This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
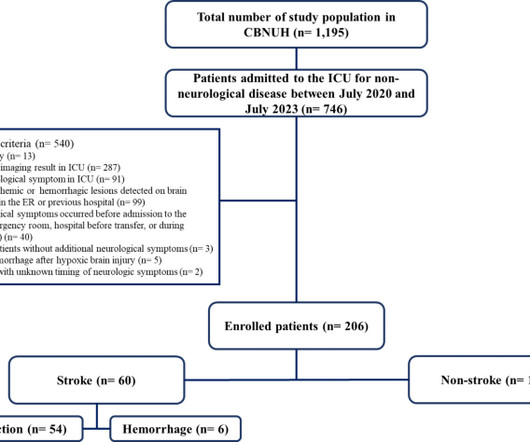
Several additional approaches were attempted but deprioritized or entirely eliminated from the final workflow due to lack of positive impact on the validation MAE. He is interested in researching human cognition and computational methods for modeling the brain. Her primary interests lie in theoretical machine learning.
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. The SVM algorithm requires the tuning of several parameters to achieve optimal performance.
Using the Categorical Boosting (CatBoost) algorithm with Bayesian optimization for hyperparameter selection and k-fold cross-validation to mitigate overfitting, we analyzed model-feature relationships with SHapley Additive exPlanations (SHAP) values.
AI engineering is the discipline focused on developing tools, systems, and processes to enable the application of artificial intelligence in real-world contexts, which combines the principles of systems engineering, software engineering, and computerscience to create AI systems.
Models were trained and cross-validated on the 2018, 2019, and 2020 seasons and tested on the 2021 season. To avoid leakage during cross-validation, we grouped all plays from the same game into the same fold. He has a degree in Mathematics and ComputerScience from the University of Illinois at Urbana Champaign.
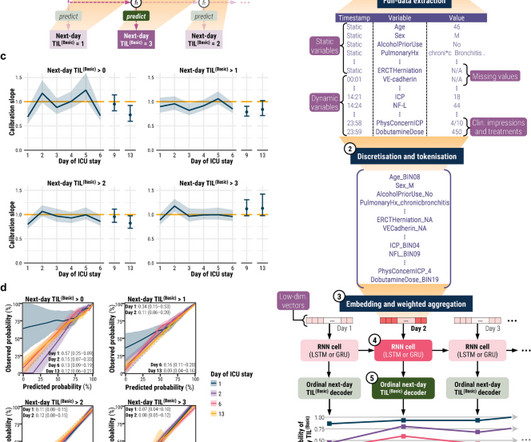
With 20 repeats of fivefold cross-validation, we trained TILTomorrow on different variable sets and applied the TimeSHAP (temporal extension of SHapley Additive exPlanations) algorithm to estimate variable contributions towards predictions of next-day changes in TIL(Basic).
Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed.
In this tutorial, you will learn the magic behind the critically acclaimed algorithm: XGBoost. But all of these algorithms, despite having a strong mathematical foundation, have some flaws or the other. The goal is to nullify the abstraction created by packages as much as possible. What Is XGBoost?
Summary: Machine Learning Engineer design algorithms and models to enable systems to learn from data. A Machine Learning Engineer plays a crucial role in this landscape, designing and implementing algorithms that drive innovation and efficiency. In finance, they build models for risk assessment or algorithmic trading.
Basic Data Science Terms Familiarity with key concepts also fosters confidence when presenting findings to stakeholders. Below is an alphabetical list of essential Data Science terms that every Data Analyst should know. Anomaly Detection: Identifying unusual patterns or outliers in data that do not conform to expected behaviour.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. We perform a five-fold cross-validation to select the best model during training, and perform hyperparameter optimization to select the best settings on multiple model architecture and training parameters.
Advance algorithms and analytic approaches for early prediction of AD/ADRD, with an emphasis on explainability of predictions. Top solvers from Phase 2 demonstrate algorithmic approaches on diverse datasets and share their results at an innovation event. Phase 2 [Build IT!] Phase 3 [Put IT All Together!]
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content