This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon Overview: Machine Learning (ML) and data science applications are in high demand. When MLalgorithms offer information before it is known, the benefits for business are significant. The MLalgorithms, on […].
ML Interpretability is a crucial aspect of machine learning that enables practitioners and stakeholders to trust the outputs of complex algorithms. What is ML interpretability? To fully grasp ML interpretability, it’s helpful to understand some core definitions.
The world’s leading publication for data science, AI, and ML professionals. You don’t need deep ML knowledge or tuning skills. Why Automate ML Model Selection? Identify top-performing algorithms based on accuracy, F1 score, or RMSE. It’s not just convenient, it’s smart ML hygiene. These are lazypredict and pycaret.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
Our work further motivates novel directions for developing and evaluating tools to support human-ML interactions. Model explanations have been touted as crucial information to facilitate human-ML interactions in many real-world applications where end users make decisions informed by ML predictions.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
In their quest for effectiveness and well-informed decision-making, businesses continually search for new ways to collect information. In the field of AI and ML, QR codes are incredibly helpful for improving predictive analytics and gaining insightful knowledge from massive data sets.
Introduction Intelligent document processing (IDP) is a technology that uses artificial intelligence (AI) and machine learning (ML) to automatically extract information from unstructured documents such as invoices, receipts, and forms.
ML scalability is a crucial aspect of machine learning systems, particularly as data continues to grow exponentially. Organizations depend on scalable models to harness insights from vast datasets, making timely and informed decisions that can significantly impact their success. What is ML scalability?
ML diagnostics encompasses a range of evaluation techniques aimed at ensuring machine learning models perform at their best. What are ML diagnostics? ML diagnostics refers to the processes used for assessing and enhancing the performance of machine learning models.
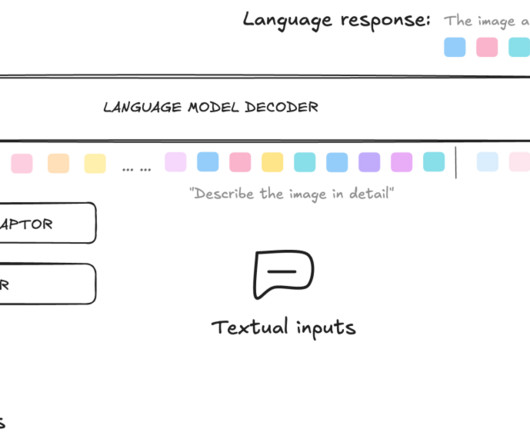
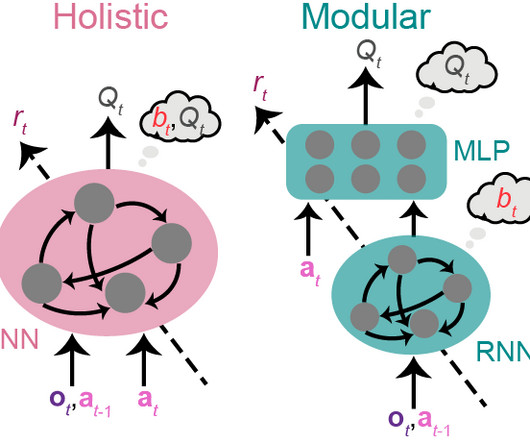
We would instead want a robust model that is able to generalize to new, unseen problems by trying multiple approaches and seeking information to different extents, or expressing uncertainty when it is fully unable to fully solve a problem. Figure 2: Examples of two algorithms and the corresponding stream of tokens generated by each algorithm.
Agent Bricks is optimized for common industry use cases, including structured information extraction, reliable knowledge assistance, custom text transformation, and orchestrated multi-agent systems. We auto-optimize over the knobs, gain confidence that you are on the most optimized settings. ignore all data before May 1990).
Machine learning models are algorithms designed to identify patterns and make predictions or decisions based on data. Modern businesses are embracing machine learning (ML) models to gain a competitive edge. Since the impact and use of AI are growing drastically, it makes ML models a crucial element for modern businesses.
AI/ML model validation plays a crucial role in the development and deployment of machine learning and artificial intelligence systems. What is AI/ML model validation? AI/ML model validation is a systematic process that ensures the reliability and accuracy of machine learning and artificial intelligence models.
Machine learning is a branch of artificial intelligence that focuses on developing algorithms and models that can learn from data and make predictions or decisions without being explicitly programmed. There are various types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning.
Drag and drop tools have revolutionized the way we approach machine learning (ML) workflows. Gone are the days of manually coding every step of the process – now, with drag-and-drop interfaces, streamlining your ML pipeline has become more accessible and efficient than ever before. H2O.ai H2O.ai
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (Natural Language Processing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. To address these inefficiencies, the implementation of advanced information extraction systems is crucial.
This technology employs machine vision and artificial intelligence (AI) to decipher visual information, making it indispensable across numerous fields. Despite these limitations, advancements in algorithms have propelled the capability of machines to recognize patterns and objects more accurately.
