This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DecisionTree 3. CART Algorithm 5. Calculating Information Gain 6. Conclusion Introduction This article is on the DecisionTreealgorithm in Machine Learning. The post DecisionTree Machine Learning Algorithm appeared first on Analytics Vidhya. Table of Contents 1.
ArticleVideo Book Introduction In the previous article, we saw the Chi-Square algorithm- How to select Best Split in DecisionTrees using Chi-Square. The post How to select Best Split in DecisionTrees using Information Gain appeared first on Analytics Vidhya.
Overview How do you split a decisiontree? What are the different splitting criteria when working with decisiontrees? Learn all about decisiontree. The post 4 Simple Ways to Split a DecisionTree in Machine Learning appeared first on Analytics Vidhya.
The post All About DecisionTree from Scratch with Python Implementation appeared first on Analytics Vidhya. Introduction Photo by Tim Foster on Unsplash If you see, you will find out that today, ensemble learnings are more popular and used by.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! It’s like having a super-powered tool to sort through information and make better sense of the world. Learn in detail about machine learning algorithms 2.
This paper introduces the Trinary decisiontree, an algorithm designed to improve the handling of missing data in decisiontree regressors and classifiers. Unlike other approaches, the Trinary decisiontree does not assume that missing values contain any information about the response.
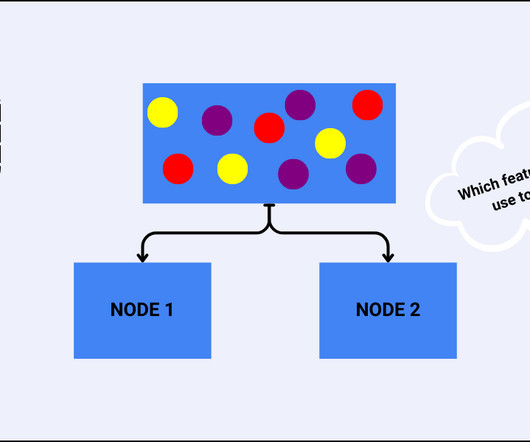
In data science and machine learning, decisiontrees are powerful models for both classification and regression tasks. It is a measure of impurity (non-homogeneity) widely used in decisiontrees. The feature with the highest information gain is chosen for the node. What is the Gini Index? What is Entropy?
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. These intelligent predictions are powered by various Machine Learning algorithms.
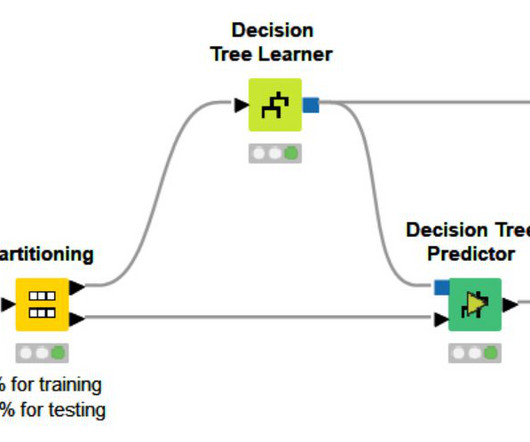
In this post, I will show how to develop, deploy, and use a decisiontree model in a Db2 database. For each flight, the dataset has information such as the flight’s origin airport, departure time, flying time, and arrival time. Also, a column in the dataset indicates if each flight had arrived on time or late.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. CatBoost is part of the gradient boosting family, alongside well-known algorithms like XGBoost and LightGBM.
By creating artificial datasets that mimic real-world statistics without compromising personal information, organizations can harness the power of data while adhering to stringent privacy regulations. Synthetic data is revolutionizing the way we approach data privacy and analysis across various industries. What is synthetic data?
In essence, data scientists use their skills to turn raw data into valuable information that can be used to improve products, services, and business strategies. Missing Data: Filling in missing pieces of information. Data-Driven Decisions: Based on these insights, data scientists can make informeddecisions that drive business growth.
One of the most popular algorithms in Machine Learning are the DecisionTrees that are useful in regression and classification tasks. Decisiontrees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning. How DecisionTreeAlgorithm works?
Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts. Unsupervised models Unsupervised models typically use traditional statistical methods such as logistic regression, time series analysis, and decisiontrees.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights.
Business Benefits: Organizations are recognizing the value of AI and data science in improving decision-making, enhancing customer experiences, and gaining a competitive edge An AI research scientist acts as a visionary, bridging the gap between human intelligence and machine capabilities. Privacy: Protecting user privacy and data security.
