This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift data warehouse.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
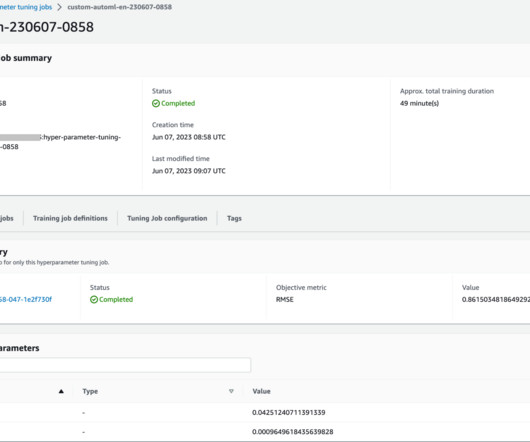
The Ranking team at Booking.com plays a pivotal role in ensuring that the search and recommendation algorithms are optimized to deliver the best results for their users. Essential ML capabilities such as hyperparameter tuning and model explainability were lacking on premises.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects.
Let us now look at the key differences starting with their definitions and the type of data they use. Definition of Supervised Learning and Unsupervised Learning Supervised learning is a process where an ML model is trained using labeled data. In this case, every data point has both input and output values already defined.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
Let’s get started with the best machine learning (ML) developer tools: TensorFlow TensorFlow, developed by the Google Brain team, is one of the most utilized machine learning tools in the industry. Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis.
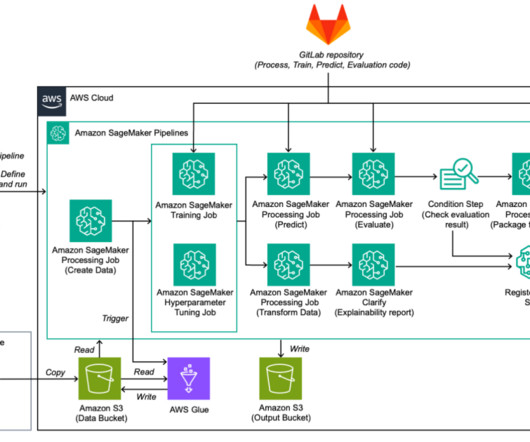
Amazon SageMaker Pipelines includes features that allow you to streamline and automate machine learning (ML) workflows. This helps with datapreparation and feature engineering tasks and model training and deployment automation. Ensemble models are becoming popular within the ML communities.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
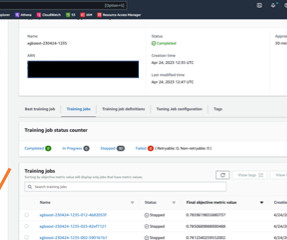
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. SageMaker Training is a managed batch ML compute service that reduces the time and cost to train and tune models at scale without the need to manage infrastructure. SageMaker-managed clusters of ml.p4d.24xlarge
For any machine learning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. writefile opt/ml/model/inference.py Python script that serves as the entry point.
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many MLalgorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed.
Custom geospatial machine learning : Fine-tune a specialized regression, classification, or segmentation model for geospatial machine learning (ML) tasks. While this requires a certain amount of labeled data, overall data requirements are typically much lower compared to training a dedicated model from the ground up.
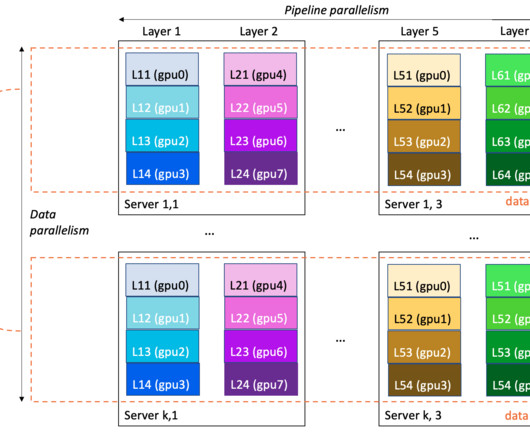
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. Another way can be to use an AllReduce algorithm.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Introduction to Deep Learning Algorithms: Deep learning algorithms are a subset of machine learning techniques that are designed to automatically learn and represent data in multiple layers of abstraction. This process is known as training, and it relies on large amounts of labeled data. How Deep Learning Algorithms Work?
As Data Scientists, we all have worked on an ML classification model. In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? Let’s take a look at some of them.
5 Industries Using Synthetic Data in Practice Here’s an overview of what synthetic data is and a few examples of how various industries have benefited from it. How to Use Machine Learning for Algorithmic Trading Machine learning has proven to be a huge boon to the finance industry. Here’s how.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. The global Machine Learning market was valued at USD 35.80
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Importance of Data in AI Quality data is the lifeblood of AI models, directly influencing their performance and reliability.
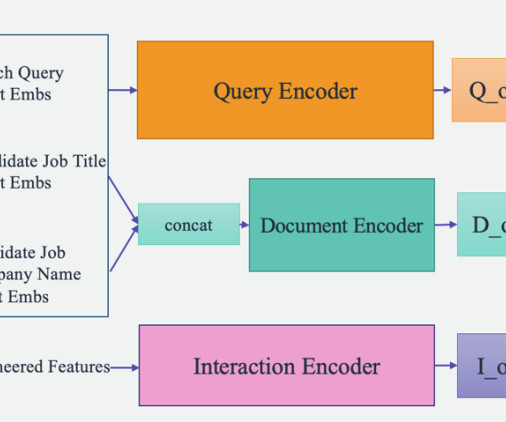
The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. The system is developed by a team of dedicated applied machine learning (ML) scientists, ML engineers, and subject matter experts in collaboration between AWS and Talent.com.