With the most recent developments in machine learning , this process has become more accurate, flexible, and fast: algorithms analyze vast amounts of data, glean insights from the data, and find optimal solutions. Image credit: economicsdiscussion.net The Transformation with ML The dynamic pricing landscape is very different now.
From an enterprise perspective, this conference will help you learn to optimize business processes, integrate AI into your products, or understand how ML is reshaping industries. Machine Learning & Deep Learning Advances Gain insights into the latest ML models, neural networks, and generative AI applications.
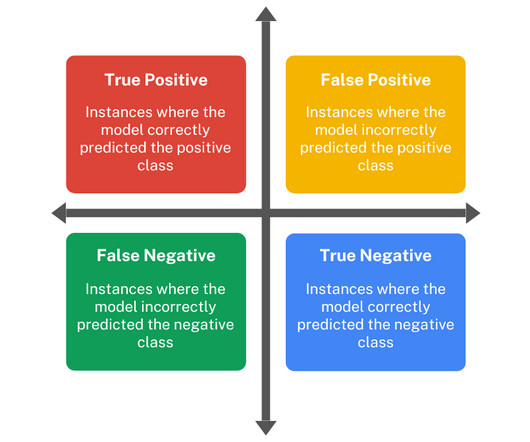
This powerful yet simple concept helps data scientists and machine learning practitioners assess the accuracy of classification algorithms , providing insights into how well a model is performing in predicting various classes. One of the most fundamental tools for this purpose is the confusion matrix.
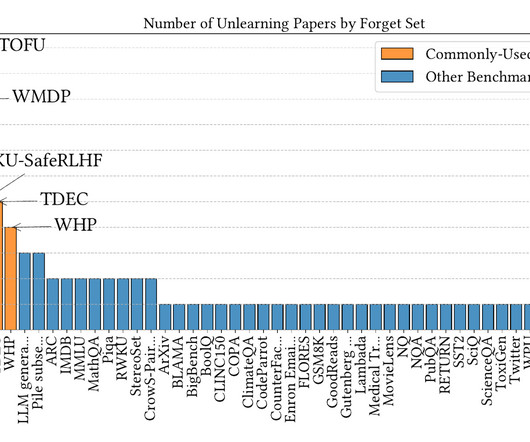
We show that such benchmarks do not provide an accurate measure of whether or not unlearning has occurred, making it difficult to evaluate whether new algorithms are truly making progress on the problem of unlearning. A forget set of evaluation queries that are meant to test access to unlearned information. Finding #1: TOFU.
It makes machine learning (ML) a critical component of data science where algorithms are statistically trained on data. An ML model learns iteratively to make accurate predictions and take actions. Technological advancement has resulted in highly sophisticated algorithms that require enhanced strategies for training models.
Golden datasets play a pivotal role in the realms of artificial intelligence (AI) and machine learning (ML). They provide a foundation for training algorithms, ensuring that models can make accurate decisions and predictions. It is particularly valuable in AI and ML environments, where precision and reliability are paramount.
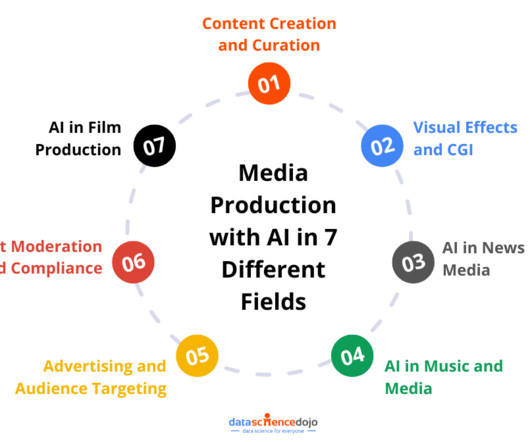
By leveraging AI-powered algorithms, media producers can improve production processes and enhance creativity. Some key benefits of integrating the production process with AI are as follows: Personalization AI algorithms can analyze user data to offer personalized recommendations for movies, TV shows, and music.
The agency wanted to use AI [artificial intelligence] and ML to automate document digitization, and it also needed help understanding each document it digitizes, says Duan. The demand for modernization is growing, and Precise can help government agencies adopt AI/ML technologies.
There is no doubt that machine learning (ML) is transforming industries across the board, but its effectiveness depends on the data it’s trained on. The ML models traditionally rely on real-world datasets to power the recommendation algorithms, image analysis, chatbots, and other innovative applications that make it so transformative.
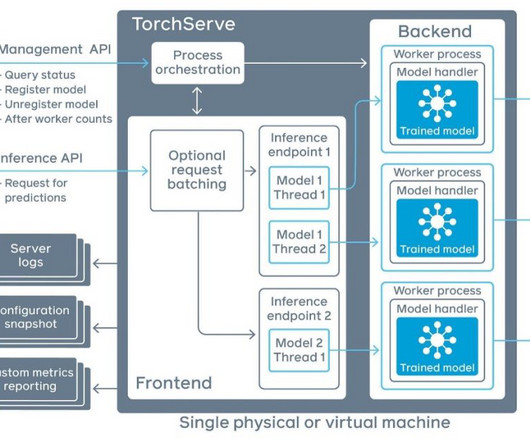
Amazon SageMaker AI provides a fully managed service for deploying these machine learning (ML) models with multiple inference options, allowing organizations to optimize for cost, latency, and throughput. invocations is the endpoint that receives client inference POST The format of the request and the response is up to the algorithm.
