This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
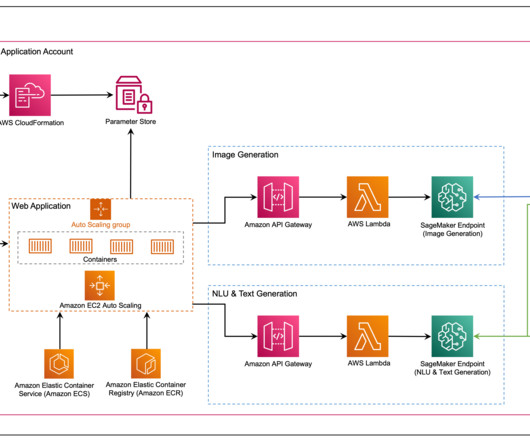
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
Clustering is a technique that can be used to get a sense of the data while allowing to tell a powerful story. But it can be a huge challenge, even for an expert code-centric data scientist, to understand the signal captured by the algorithm. Introducing Multimodal Clustering. Multimodal Clustering Autopilot.
from local or virtual machine to K8s cluster) and the need for bespoke deployments. Iguazio allows the team to go from testing code locally to running at scale on a remote cluster within minutes. Two types of algorithms are used: one pre-trained and one trained live using a rolling time window frame.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. It is open-source, so it is free to use and modify.
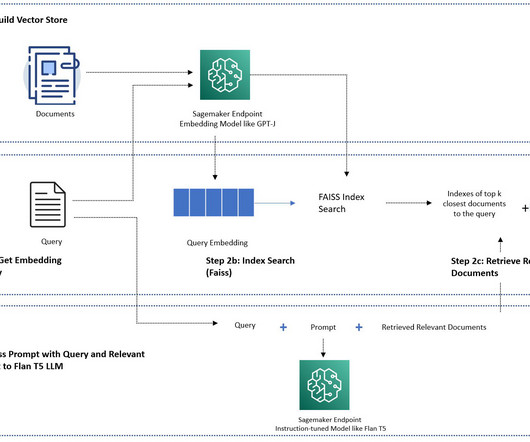
For this demo we are using employee sample data csv file which is uploaded in colab’s environment. Creating vectorstore For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors.
For this demo we are using employee sample data csv file which is uploaded in colab’s environment. CREATING VECTORSTORE For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors.
it’s possible to build a robust image recognition algorithm with high accuracy. Multimodal Clustering. Multimodal Clustering provides users with a one-click, one line-of-code experience to build and deploy clustering models on any data, including images. Get Started for Free or reach out to our team to request a demo.
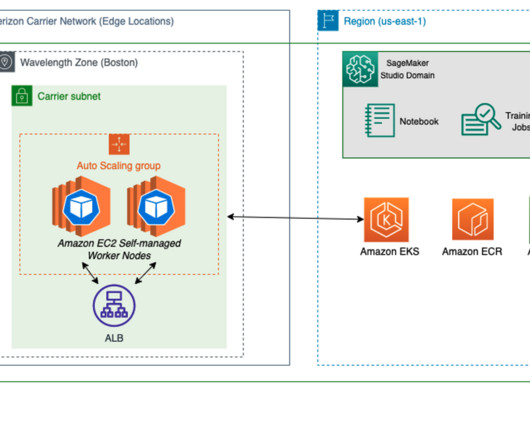
To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. Although AWS offers a number of options for model training—from AWS Marketplace models and SageMaker built-in algorithms—there are a number of techniques to deploy open-source ML models.
In this blog, we’ll review the DataRobot new Time Series clustering feature, which gives you a creative edge to build time series forecasting models by automatically grouping series that are identical to each other and then building models tailored to these groups. Unlocking New Business Opportunities with AI Forecasting.
The following demo shows Agent Creator in action. Data retrieval and augmentation – When a query is initiated, the Vector Database Snap Pack retrieves relevant vectors from OpenSearch Service using similarity search algorithms to match the query with stored vectors. He currently is working on Generative AI for data integration.
I realized that the algorithm assumes that we like a particular genre and artist and groups us into these clusters, not letting us discover and experience new music. After scaling the data, I used the XGBoost algorithm to train the model to classify the data and joblib to save the model.