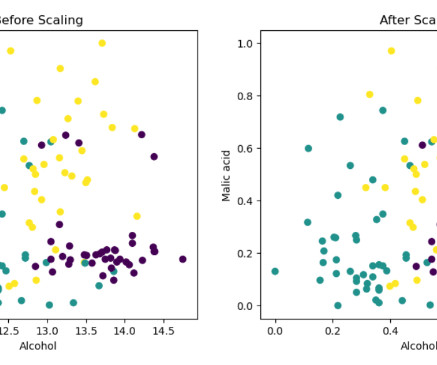
Knowing how to work with categorical variables can enhance the performance of machine learning models by ensuring that all available information is utilized effectively. They influence the choice of algorithms and the structure of models. Understanding specific needs and capabilities can help in effectively applying these algorithms.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
But in its raw form, this data is just noise until it is analyzed and transformed into meaningful information. As an interdisciplinary field, data science leverages scientific methods, algorithms, and systems to extract insights from structured and unstructured data. This is where data science steps in.
In the world of Machine Learning and Data Analysis , decisiontrees have emerged as powerful tools for making complex decisions and predictions. These tree-like structures break down a problem into smaller, manageable parts, enabling us to make informed choices based on data. What is a DecisionTree?
These features can be used to improve the performance of Machine Learning Algorithms. By manipulating the input features of a dataset, we can enhance their quality, extract meaningful information, and improve the performance of predictive models. This dataset includes four input features: User ID, Gender, Age, and Salary.
Extrapolation and interpolation are powerful tools in data analysis, enabling professionals to make informed predictions and fill in gaps in datasets. Extrapolation and interpolation serve as methods for estimating unknown data points based on existing information. What are extrapolation and interpolation?
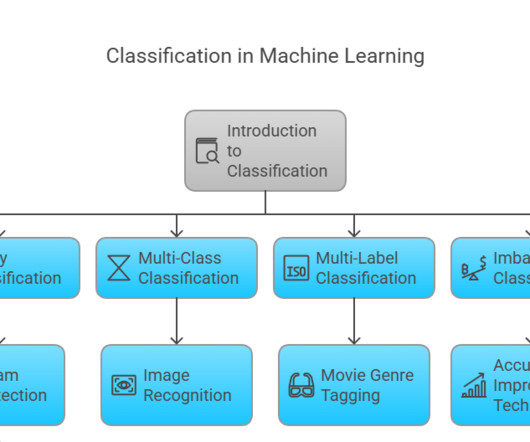
Overview of classification in machine learning Classification serves as a foundational method in machine learning, where algorithms are trained on labeled datasets to make predictions. Classification methods are vital for organizing information and making data-driven decisions.
In essence, data scientists use their skills to turn raw data into valuable information that can be used to improve products, services, and business strategies. Meaningful Insights: Statistics helps to extract valuable information from the data, turning raw numbers into actionable insights. It’s like deciphering a secret code.
Throughout the course of history, the significance of creating and disseminating information has been immensely crucial. Moreover, statistical inference empowers them to make informeddecisions and draw meaningful conclusions based on sample data. It provides a wide range of mathematical functions and algorithms.
Categorical data is one such form of information that is handled by ML models using different methods. Model Compatibility Most machine learning algorithms work with numerical data, making it essential to transform categorical variables into numerical values. Learn about 101 ML algorithms for data science with cheat sheets 5.
Support Vector Machines (SVM) are a type of supervised learning algorithm designed for classification and regression tasks. This decision boundary is crucial for achieving accurate predictions and effectively dividing data points into categories. What are Support Vector Machines (SVM)?
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the DecisionTree. This often occurs in Cluster Analysis, where we identify clusters without prior information. Before we start, please consider following me on Medium or LinkedIn.
The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Below, we highlight a panoply of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
We shall look at various machine learning algorithms such as decisiontrees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code.
This discipline takes raw data, deciphers it, and turns it into a digestible format using various tools and algorithms. Understanding algorithms is like mastering maps, with each algorithm offering different paths to solutions. Tools such as Python, R, and SQL help to manipulate and analyze data. The learning curve also varies.
