This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Secure Sockets Layer (SSL) or Transport Layer Security (TLS) protocols encrypt data during system communication. Any interceptors attempting to eavesdrop on the communication will only encounter scrambled data. Data ownership extends beyond mere possession—it involves accountability for dataquality, accuracy, and appropriate use.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. You can review the recommendations and augment rules from over 25 included dataquality rules.
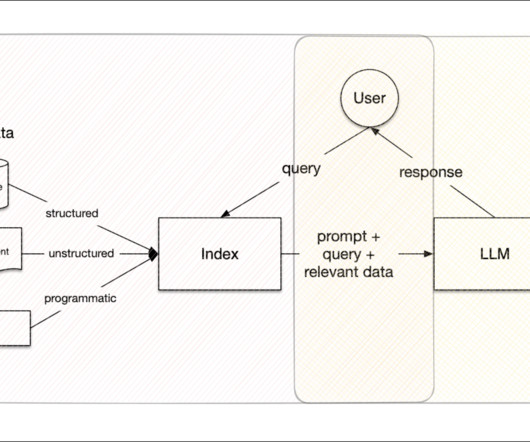
It possesses a suite of features that streamline data tasks and amplify the performance of LLMs for a variety of applications, including: Data Connectors: Data connectors simplify the integration of data from various sources to the data repository, bypassing manual and error-prone extraction, transformation, and loading (ETL) processes.
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. Machine learning and AI analytics: Machine learning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. What is Data Profiling in ETL?
The batch views within the Lambda architecture allow for the application of more complex or resource-intensive rules, resulting in superior dataquality and reduced bias over time. On the other hand, the real-time views provide immediate access to the most current data.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. Why Are Data Transformation Tools Important?
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. As part of the initial ETL, this raw data can be loaded onto tables using AWS Glue.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation. Step 3: Data Transformation Data transformation focuses on converting cleaned data into a format suitable for analysis and storage.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. If you aren’t aware already, let’s introduce the concept of ETL.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
Data Integration Once data is collected from various sources, it needs to be integrated into a cohesive format. DataQuality Management : Ensures that the integrated data is accurate, consistent, and reliable for analysis. These tools work together to facilitate efficient data management and analysis processes.
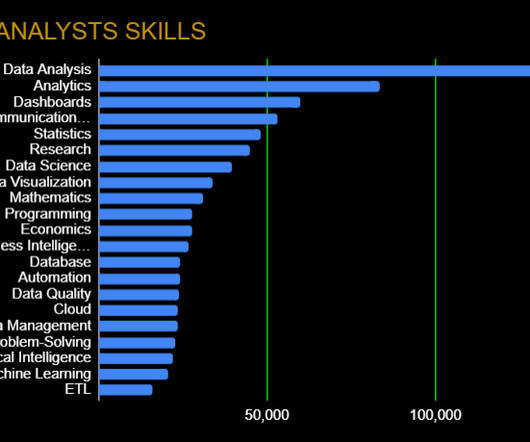
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis. Understanding ETL (Extract, Transform, Load) processes is vital for students. Students should learn about data wrangling and the importance of dataquality.
In general, this data has no clear structure because it may manifest real-world complexity, such as the subtlety of language or the details in a picture. Advanced methods are needed to process unstructured data, but its unstructured nature comes from how easily it is made and shared in today's digital world.
The sudden popularity of cloud data platforms like Databricks , Snowflake , Amazon Redshift, Amazon RDS, Confluent Cloud , and Azure Synapse has accelerated the need for powerful data integration tools that can deliver large volumes of information from transactional applications to the cloud reliably, at scale, and in real time.
I would start by collecting historical sales data and other relevant variables such as promotional activities, seasonality, and economic factors. Then, I would explore forecasting models such as ARIMA, exponential smoothing, or machine learning algorithms like random forests or gradient boosting to predict future sales.
ThoughSpot can easily connect to top cloud data platforms such as Snowflake AI Data Cloud , Oracle, SAP HANA, and Google BigQuery. In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack.
The sudden popularity of cloud data platforms like Databricks , Snowflake , Amazon Redshift, Amazon RDS, Confluent Cloud , and Azure Synapse has accelerated the need for powerful data integration tools that can deliver large volumes of information from transactional applications to the cloud reliably, at scale, and in real time.
Example of Information Kept for a Simple Data Catalog Implications of Choosing the Wrong Methodology Choosing the wrong data lake methodology can have profound and lasting consequences for an organization. Inaccurate or inconsistent data can undermine decision-making and erode trust in analytics.
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
Modern AI, on the other hand, is built on machine learning and artificial neural networks – algorithms that can learn their behavior from examples in data. As computational power increased and data became more abundant, AI evolved to encompass machine learning and data analytics.
is similar to the traditional Extract, Transform, Load (ETL) process. It operates in three stages: Extract unstructured data from a source. Transform the unstructured data into a more structured format. Ingest the transformed data into a designated destination. Unstructured.io
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. One of the features that Hamilton has is that it has a really lightweight dataquality runtime check.
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content