This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
KNN (K-NearestNeighbors) is a versatile algorithm widely employed in machine learning, particularly for challenges involving classification and regression. What is KNN (K-NearestNeighbors)? Understanding these can help professionals make informed decisions on when to use this algorithm.
In other words, neighbors play a major part in our life. Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. What is KNearestNeighbor? Benefits of k-NN for GIS 1.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! It’s like having a super-powered tool to sort through information and make better sense of the world. Learn in detail about machine learning algorithms 2.
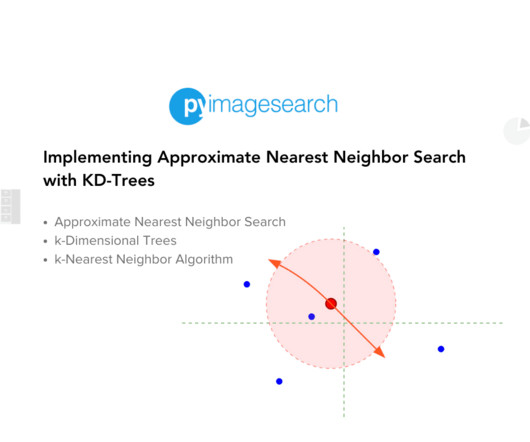
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
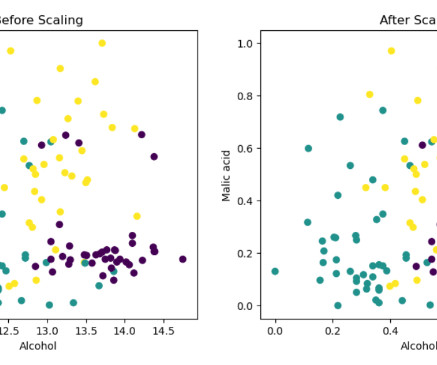
These features can be used to improve the performance of Machine Learning Algorithms. By manipulating the input features of a dataset, we can enhance their quality, extract meaningful information, and improve the performance of predictive models. This dataset includes four input features: User ID, Gender, Age, and Salary.
Machine learning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificial intelligence.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
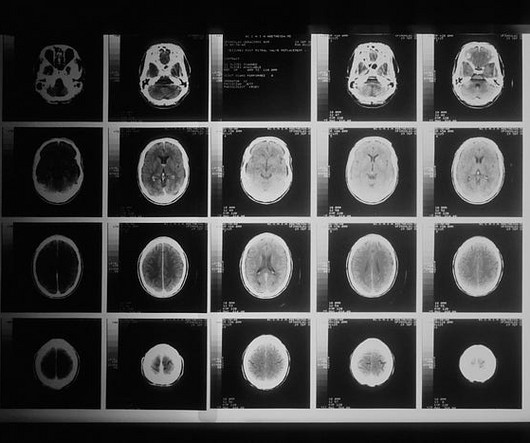
Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information. Working with vector data is tough because regular databases, which usually handle one piece of information at a time, can’t handle the complexity and large amount of this type of data.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
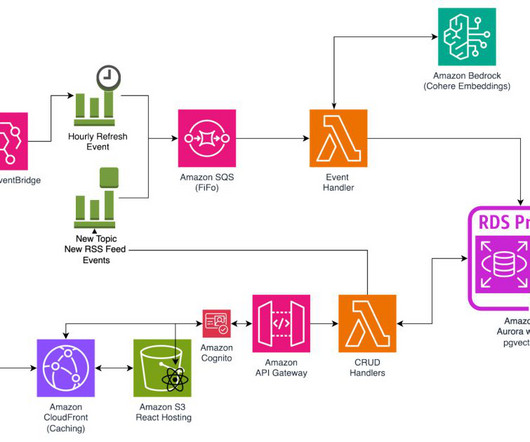
Using Amazon Bedrock Knowledge Bases, FMs and agents can retrieve contextual information from your company’s private data sources for RAG. It supports exact and approximate nearest-neighboralgorithms and multiple storage and matching engines. For information on creating service roles, refer to Service roles.
