This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the realm of artificial intelligence, the emergence of vector databases is changing how we manage and retrieve unstructured data. By allowing for semantic similarity searches, vector databases are enhancing applications across various domains, from personalized content recommendations to advanced natural language processing.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications.
Data from external sources: Web scraping, Google Sheets, Excel, and SQLite databases. Algorithms and logic building: Apply algorithmic thinking with the Luhn algorithm , bisection method , shortest path , recursion ( Tower of Hanoi ), and tree traversal.
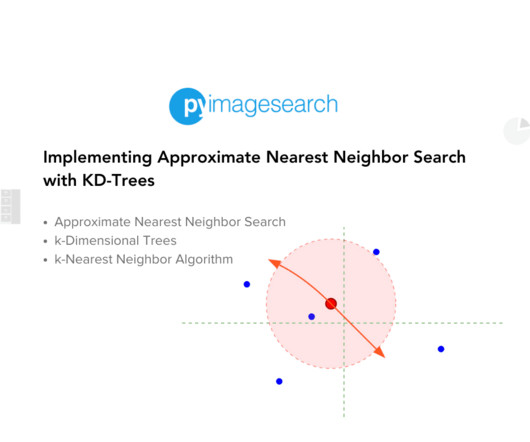
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play.
Most generative AI work happens at the application layer, using APIs and frameworks rather than implementing algorithms from scratch. Vector Databases and Embedding Strategies : RAG systems rely on semantic search to find relevant information, requiring documents converted into vector embeddings that capture meaning rather than keywords.
torchft implements a few different algorithms for fault tolerance. These algorithms minimize communication overhead by synchronizing at specified intervals instead of every step like HSDP. We’re always keeping an eye out for new algorithms, such as our upcoming support for streaming DiLoCo.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
Data structures play a critical role in organizing and manipulating data efficiently, serving as the foundation for algorithms and high-performing applications. Importance of data structures Data structures significantly impact algorithm efficiency and application performance.
By Jayita Gulati on July 16, 2025 in Machine Learning Image by Editor In data science and machine learning, raw data is rarely suitable for direct consumption by algorithms. Feature engineering can impact model performance, sometimes even more than the choice of algorithm itself.
cuML brings GPU-acceleration to UMAP and HDBSCAN , in addition to scikit-learn algorithms. It dramatically improves algorithm performance for data-intensive tasks involving tens to hundreds of millions of records. It dramatically improves algorithm performance for data-intensive tasks involving tens to hundreds of millions of records.
The in-memory algorithms for approximate nearest neighbor search (ANNS) have achieved great success for fast high-recall search, but are extremely expensive when handling very large scale database. Thus, there is an increasing request for the hybrid ANNS solutions with small memory and inexpensive solid-state drive (SSD).
Vectorization: The Backbone of RAG Vectorization is the process of converting various forms of datasuch as text, images, or audiointo numerical vectors that can be processed by Machine Learning algorithms. Creating a Vector Database Once the data is vectorized, the next step is to store these vectors in a vector database.
It covers a range of topics including generative AI, LLM basics, natural language processing, vector databases, prompt engineering, and much more. You get a chance to work on various projects that involve practical exercises with vector databases, embeddings, and deployment frameworks.
This type of data maintains a clear structure, usually in rows and columns, which makes it easy to store and retrieve using database systems. Definition and characteristics of structured data Structured data is typically characterized by its organization within fixed fields in databases.
Tree structures in databases serve as a powerful means to organize and manage data, allowing for efficient retrieval and manipulation. By utilizing a hierarchical layout that resembles a tree, databases can effectively minimize search times and optimize data arrangements. What is tree structure in databases?
Disk mode uses the HNSW algorithm to build indexes, so m is one of the algorithm parameters, and it defaults to 16. He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearchs vector database capabilities. Dylan holds a BSc and MEng degree in Computer Science from Cornell University.
His professional interests include natural language processing, language models, machine learning algorithms, and exploring emerging AI. As managing editor of KDnuggets & Statology , and contributing editor at Machine Learning Mastery , Matthew aims to make complex data science concepts accessible.
Furthermore, NoSQL databases serve as effective platforms for implementing data lakes, allowing for rapid ingestion and retrieval of diverse data types. These enhancements allow for faster querying and analysis, often utilizing machine learning (ML) algorithms and visualization tools.
Second, based on this natural language guidance, our algorithms intelligently translate the guidance into technical optimizations – refining the retrieval algorithm, enhancing prompts, filtering the vector database, or even modifying the agentic pattern. ignore all data before May 1990).
Here’s a guide to choosing the right vector embedding model Importance of Vector Databases in Vector Search Vector databases are the backbone of efficient and scalable vector search. They use specialized indexing techniques, like Approximate Nearest Neighbor (ANN) algorithms, to speed up searches without compromising accuracy.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
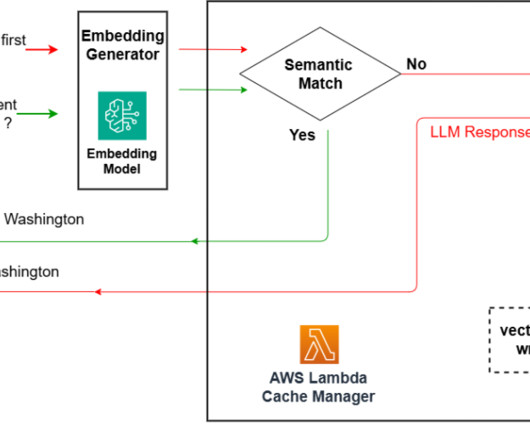
A semantic cache system operates at its core as a database storing numerical vector embeddings of text queries. With OpenSearch Serverless, you can establish a vector database suitable for setting up a robust cache system. The new generation is then sent to the client and used to update the vector database.
