This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The K-NearestNeighbor (KNN) algorithm is an intriguing method in the realm of supervised learning, celebrated for its simplicity and intuitive approach to predicting outcomes. Often employed for both classification and regression tasks, KNN leverages the proximity of data points to derive insights and make decisions.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithms learn from labeled data , similar to classification.
Ultimately, we can use two or three vital tools: 1) [either] a simple checklist, 2) [or,] the interdisciplinary field of project-management, and 3) algorithms and data structures. To the rescue (!): To recap, those twelve elements (e.g. What problem-solving tools next digital age has to offer Thanks to Moore’s law (e.g., IoT, Web 3.0,
It’s an integral part of data analytics and plays a crucial role in data science. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
This reveals hidden patterns that might have been overlooked in traditional dataanalysis methods. The search involves a combination of various algorithms, like approximate nearestneighbor optimization, which uses hashing, quantization, and graph-based detection.
The objective is to construct models that can accurately predict the class of new, unseen data, making classification a cornerstone of dataanalysis. This type of task requires algorithms that can scrutinize complex interactions within the data to make accurate predictions.
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Nevertheless, its applications across classification, regression, and anomaly detection tasks highlight its importance in modern data analytics methodologies.
Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme. Shall we unravel the true meaning of machine learning algorithms and their practicability?
Step-by-step process Collect observational data: Gather extensive datasets that track various events over time to inform causal relationships. Discover causal relationships: Algorithms sift through data, uncovering connections that signify causality rather than simply correlation.
In this article, we will discuss the KNN Classification method of analysis. What Is the KNN Classification Algorithm? The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Its internal deployment strengthens our leadership in developing dataanalysis, homologation, and vehicle engineering solutions. Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. It entails developing computer programs that can improve themselves on their own based on expertise or data. What is Unsupervised Machine Learning?
Common machine learning algorithms for supervised learning include: K-nearestneighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. If a data point appears further away from a dense section of points, it is considered an anomaly.
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. By the end of the lesson, readers will have a solid grasp of the underlying principles that enable these applications to make suggestions based on dataanalysis.
Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many data scientists. Without this library, dataanalysis wouldn’t be the same without pandas, which reign supreme with its powerful data structures and manipulation tools.
Anomaly Detection in Machine Learning: An approach to dataanalysis and Machine Learning called “anomaly detection,” also referred to as “outlier detection,” focuses on finding data points or patterns that considerably differ from what is considered to be “normal” or anticipated behaviour.
Key steps involve problem definition, data preparation, and algorithm selection. Data quality significantly impacts model performance. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data.
Data Cleaning: Raw data often contains errors, inconsistencies, and missing values. Data cleaning identifies and addresses these issues to ensure data quality and integrity. Data Visualisation: Effective communication of insights is crucial in Data Science.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Looking for the source code to this post?
This data shows promise for the binary classifier that will be built. Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. Figure 5 shows the methods used to perform these data preprocessing techniques.
Read the full blog here — [link] Data Science Interview Questions for Freshers 1. What is Data Science? Data processing does the task of exploring the data, mining it, and analyzing it which can be finally used to generate the summary of the insights extracted from the data. What is the main advantage of sampling?
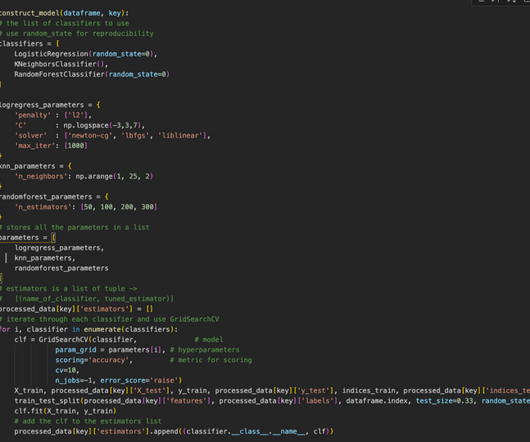
That post was dedicated to an exploratory dataanalysis while this post is geared towards building prediction models. In our exercise, we will try to deal with this imbalance by — Using a stratified k-fold cross-validation technique to make sure our model’s aggregate metrics are not too optimistic (meaning: too good to be true!)
Heart disease stands as one of the foremost global causes of mortality today, presenting a critical challenge in clinical dataanalysis. Leveraging hybrid machine learning techniques, a field highly effective at processing vast healthcare data volumes is increasingly promising in effective heart disease prediction.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content