For information about how to use JumpStart models programmatically, see Use SageMaker JumpStart Algorithms with Pretrained Models. Fargate is a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters or virtual machines. Vpc(self, "VPC", nat_gateways=1, ip_addresses=ec2.IpAddresses.cidr("10.0.0.0/16"),
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
This makes it easier for you to understand the algorithm and the different techniques used in Machine Learning. Moreover, you will also learn the use of clustering and dimensionality reduction algorithms. However, a basic understanding of programming can help you optimise the algorithm.
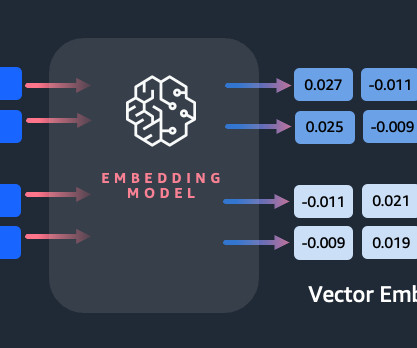
This technique is achieved through the use of ML algorithms that enable the understanding of the meaning and context of data (semantic relationships) and the learning of complex relationships and patterns within the data (syntactic relationships). There are multiple techniques to convert a sentence into a vector.
In this technical post, we’ll focus on some changes we’ve made to allow custom models to operate as an algorithm on Algorithmia, while still feeding predictions, input, and other metrics back to the DataRobot MLOps platform —a true best of both worlds. The Demo: Autoscaling with MLOps. Autoscaling Deployments with Trust.
With a few taps on a mobile device, riders request a ride; then, Uber’s algorithms work to match them with the nearest available driver and calculate the optimal price. Automation enabled Uber to grow to their current state with more than 256 petabytes of data, 3,000 nodes and 12 clusters. But the simplicity ends there.
If the in-memory FAISS doesn’t fit into your large dataset, we provide you with a SageMaker KNN algorithm to perform the semantic search, which also uses FAISS as the underlying searching algorithm. In this demo, we use a Jumpstart Flan T5 XXL model endpoint. The underlying algorithm used to index the data is FAISS.
The demo implementation code is available in the following GitHub repo. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms.
DataRobot’s AutoML uses different feature engineering techniques and a variety of machine learning algorithms to identify the best model for multilabel classification. Upon further reflection of the embeddings, it’s possible to see clusters of particular molecules. Request a demo. See DataRobot in Action.
SageMaker automatic model tuning, also known as hyperparameter tuning, finds the best version of a model by running many training jobs on your dataset using the algorithm and ranges of hyperparameters that you specify. In addition to HPO, model performance is also dependent on the algorithm. Demo notebook.
They fine-tuned BERT, RoBERTa, DistilBERT, ALBERT, XLNet models on siamese/triplet network structure to be used in several tasks: semantic textual similarity, clustering, and semantic search. I tend to view LIT as an ML demo on steroids for prototyping. old mermaid money found on the Titanic ? Broadcaster Stream API Fast.ai
Source code projects provide valuable hands-on experience and allow you to understand the intricacies of machine learning algorithms, data preprocessing, model training, and evaluation. Wine Quality Prediction In this blog, we will build a simple Wine Quality Prediction model using the Random Forest algorithm.
HOGs are great feature detectors and can also be used for object detection with SVM but due to many other State of the Art object detection algorithms like YOLO, and SSD , present out there, we don’t use HOGs much for object detection. Check out the demo here… [link] 21. Check out the demo here… [link] 24.
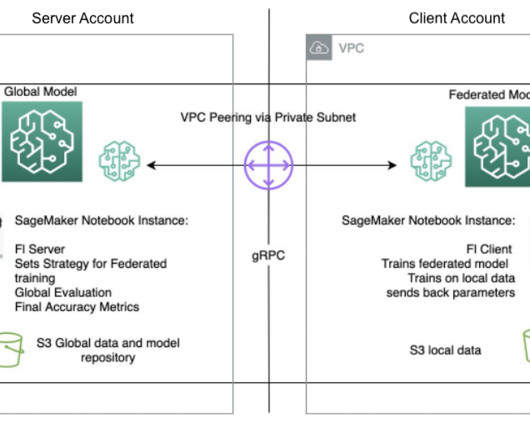
Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. Flower has an extensive implementation of FL averaging algorithms and a robust communication stack. Each account or Region has its own training instances.