Note : Now write some articles or blogs on the things you have learned because this thing will help you to develop soft skills as well if you want to publish some research paper on AI/ML so this writing habit will help you there for sure. Performance Metrics These are used to evaluate the performance of a machine-learning algorithm.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
Established in 1987 at the University of California, Irvine, it has become a global go-to resource for ML practitioners and researchers. The UCI Machine Learning Repository is a well-known online resource that houses vast Machine Learning (ML) research and applications datasets. The global Machine Learning market continues to expand.
Domain knowledge is crucial for effective data application in industries. What is Data Science and Artificial Intelligence? Data Science is an interdisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data.
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machine learning (ML) APIs for model development (public preview) and deployment (private preview). Machine Learning Training machine learning (ML) models can sometimes be resource-intensive.
Some CUDA versions may require a minimum CC to be available, and CUDA versions may be required for certain frameworks and algorithms. The formula: [ AI = frac{text{FLOPs}}{text{Bytes Transferred to/from Memory}} ] FLOPs - The number of floating-point operations required by your algorithm. This is the just foundation.
By 2025, according to Gartner, chief data officers (CDOs) who establish value stream-based collaboration will significantly outperform their peers in driving cross-functional collaboration and value creation. These datapreparation tasks are otherwise time consuming, so having DataRobot’s automation here is a huge time saver.
Data Science Knowing the ins and outs of data science encompasses the ability to handle, analyze, and interpret data, which is required for training models and understanding their outputs. Knowledge in these areas enables prompt engineers to understand the mechanics of language models and how to apply them effectively.
Data Management Costs Data Collection : Involves sourcing diverse datasets, including multilingual and domain-specific corpora, from various digital sources, essential for developing a robust LLM. While the use of pre-trained models is free, fine-tuning them for specific tasks can lead to costs related to computing and data handling.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times. If all goes well, of course ?
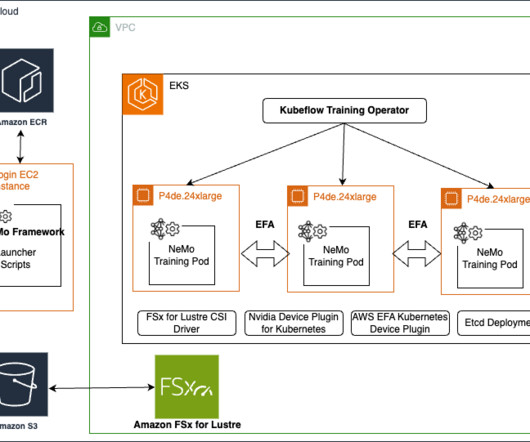
These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. In this post, we present a step-by-step guide to run distributed training workloads on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. You must be independent and self-organized. v=AFoMsLMZKik [1] https://www.youtube.com/watch?
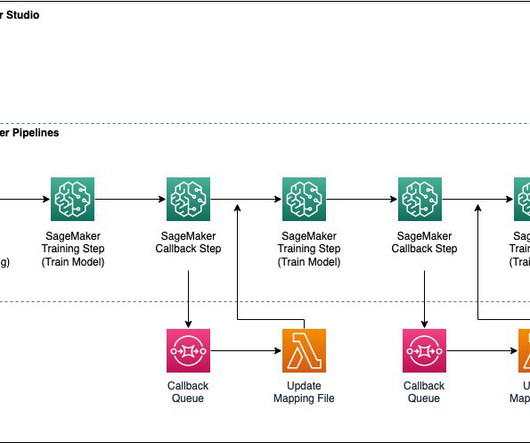
We cover the setup process and provide a step-by-step guide to running a NeMo job on a SageMaker HyperPod cluster. It includes default configurations for compute cluster setup, data downloading, and model hyperparameters autotuning, which can be adjusted to train on new datasets and models.
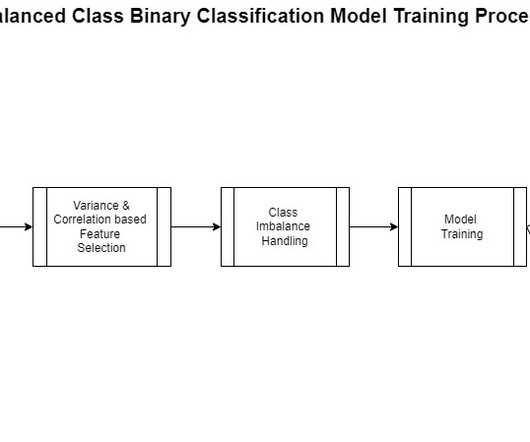
Over sampling and under sampling are pivotal strategies in the realm of data analysis, particularly when tackling the challenge of imbalanced data classes. Purpose of over sampling and under sampling Understanding the necessity of these techniques sheds light on their applications in various domains, particularly in AI and ML.
Amazon SageMaker is a comprehensive, fully managed machine learning (ML) service to build, train, and deploy LLMs and other FMs at scale. We use Amazon SageMaker Studio , a comprehensive web-based integrated development environment (IDE) designed to facilitate all aspects of ML development.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content