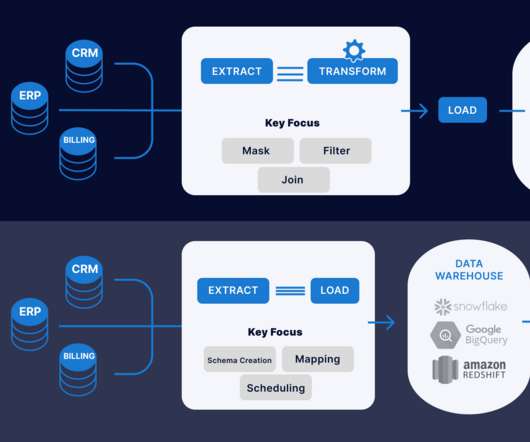
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
AWS’ Legendary Presence at DAIS: Customer Speakers, Featured Breakouts, and Live Demos! Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse service that makes it cost-effective to efficiently analyze all your data using your existing business intelligence tools. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A SageMaker domain. Choose Create stack.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
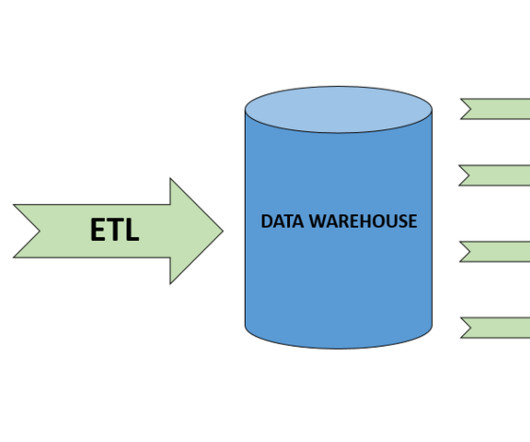
Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
Introduction Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a datawarehouse in the cloud.
It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. Traditionally, ETL processes are […].
Businesses have adopted Snowflake as migration from on-premise enterprise datawarehouses (such as Teradata) or a more flexibly scalable and easier-to-manage alternative to […]. The post Data Warehousing with Snowflake and Other Alternatives appeared first on Analytics Vidhya.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Introduction Amazon Elastic MapReduce (EMR) is a fully managed service that makes it easy to process large amounts of data using the popular open-source framework Apache Hadoop. EMR enables you to run petabyte-scale datawarehouses and analytics workloads using the Apache Spark, Presto, and Hadoop ecosystems.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
In just under 60 minutes, we had a working agent that can transform complex unstructured data usable for Analytics.” — Joseph Roemer, Head of Data & AI, Commercial IT, AstraZeneca “Agent Bricks allowed us to build a cost-effective agent we could trust in production. Agent Bricks is now available in beta.
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a Machine Learning Model in BigQuery appeared first on Analytics Vidhya.
The modern corporate world is more data-driven, and companies are always looking for new methods to make use of the vast data at their disposal. Cloud analytics is one example of a new technology that has changed the game. What is cloud analytics? How does cloud analytics work?
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
They sit outside the analytics and AI stack, require manual integration, and lack the flexibility needed for modern development workflows. Lakehouse integration : Lakebases should make it easy to combine operational, analytical, and AI systems without complex ETL pipelines.
Figure 1: Agent Bricks auto-optimizes agents for your data and task MLflow 3.0 Agents deployed on AWS, GCP, or even on-premise systems can now be connected to MLflow 3 for agent observability. Now with MLflow 3, you can monitor and observe agents that are deployed anywhere , even outside of Databricks.
The workflow includes the following steps: Within the SageMaker Canvas interface, the user composes a SQL query to run against the GCP BigQuery datawarehouse. Athena uses the Athena Google BigQuery connector , which uses a pre-built AWS Lambda function to enable Athena federated query capabilities.
Businesses globally recognize the power of generative AI and are eager to harness data and AI for unmatched growth, sustainable operations, streamlining and pioneering innovation. In this quest, IBM and AWS have forged a strategic alliance, aiming to transition AI’s business potential from mere talk to tangible action.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use datawarehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. In this article, we’ll focus on a data lake vs. datawarehouse.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
improved document management capabilities, web portals, mobile applications, datawarehouses, enhanced location services, etc.) Why IBM Consulting and AWS? AWS has the biggest cloud infrastructure services vendor market share worldwide, averaging around 33% as of Q4 2022.
While not all of us are tech enthusiasts, we all have a fair knowledge of how Data Science works in our day-to-day lives. All of this is based on Data Science which is […]. The post Step-by-Step Roadmap to Become a Data Engineer in 2023 appeared first on Analytics Vidhya.
To make these processes efficient, data pipelines are necessary. Data engineers specialize in building and maintaining these data pipelines that underpin the analytics ecosystem. In this blog, we will […] The post How to Implement a Data Pipeline Using Amazon Web Services?
The post How to Encrypt and Decrypt the Data in PySpark? appeared first on Analytics Vidhya. To access services, we need to share essential details like email IDs, phone numbers, social security numbers, etc. These details can get leaked if the […].
This post was co-authored by Brian Curry (Founder and Head of Products at OCX Cognition) and Sandhya MN (Data Science Lead at InfoGain) OCX Cognition is a San Francisco Bay Area-based startup, offering a commercial B2B software as a service (SaaS) product called Spectrum AI. This reduced the need to develop new low-level ML code.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
We recently wrapped up participation in the all-virtual AWS re:Invent 2020 where we shared our experiences from scaling Tableau Public ten-fold this year. This includes offering broader access to data and analytics and embracing the cloud to better adapt, innovate, and grow more resilient while facing the unexpected.
The transformation process occurs outside the target, a separate processing tool or […] The post Unlock the True Potential of Your Data with ETL and ELT Pipeline appeared first on Analytics Vidhya.
Most enterprises today store and process vast amounts of data from various sources within a centralized repository known as a datawarehouse or data lake, where they can analyze it with advanced analytics tools to generate critical business insights.
Overall, data pipelines are a critical component of any data-driven organization, helping to ensure […] The post Top 10 Data Pipeline Interview Questions to Read in 2023 appeared first on Analytics Vidhya.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. It provides a single web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. Conclusion.
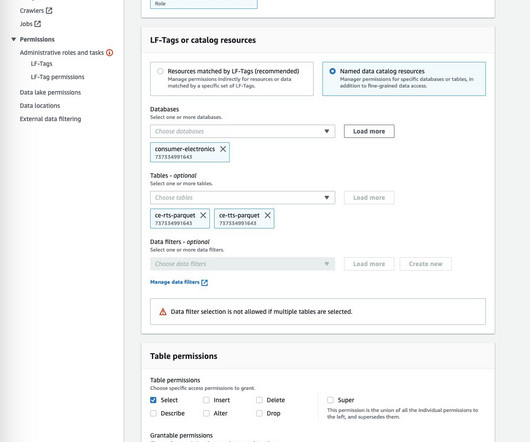
This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. Choose Grant.
IBM today announced it is launching IBM watsonx.data , a data store built on an open lakehouse architecture, to help enterprises easily unify and govern their structured and unstructured data, wherever it resides, for high-performance AI and analytics. The solution will also be available in AWS Marketplace.
Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift datawarehouses. An SSL certificate created and imported into AWS Certificate Manager (ACM).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content