This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Text mining is an ever-evolving field that offers businesses a powerful means to analyze vast amounts of unstructured text data. It’s fascinating how organizations harness advanced algorithms to transform raw text into actionable insights, helping them understand customer sentiments and market trends.
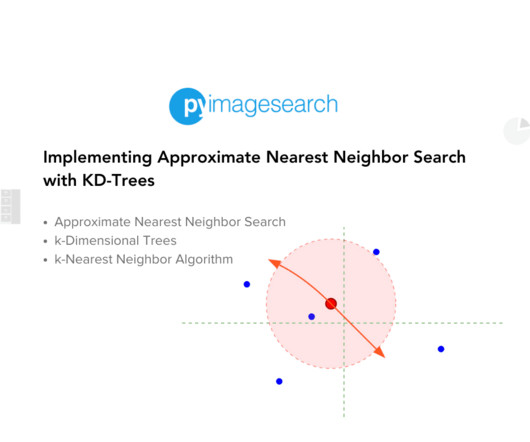
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
By Jayita Gulati on July 16, 2025 in Machine Learning Image by Editor In data science and machine learning, raw data is rarely suitable for direct consumption by algorithms. Feature engineering can impact model performance, sometimes even more than the choice of algorithm itself.
With data software pushing the boundaries of what’s possible in order to answer business questions and alleviate operational bottlenecks, data-driven companies are curious how they can go “beyond the dashboard” to find the answers they are looking for. One of the standout features of Dataiku is its focus on collaboration.
Augmented analytics is the integration of ML and NLP technologies aimed at automating several aspects of datapreparation and analysis. It enhances traditional data analytics by allowing users to derive actionable insights quickly and efficiently.
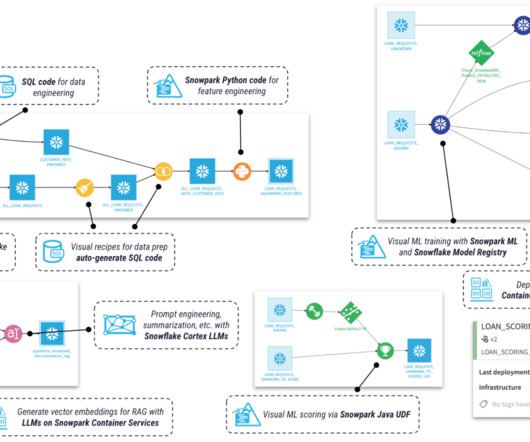
Vectorization: The Backbone of RAG Vectorization is the process of converting various forms of datasuch as text, images, or audiointo numerical vectors that can be processed by Machine Learning algorithms. Each vector represents specific features or characteristics of the data, allowing for efficient storage and retrieval.
The Rise of Augmented Analytics Augmented analytics is revolutionizing how data insights are generated by integrating artificial intelligence (AI) and machine learning (ML) into analytics workflows. Explosion of Internet of Things (IoT) Data The proliferation of IoT devices is generating unprecedented volumes of real-time data.
With the most recent developments in machine learning , this process has become more accurate, flexible, and fast: algorithms analyze vast amounts of data, glean insights from the data, and find optimal solutions. Given the enormous volume of information which can reach petabytes efficient data handling is crucial.
AWS SageMaker is transforming the way organizations approach machine learning by providing a comprehensive, cloud-based platform that standardizes the entire workflow, from datapreparation to model deployment. Datapreparation This involves annotating datasets of images and videos for machine learning tasks.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
Financial services In the financial sector, synthetic credit card transaction data is utilized for fraud detection. This approach enables companies to develop algorithms that identify suspicious patterns without exposing sensitive data during the training phase.
Classification algorithms are some of the most useful machine learning models in use today. A confusion matrix is a chart that compares the predicted labels of a classification algorithm to their actual value. Confusion matrices do just that for classification algorithms. Many classification tasks naturally involve imbalance.
