This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Clusteringalgorithms play a vital role in the landscape of machine learning, providing powerful techniques for grouping various data points based on their intrinsic characteristics. What are clusteringalgorithms? Key criteria include: The number of clusters data points can belong to.
The idea is deceptively simple: represent most machine learning algorithmsclassification, regression, clustering, and even large language modelsas special cases of one general principle: learning the relationships between data points. A state-of-the-art image classification algorithm requiring zero human labels.
Density-based clustering stands out in the realm of data analysis, offering unique capabilities to identify natural groupings within complex datasets. What is density-based clustering? This method effectively distinguishes dense regions from sparse areas, identifying clusters while also recognizing outliers.
It plays a crucial role in improving data interpretability, optimizing algorithm efficiency, and preparing datasets for tasks like classification and clustering. This article explores data discretisation’s methodologies, benefits, and applications, offering […] The post What is Discretization in Machine Learning?
Program 1 from sklearn.cluster import KMeans import pandas as pd # Sample data data = pd.DataFrame({ "Income": [15000, 16000, 90000, 95000, 60000, 62000,65000,98000,12000], "SpendingScore": [90, 85, 20, 15, 50, 55,54,23,94] }) # Apply K-Means... The post K-Means ClusteringAlgorithm appeared first on DataFlair.
The k-means algorithm is a cornerstone of unsupervised machine learning, known for its simplicity and trusted for its efficiency in partitioning data into a predetermined number of clusters.
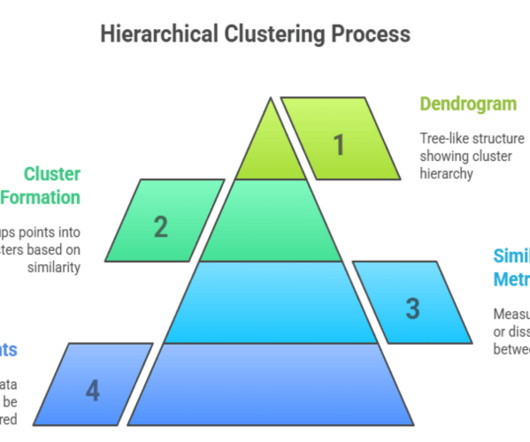
Summary: Hierarchical clustering in machine learning organizes data into nested clusters without predefining cluster numbers. Unlike partition-based methods such as K-means, hierarchical clustering builds a nested tree-like structure called a dendrogram that reveals the multi-level relationships between data points.
For many fulfilling roles in data science and analytics, understanding the core machine learning algorithms can be a bit daunting with no examples to rely on. This blog will look at the most popular machine learning algorithms and present real-world use cases to illustrate their application. What Are Machine Learning Algorithms?
torchft implements a few different algorithms for fault tolerance. These algorithms minimize communication overhead by synchronizing at specified intervals instead of every step like HSDP. We’re always keeping an eye out for new algorithms, such as our upcoming support for streaming DiLoCo.
cuML brings GPU-acceleration to UMAP and HDBSCAN , in addition to scikit-learn algorithms. It dramatically improves algorithm performance for data-intensive tasks involving tens to hundreds of millions of records. It dramatically improves algorithm performance for data-intensive tasks involving tens to hundreds of millions of records.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
The in-memory algorithms for approximate nearest neighbor search (ANNS) have achieved great success for fast high-recall search, but are extremely expensive when handling very large scale database. Thus, there is an increasing request for the hybrid ANNS solutions with small memory and inexpensive solid-state drive (SSD).
Figure 1: Gaussian mixture model illustration [Image by AI] Introduction In a time where deep learning (DL) and transformers steal the spotlight, its easy to forget about classic algorithms like K-means, DBSCAN, and GMM. Consider the everyday clustering puzzles: customer segmentation, social network analysis, or image segmentation.
Differentially expressed genes (DEGs) were identified using the edgeR algorithm with an FDR < 0.01 In addition, clustering analyses, machine learning models, and single-cell RNA sequencing (scRNA-seq) were employed to investigate the immune characteristics, prognostic value, and therapeutic relevance of these genes.