Our graph visualization SDKs include performance demos, so you can run layouts of thousands of chart items and monitor the frames per second (FPS) rate for comparison. Format: Open source automatic graph drawing/design tool that uses a simple graph description language (DOT) for nodes, edges, clusters etc. Cytoscape.js
Control algorithm. It provides an out-of-the-box implementation of Madgwick’s filter , an algorithm that fuses angular velocities (from the gyroscope) and linear accelerations (from the accelerometer) to compute an orientation wrt the Earth’s magnetic field. Depending on the context, this assumption may be too optimistic.
We cover prompts for the following NLP tasks: Text summarization Common sense reasoning Question answering Sentiment classification Translation Pronoun resolution Text generation based on article Imaginary article based on title Code for all the steps in this demo is available in the following notebook.
Graph algorithms can pick out degrees of separation between individuals, for example, or find the most influential people in a graph – as we’ll find out later on. Request full access to our KronoGraph SDK, demos and live-coding playground. Request full access to our SDKs, demos and live-coding playgrounds.
The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution. Rather than all-or-nothing magical thinking, the best solutions leverage what algorithms and humans do well to create a system that delivers the best results.
We build ML systems to solve deep scientific and engineering challenges in areas of language, music, visual processing, algorithm development, and more. demos and Q&A sessions). Visit the @GoogleAI Twitter account to find out about Google booth activities (e.g.,
in a 2D space based on the machine learning algorithm used. However, in the real world, the embedding algorithms will generate a vector of hundreds of dimensions (as opposed to 2 dimensions in the above diagram) for any given input text. For example, a vector embedding of the word cat can be = [0.5, -0.4]
This keynote will also include a live demo of transfer learning and deployment of a transformer model using Hugging Face and MLRun; showcasing how to make the whole process efficient, effective, and collaborative. This session will discuss the algorithm and how further research using models can help to predict treatment outcomes.
The demo from the session highlights unique and differentiated capabilities that empower all users—from the analysts to the data scientists and even the person at the end of the journey who just needs to access an instant price estimate. The algorithm blueprint, including all steps taken, can be viewed for each item on the leaderboard.
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 Currently, published research may be spread across a variety of different publishers, including free and open-source ones like those used in many of this challenge's demos (e.g.
It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And then once they’re done with that, it’s very easy to package up, and you’ll see that in the demo today. The demo is actually very simple.
It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And then once they’re done with that, it’s very easy to package up, and you’ll see that in the demo today. The demo is actually very simple.
In particular, the following groups come to mind: Deep learning researchers: Many visualization techniques are first developed by academic researchers looking to improve existing deep learning algorithms or to understand why a particular model exhibits a certain characteristic. All of these visualizations do not only satisfy curiosity.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. Conclusion To get started today with SnapGPT, request a free trial of SnapLogic or request a demo of the product. Greg has published research in the areas of operating systems, parallel computing, and distributed systems.
With Dr. Jon Krohn you’ll also get hands-on code demos in Jupyter notebooks and strategic advice for overcoming common pitfalls. You’ll learn how to leverage the benefits of both technologies and how to improve model accuracy using combined global and local search strategies, such as genetic algorithms and generating set searches.
Completion.execute( sm_endpoint=endpoint_name, prompt="Explain deep learning algorithms to 8th graders", numResults=1, maxTokens=100, temperature=0.01 #subject to reduce “hallucination” by using common words. As an alternative, you can use FAISS , an open-source vector clustering solution for storing vectors.
All the steps in this demo are available in the accompanying notebook Fine-tuning text generation GPT-J 6B model on a domain specific dataset. learning_rate – Controls the step size or learning rate of the optimization algorithm during training. He focuses on developing scalable machine learning algorithms.
Try the live demo! Supervised learning algorithms have been improving quickly, leading many people to anticipate a new wave of entirely un supervised algorithms : algorithms so “advanced” they can compute whatever you want, without you specifying what that might be. Human time and attention is precious.
For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Scale AI combines human annotators and machine learning algorithms to deliver efficient and reliable annotations for your team.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















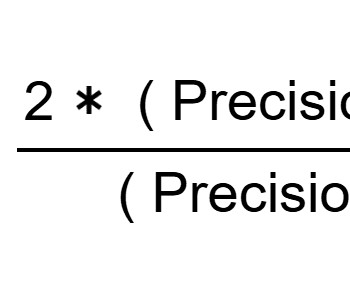















Let's personalize your content