Datapreparation For this example, you will use the South German Credit dataset open source dataset. After you have completed the datapreparation step, it’s time to train the classification model. An experiment collects multiple runs with the same objective.
By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics. Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. The platform’s strength lies in its ability to abstract away the complexities of infrastructure management, allowing you to focus on innovation rather than operational overhead.
Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for datapreparation before analysis. Data Analysis and Modeling This stage is focused on discovering patterns, trends, and insights through statistical methods, machine-learning models, and algorithms.
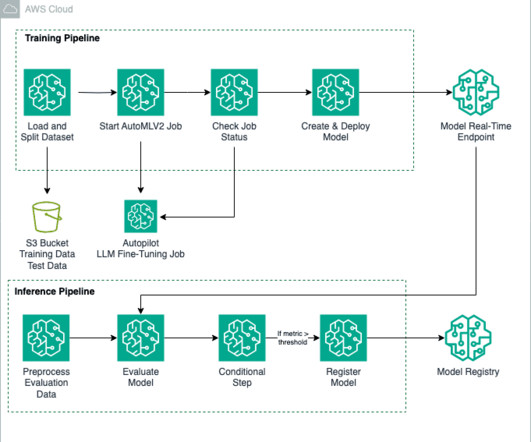
We use Amazon SageMaker Pipelines , which helps automate the different steps, including datapreparation, fine-tuning, and creating the model. This configuration acts as a guide, helping SageMaker Autopilot understand the nature of your problem and select the most appropriate algorithm or approach.
This rapid growth underscores the importance of understanding how GenAI can be leveraged in Data Analytics to address current challenges and unlock new opportunities. Key Takeaways GenAI automates datapreparation and analysis, saving time for analysts.
It’s an integral part of data analytics and plays a crucial role in data science. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
After taking some free online courses in Python and machine learning, he quickly became immersed in a fascinating new world of data and algorithms. Machine learning algorithms were “almost like magic” to Orman. “I One day, he hopes to marry his two major passions by working on recommendation algorithms for music.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms.
Data ingestion: Tools gather data from various sources, providing a holistic view of organizational data. Datapreparation: Processes ensure that the data is clean, accurate, and formatted correctly for analysis.
It uses unlabeled data where only inputs are given without any predefined outputs. The ML algorithm tries to find hidden patterns and structures in this data. It groups similar data points or identifies outliers without prior guidance. Unsupervised learning deals with data that has not been labeled.
This capability relies on sophisticated algorithms and vast training datasets to build a comprehensive linguistic foundation. Datapreparation for fine-tuning: Curating task-specific datasets ensures the model receives relevant examples for effective learning.
Optimization strategies: This involves refining algorithms to enhance performance and minimize computational resources. Scalability of ML algorithms The scalability of machine learning algorithms is influenced by several key factors.
Factors to consider during this selection include: Algorithm suitability: Ensuring the chosen model fits the problem type. Data characteristics: Analyzing the quality and quantity of data available for training. Reduced pre-processing needs: Streamlining workflows by minimizing the need for extensive datapreparation.
Major areas of data science Data science incorporates several critical components: Datapreparation: Ensuring data is cleansed and organized before analysis. Data analytics: Identifying trends and patterns to improve business performance. Machine learning: Developing models that learn and adapt from data.
Overview of core disciplines Data science encompasses several key disciplines including data engineering, datapreparation, and predictive analytics. Data engineering lays the groundwork by managing data infrastructure, while datapreparation focuses on cleaning and processing data for analysis.
ML orchestration refers to the coordinated management of tasks within the machine learning lifecycle, encompassing processes such as datapreparation, model training, validation, and deployment. This article delves into the intricacies of ML orchestration, exploring its significance and key features. What is ML orchestration?
This structured framework ensures that all necessary stepsfrom datapreparation to model monitoringare executed systematically, enhancing efficiency and effectiveness in both business and technology applications. The main components typically include datapreparation, model training, deployment, and ongoing monitoring.