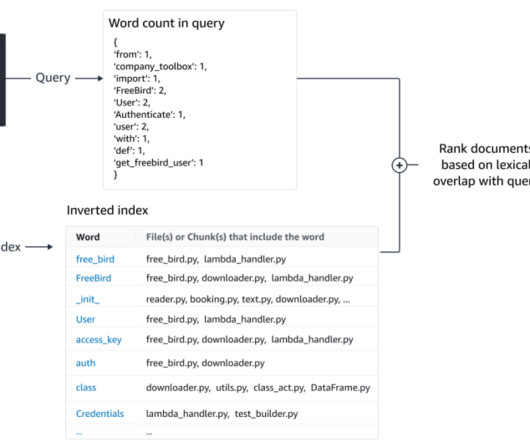
The ability to quickly access relevant information is a key differentiator in todays competitive landscape. improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. This post is co-written with Elliott Choi from Cohere. Overview of Cohere Rerank 3.5
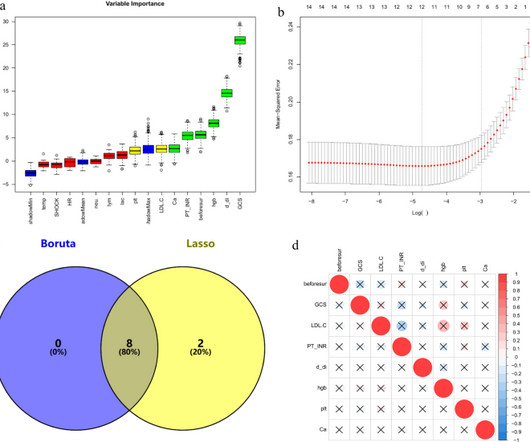
Feature selection via the Boruta and LASSO algorithms preceded the construction of predictive models using Random Forest, Decision Tree, K-NearestNeighbors, Support Vector Machine, LightGBM, and XGBoost. Demographic data, physiological status, and non-invasive test indicators were collected.
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights.
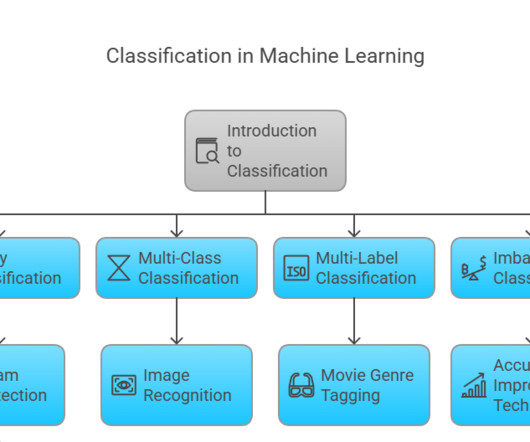
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
There are various techniques used to obtain information about tumors. Ensemble models can be generated using a single algorithm with numerous variations, known as a homogeneous ensemble, or by using different techniques, known as a heterogeneous ensemble [3]. For the meta-model, k-nearestneighbors were used again.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code.
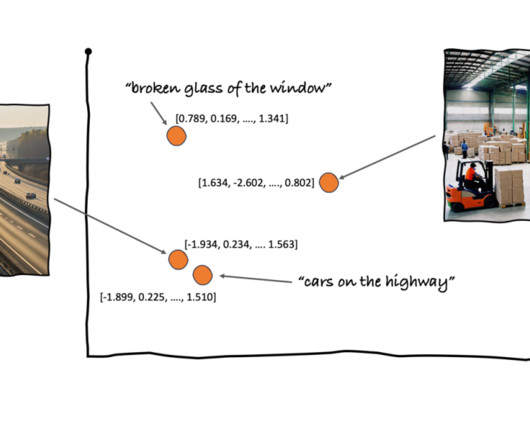
However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions. This is the k-nearestneighbor (k-NN) algorithm.
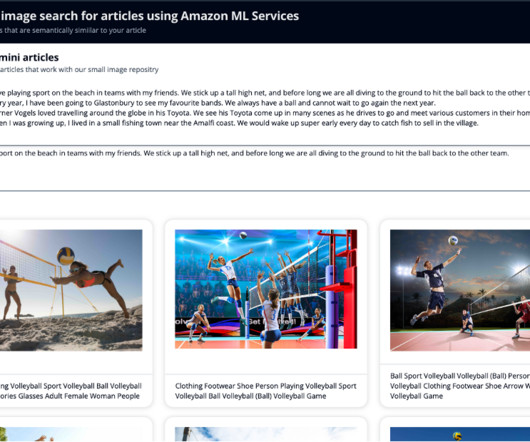
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. For more information on managing credentials securely, see the AWS Boto3 documentation. The closer vectors are to one another in this space, the more similar the information they represent is.
It bridges the gap between mere correlation and genuine insight, enabling organizations to make informed decisions based on the root causes of events. Step-by-step process Collect observational data: Gather extensive datasets that track various events over time to inform causal relationships.
Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme. Shall we unravel the true meaning of machine learning algorithms and their practicability?