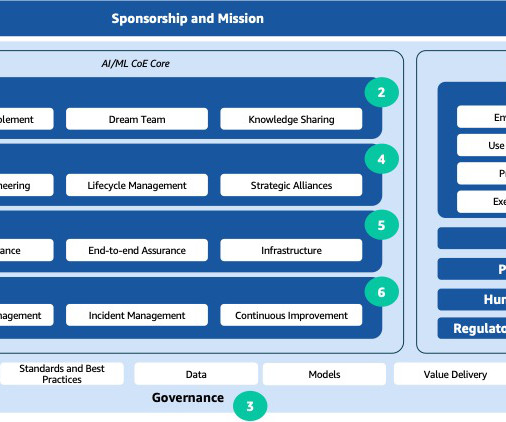
The rapid advancements in artificial intelligence and machine learning (AI/ML) have made these technologies a transformative force across industries. An effective approach that addresses a wide range of observed issues is the establishment of an AI/ML center of excellence (CoE). What is an AI/ML CoE?
AI provides engineers with a powerful toolset to make more informed decisions and enhance their interactions with the digital world. It replaces complex algorithms with neural networks, streamlining and accelerating the predictive process. Techniques Uses statistical models, machine learning algorithms, and data mining.
ML architecture forms the backbone of any effective machine learning system, shaping how it processes data and learns from it. A well-structured architecture ensures that the system can handle vast amounts of information efficiently, delivering accurate predictions and insights. What is ML architecture?
Machine Learning (ML) is a powerful tool that can be used to solve a wide variety of problems. Getting your ML model ready for action: This stage involves building and training a machine learning model using efficient machine learning algorithms. This information can be used to inform the design of the model.
Onity processes millions of pages across hundreds of document types annually, including legal documents such as deeds of trust where critical information is often contained within dense text. Solution overview To address these document processing challenges, Onity built an intelligent solution combining AWS AI/ML and generative AI services.
Retrieval-Augmented Generation (RAG) In advanced systems, embeddings are used to retrieve relevant information from external datasets during the text generation process. Hence, it is a smart way to find information by looking at the meaning behind data instead of exact keywords.
Creating high-quality product listings on Amazon.com Creating high-quality product listings with comprehensive details helps customers make informed purchase decisions. For new listings, the workflow begins with selling partners providing initial information. Generated listings are shared with selling partners for approval or editing.
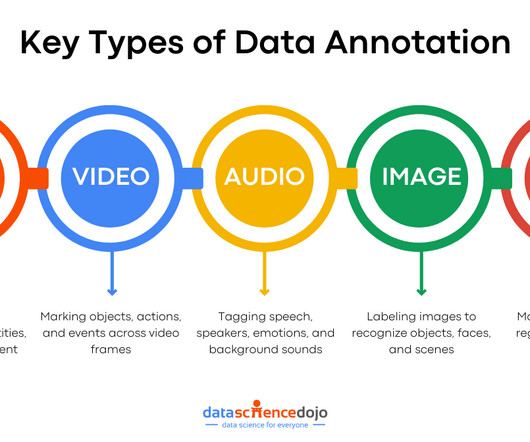
These models are trained using vast datasets and powered by sophisticated algorithms. Data annotation is the process of labeling data to make it understandable and usable for machine learning (ML) models. It enables AI systems to recognize patterns, understand them, and make informed predictions.
Using Amazon Bedrock Knowledge Bases, FMs and agents can retrieve contextual information from your company’s private data sources for RAG. It supports exact and approximate nearest-neighbor algorithms and multiple storage and matching engines. For information on creating service roles, refer to Service roles. Choose Next.
Extractive summarization: The extractive summarization process employs the TextRank algorithm, powered by sumy and NLTK libraries, to identify and extract the most significant sentences from source documents. The process specifically focuses on the first 1,500 characters of each document, where author information typically appears.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. We provide detailed information and GitHub examples for this new SageMaker capability. We discuss this in Part 2.
By the end of this post, you should know the general pipeline to train any model with any instruction dataset using the RLHF algorithm of your choice! Training Algorithm: REBEL , a state-of-the-art algorithm tailored for efficient RLHF optimization. The detailed derivations of the algorithm are shown in our paper.
It usually comprises parsing log data into vectors or machine-understandable tokens, which you can then use to train custom machine learning (ML) algorithms for determining anomalies. You can adjust the inputs or hyperparameters for an MLalgorithm to obtain a combination that yields the best-performing model.
In practice, our algorithm is off-policy and incorporates mechanisms such as two critic networks and target networks as in TD3 ( fujimoto et al., 2018 ) to enhance training (see Materials and Methods in Zhang et al.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content