Advanced algorithms like multimodal anomaly detection can be applied to the converged time-series signal and real-time weather conditions, improving the operational picture for operations personnel. The dashboard above, built on Databricks AI/BI, visualizes time-series data streaming in from sensors located on a collection of compressors.
A users question is used as the query to retrieve relevant documents from a database. LangChain offers a collection of open-source building blocks, including memory management , data loaders for various sources, and integrations with vector databases all the essential components of a RAG system. Overview of a baseline RAG system.
This technique addresses the following aspects: Schema integration: Matching entities from different databases can be challenging, as attribute correspondence must be identified (e.g., Data cleansing algorithms: These algorithms are essential for reducing the impact of “dirty” data on mining outcomes.
Efficient data retrieval: Utilizing hash tables speeds up searches within databases, making it ideal for managing large datasets. Algorithms like MD5 and SHA-256 are commonly utilized to hash information, rendering it unreadable without decryption keys. Hashing vs. encryption Hashing and encryption serve different purposes.
OpenSearch uses algorithms from the NMSLIB , Faiss , and Lucene libraries to power approximate k-NN search. Within the Faiss engine, OpenSearch supports both Hierarchical Navigable Small World (HNSW) and Inverted File System (IVF) algorithms. To learn more about the differences between these engine algorithms, see Vector search.
Data compression employs various algorithms that analyze and reduce file sizes by removing redundant or unnecessary information. By understanding these algorithms, one can appreciate their importance in managing vast amounts of data. Compression algorithmsAlgorithms identify patterns and redundancies within data.
Dataiku automatically suggests algorithms, and users can compare a variety of models—such as random forests, XGBoost, or logistic regression—via a straightforward, visual comparison interface. Through its intuitive visual ML interface, Dataiku empowers users to build and compare machine learning models with ease.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Data Sources and Collection Everything in data science begins with data.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. in a 2D space based on the machine learning algorithm used. Are you interested in exploring Snowflake as a vector database?
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. First, it enables you to include both image and text features in a single database and therefore reduces complexity.
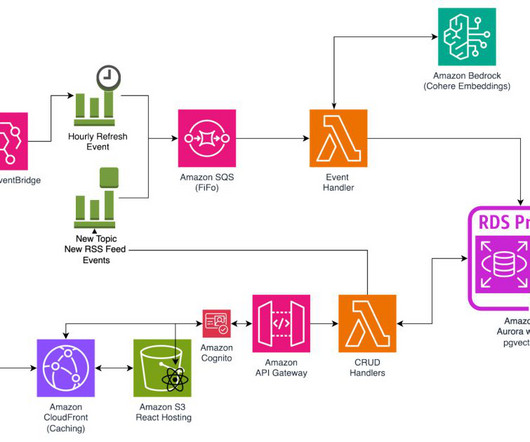
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector. Its hosted on AWS Lambda.
SQL remains crucial for database querying, especially given India’s large IT services ecosystem. Machine Learning & AI: Hands-on experience with supervised and unsupervised algorithms, deep learning frameworks (TensorFlow, PyTorch), and natural language processing (NLP) is highly valued. Databases: MySQL, PostgreSQL, MongoDB.
Unlike traditional software agents, which typically require human input or have limited functionalities, autonomous AI agents leverage advanced algorithms to improve their performance over time. Steps in operations Key operational steps include: Data collection: Collects data from diverse sources, including databases and user interactions.
Store these chunks in a vector database, indexed by their embedding vectors. The various flavors of RAG borrow from recommender systems practices, such as the use of vector databases and embeddings. Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks.
Database name : Enter dev. Database user : Enter awsuser. SageMaker Canvas integration with Amazon Redshift provides a unified environment for building and deploying machine learning models, allowing you to focus on creating value with your data rather than focusing on the technical details of building data pipelines or ML algorithms.
Zilliz, the company behind the open-source vector database Milvus, is closely following this evolution as it intersects with cutting-edge AI infrastructure. In a recent session, Stefan Webb, Developer Advocate at Zilliz, spotlighted the growing potential of foundation models for time series forecasting.
Scanning the energy label links directly to the EPREL database, revealing granular specs, spare-part availability windows, and software-update commitments. OpenAI lays out its grand AI blueprint for Europe The spare-part SLA forces regional warehousing and tighter demand-planning algorithms, yet it also unlocks new paid-service streams.
Recent studies show that approximately 80% of organisations affected by ransomware attacks on their databases last year were compelled to pay a ransom. Administrators can configure these AI algorithms to scan backups and databases every 30 daysor any other interval that suits their needsto provide ongoing health and security.
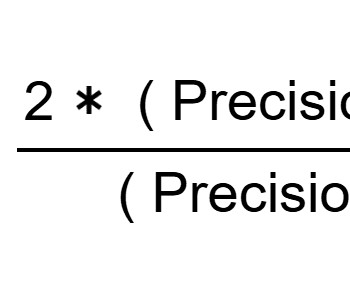
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. The aim is to understand which approach is most suitable for addressing the presented challenge.
However, this approach comes with several problems: While LRU and LFU exhibit non-optimal hit rates, implementing advanced eviction algorithms can yield substantial hit rate improvements. While TinyLFU performs well on frequency-skewed workloads (search, database page caches, and analytics), it may underperform in other scenarios.
Defining Cloud Computing in Data Science Cloud computing provides on-demand access to computing resources such as servers, storage, databases, and software over the Internet. The cloud also offers distributed computing capabilities, enabling faster processing of complex algorithms across multiple nodes. billion in 2023 to USD 1,266.4
The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content