This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
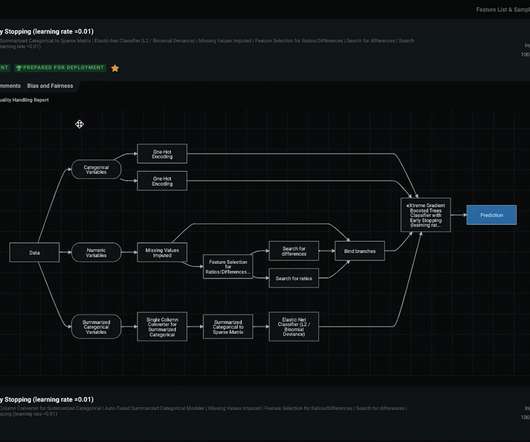
The development of a Machine Learning Model can be divided into three main stages: Building your ML datapipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. Cleaning data: Once the data has been gathered, it needs to be cleaned.
Their expertise lies in designing algorithms, optimizing models, and integrating them into real-world applications. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on dataanalysis and interpretation to extract meaningful insights.
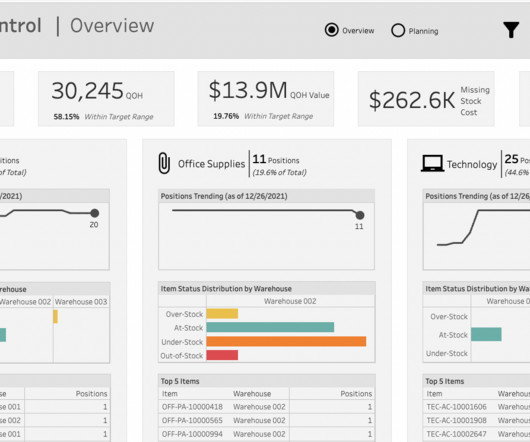
There are also plenty of data visualization libraries available that can handle exploration like Plotly, matplotlib, D3, Apache ECharts, Bokeh, etc. In this article, we’re going to cover 11 data exploration tools that are specifically designed for exploration and analysis. Output is a fully self-contained HTML application.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Ingest your data and DataRobot will use all these data points to train a model—and once it is deployed, your marketing team will be able to get a prediction to know if a customer is likely to redeem a coupon or not and why. Ultimately, only the best algorithms that solve specific problems will survive.
This is a perfect use case for machine learning algorithms that predict metrics such as sales and product demand based on historical and environmental factors. Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction.
So today I’m going to talk about an approach I often use to help remedy the time burden: reusable data cleaning pipelines. As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs.
So today I’m going to talk about an approach I often use to help remedy the time burden: reusable data cleaning pipelines. As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs.
So today I’m going to talk about an approach I often use to help remedy the time burden: reusable data cleaning pipelines. As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. Advanced algorithms recognize patterns in temporal data effectively. Making Data Stationary: Many forecasting models assume stationarity.
Data Preparation: Cleaning, transforming, and preparing data for analysis and modelling. Algorithm Development: Crafting algorithms to solve complex business problems and optimise processes. Data Visualization: Ability to create compelling visualisations to communicate insights effectively.
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do dataanalysis BI report generation/dataanalysis In BI/dataanalysis world, people usually need to query data (small/large).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content