Sinan Ozdemir, AI & LLM Expert | Author | Founder + CTO of LoopGenius A former Director of Data Science at Directly and AI advisor to Tola Capital, he brings deep expertise in LLMs, machine learning, and algorithm development.
This entails breaking down the large raw satellite imagery into equally-sized 256256 pixel chips (the size that the mode expects) and normalizing pixel values, among other datapreparation steps required by the GeoFM that you choose. A common high-performance search algorithm for this is approximate nearest neighbor (ANN).
Machine learning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. What are machine learning algorithms? Regression: Focuses on predicting continuous values, such as forecasting sales or estimating property prices.
If you want to work on operating production critical databases in the cloud on k8s + write data-driven algorithms for autoscaling, consider applying! Fun engineering challenges: These include complex distributed systems, low-latency algorithms & infrastructure, and modeling sales calls with large language models.
14 Essential Git Commands for Data Scientists • Statistics and Probability for Data Science • 20 Basic Linux Commands for Data Science Beginners • 3 Ways Understanding Bayes Theorem Will Improve Your Data Science • Learn MLOps with This Free Course • Primary Supervised Learning Algorithms Used in Machine Learning • DataPreparation with SQL Cheatsheet. (..)
Introduction on AutoKeras Automated Machine Learning (AutoML) is a computerised way of determining the best combination of datapreparation, model, and hyperparameters for a predictive modelling task. The AutoML model aims to automate all actions which require more time, such as algorithm selection, […].
Typically, dense vector embeddings and similarity search algorithms (e.g., Instead of relying on static datasets, it uses GPT-4 to generate instruction-following data across diverse scenarios. It searches a structured or unstructured knowledge base to find the most relevant pieces of information related to a user query.
Overview Introduction to Natural Language Generation (NLG) and related things- DataPreparation Training Neural Language Models Build a Natural Language Generation System using PyTorch. The post Build a Natural Language Generation (NLG) System using PyTorch appeared first on Analytics Vidhya.
In this article, I describe 3 alternative algorithms to select predictive features based on a feature importance score. Feature selection methodologies go beyond filter, wrapper and embedded methods.
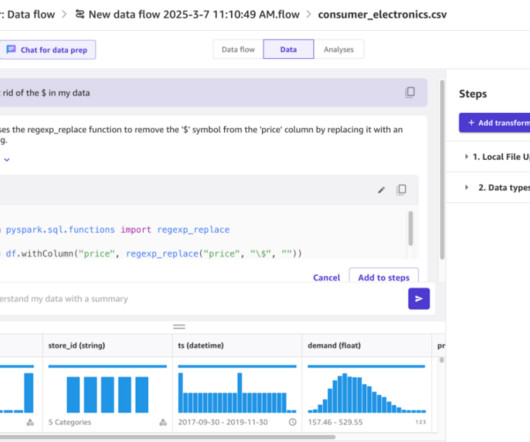
In this post, we explore how SageMaker Canvas and SageMaker Data Wrangler provide no-code datapreparation techniques that empower users of all backgrounds to preparedata and build time series forecasting models in a single interface with confidence.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, data modeling, and data visualization.
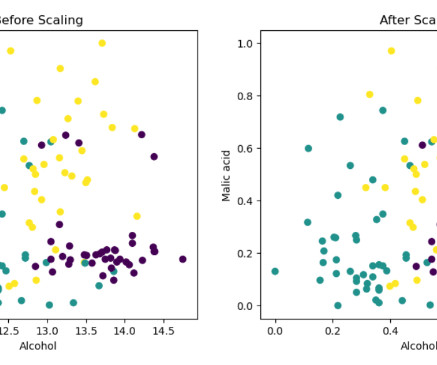
Feature Engineering is a process of using domain knowledge to extract and transform features from raw data. These features can be used to improve the performance of Machine Learning Algorithms. Normalization A feature scaling technique is often applied as part of datapreparation for machine learning.
This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data. The goal of datapreparation is to present data in the best forms for decision-making and problem-solving.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content