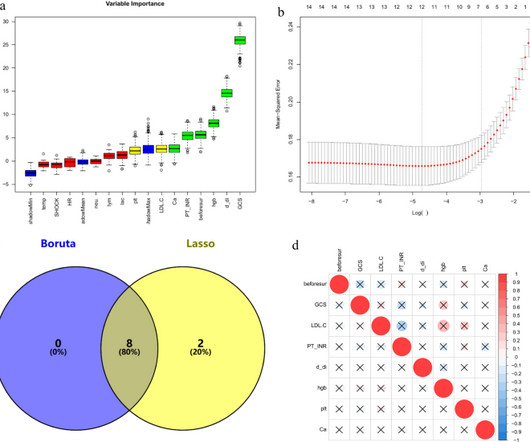
Feature selection via the Boruta and LASSO algorithms preceded the construction of predictive models using Random Forest, DecisionTree, K-Nearest Neighbors, Support Vector Machine, LightGBM, and XGBoost. Demographic data, physiological status, and non-invasive test indicators were collected.
Data mining can help governments identify areas of concern, allocate resources, and make informed policy decisions. Selecting the right algorithm There are several data mining algorithms available, each with its strengths and weaknesses. Choose the appropriate technique based on your dataset and analysis needs.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Each algorithm is explained with its applications, strengths, and weaknesses, providing valuable insights for practitioners and enthusiasts in the field.
Setting Up Our Project Comparing XGboost and Gradient Boost Results Summary Citation Information Scaling Kaggle Competitions Using XGBoost: Part 3 We continue our journey into understanding XGBoost, but there is one penultimate stop we need to make before deep diving into the nitty gritty of Extreme Gradient Boosting.
This article was published as a part of the Data Science Blogathon. Introduction Entropy is one of the key aspects of Machine Learning. The post Entropy – A Key Concept for All Data Science Beginners appeared first on Analytics Vidhya.
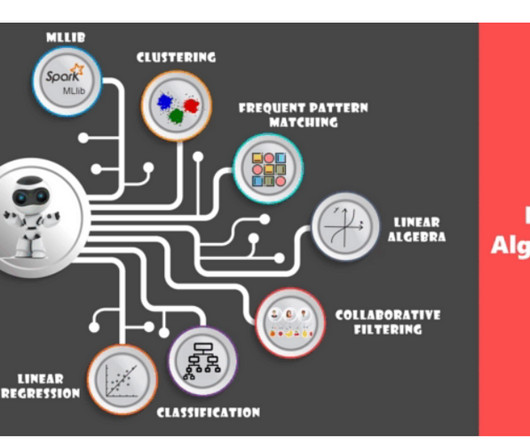
Later on, we will train a classifier for Car Evaluation data, by Encoding the data, Feature extraction and Developing classifier model using various algorithms and evaluate the results. Pyspark MLlib is a wrapper over PySpark Core to do data analysis using machine-learning algorithms. It works on distributed systems and is scalable.
Predictive AI blends statistical analysis with machine learning algorithms to find data patterns and forecast future outcomes. In short, predictive AI helps enterprises make informeddecisions regarding the next step to take for their business. What is predictive AI? Regression models determine correlations between variables.
By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informeddecisions and take autonomous actions. This enables them to extract valuable insights, identify patterns, and make informeddecisions in real-time.
Are you ready to take your machine learning algorithms to the next level? Say hello to Gradient Boosting Algorithm! Gradient boosting is not just your regular algorithm; it’s a functional gradient algorithm that works wonders in the world of machine learning. What is Gradient Boosting?
Making the right decisions in an aggressive market is crucial for your business growth and that’s where decision intelligence (DI) comes to play. In this era of information overload, utilizing the power of data and technology has become paramount to drive effective decision-making. What is decision intelligence?
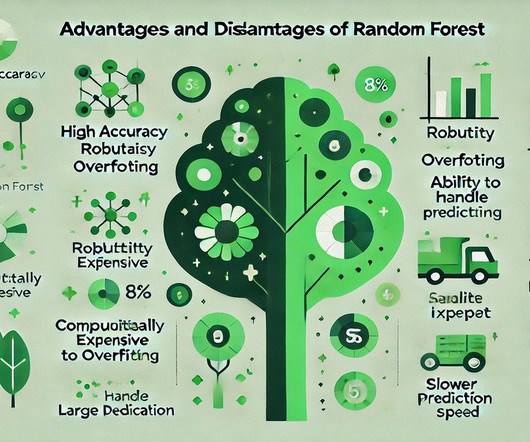
Summary: Random Forest is an effective Machine Learning algorithm known for its high accuracy and robustness. Introduction Random Forest is a powerful ensemble learning algorithm widely used in Machine Learning for classification and regression tasks. A single decisiontree can be prone to errors and overfitting.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content