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? For example, it takes millions of images and runs them through a training algorithm.
The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer. For more information, contact us at info@flotorch.ai. FloTorch used HSNW indexing in OpenSearch Service.
What Is the KNN Classification Algorithm? The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel. It is useful for recognizing patterns […].
In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations. However, typical algorithms do not produce a binary result but instead, provide a relevancy score for which labels are the most appropriate. Thus tail labels have an inflated score in the metric.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. The aim is to understand which approach is most suitable for addressing the presented challenge.
For this post, you use the following: Name, Id, and Urls – The celebrity name, a unique Amazon Rekognition ID, and list of URLs such as the celebrity’s IMDb or Wikipedia link for further information. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results.
Examples of Eager Learning Algorithms: Logistic Regression : A classic Eager Learning algorithm used for binary classification tasks. Support Vector Machines (SVM) : SVM is a powerful Eager Learning algorithm used for both classification and regression tasks. Eager Learning Algorithms: How does it work?
Random Projection The first step in the algorithm is to sample random vectors in the same -dimensional space as input vector. These word vectors are trained from Twitter data making them semantically rich in information. Each word is mapped to its corresponding vector representation.
Common machine learning algorithms for supervised learning include: K-nearestneighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. Isolation forest: This type of anomaly detection algorithm uses unsupervised data.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. The information from previous decisions is analyzed via the decision tree. This technique is based on the concept that related information tends to cluster together.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. The information from previous decisions is analyzed via the decision tree. This technique is based on the concept that related information tends to cluster together.
The Multi-Armed Bandit (MAB) algorithm is a type of reinforcement learning algorithm that addresses the trade-off between exploration and exploitation in decision-making. In the context of the MAB algorithm, each arm represents a decision that can be taken, and the reward corresponds to some measure of performance or utility.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. What is Unsupervised Machine Learning?
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. By analyzing how users have interacted with items in the past, we can use algorithms to approximate the utility function and make personalized recommendations that users will love.
ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning. Strictly, everything that I said earlier is based on Machine learning algorithms and, of course, strong math and theory of algorithms behind them. Great example of this tecnique is K-means clustering algorithm.
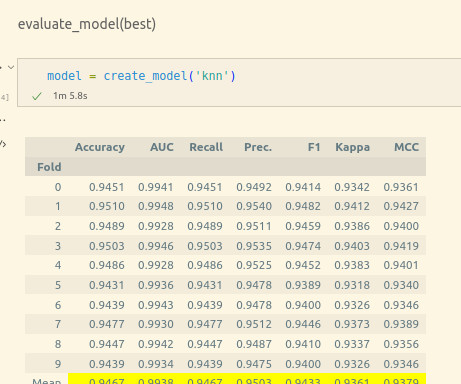
Solution overview The solution provides an implementation for answering questions using information contained in text and visual elements of a slide deck. We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. I need numbers. Up to 4x higher throughput.
In the era of data-driven decision making, social media platforms like Twitter have become more than just channels for communication, but also a trove of information offering profound insights into human behaviors and societal trends. This initial data collection lays the foundation for our subsequent analysis and modeling.
This benefits enterprise software development and helps overcome the following challenges: Sparse documentation or information for internal libraries and APIs that forces developers to spend time examining previously written code to replicate usage. This retrieval can happen using different algorithms.
We developed the STUDY algorithm in partnership with Learning Ally , an educational nonprofit, aimed at promoting reading in dyslexic students, that provides audiobooks to students through a school-wide subscription program. However, this data representation requires careful diligence if it is to be modeled by transformers.
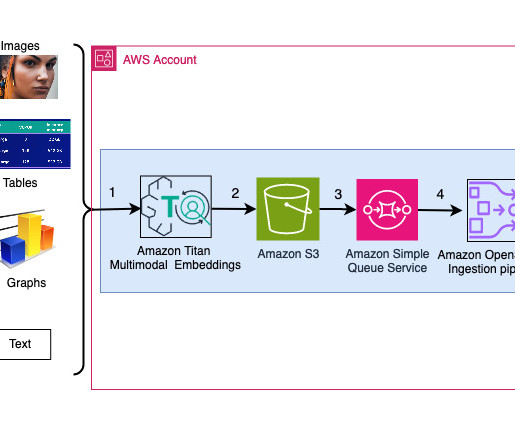
It processes and generates information from distinct data types like text and images. For more information, refer to Amazon Titan Multimodal Embeddings G1 model. Determining the optimal value of K in the k-NN algorithm for vector similarity search is significant for balancing accuracy, performance, and cost.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content