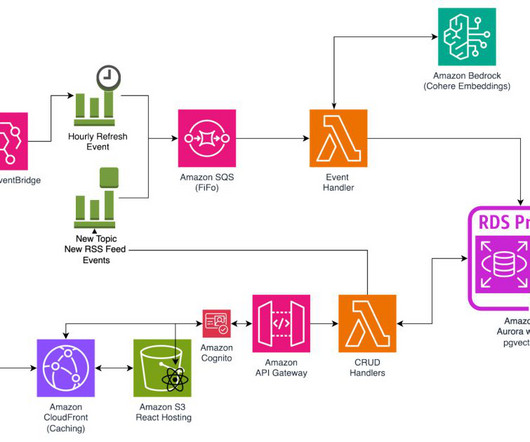
If you have a large-scale production workload and want to take the time to tune for the best price-performance and the most flexibility, you can use an OpenSearch Service managed cluster. For more details on best practices for operating an OpenSearch Service managed cluster, see Operational best practices for Amazon OpenSearch Service.
Program 1 Customer Segmentation Dataset Customer Segmentation Dataset 1 # Librires import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler # Step 1:... The post ML Project – Customer Segmentation Using K-Means Clustering appeared first (..)
It’s fascinating how organizations harness advanced algorithms to transform raw text into actionable insights, helping them understand customer sentiments and market trends. Clustering: Grouping similar data points to identify patterns. With the rise of big data, text mining becomes crucial for any entity looking to stay competitive.
A Mixture Model Approach for Clustering Time Series Data By Shenggang Li This article explores a mixture model approach for clustering time series data, particularly focusing on financial and biological applications. Our must-read articles 1.
The specific statistical technique used to calculate group membership is weighted clustering around medoids (using the WeightedCluster package version 1.4-1 The items selected for inclusion in the clustering were chosen based on extensive testing to find the model that fit the data best and produced groups that were substantively meaningful.
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
By allowing algorithms to learn autonomously, it opens the door to various innovative applications across different fields. This approach enables algorithms to uncover hidden structures and relationships within the data, facilitating a deeper understanding of the underlying patterns. What is unsupervised learning?
Algorithms can automatically clean and preprocess data using techniques like outlier and anomaly detection. GenAI can help by automatically clustering similar data points and inferring labels from unlabeled data, obtaining valuable insights from previously unusable sources.
It excels in soft clustering, handling overlapping clusters, and modelling diverse cluster shapes. Its ability to model complex, multimodal data distributions makes it invaluable for clustering , density estimation, and pattern recognition tasks. EM algorithm iteratively optimizes GMM parameters for best data fit.
However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE) , so that we can view them in two dimensions. The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning.
It usually comprises parsing log data into vectors or machine-understandable tokens, which you can then use to train custom machine learning (ML) algorithms for determining anomalies. You can adjust the inputs or hyperparameters for an ML algorithm to obtain a combination that yields the best-performing model. installed in them.
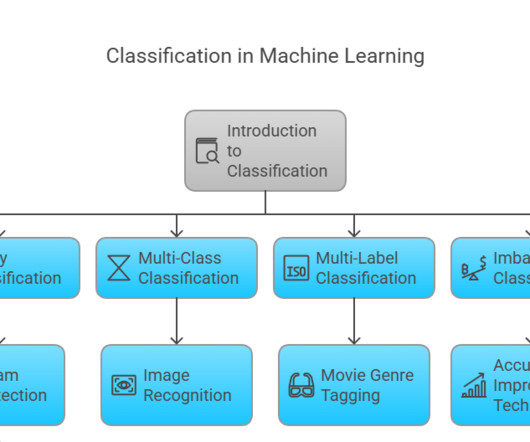
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
A right-sized cluster will keep this compressed index in memory. Disk mode uses the HNSW algorithm to build indexes, so m is one of the algorithm parameters, and it defaults to 16. Compression lowers cost by reducing the memory required by the vector engine, but it sacrifices accuracy in return.
Advanced algorithms analyze voice characteristics such as pitch, tone, and cadence to differentiate between participants, even when their speech overlaps or occurs in rapid succession. Both traditional clustering methods like K-means, or more advanced algorithms employing neural networks are common.
A generative AI company exemplifies this by offering solutions that enable businesses to streamline operations, personalise customer experiences, and optimise workflows through advanced algorithms. Data forms the backbone of AI systems, feeding into the core input for machine learning algorithms to generate their predictions and insights.
Machine learning: In data science, the dot product is often utilized to measure similarity between vectors, enhancing algorithms designed for classification and clustering. Real-world examples Engineering: Dot product calculations help optimize the angle of solar panels to maximize energy absorption from sunlight.
For this analysis we will only use the first two components, the result is a two-dimensional plot where similar operating conditions cluster together, besides the two main components we will use a gradient to represent the Remaining Useful Life (RUL). Ordering components by how much variance they explain. Source: Image by the author.
To search against the database, you can use a vector search, which is performed using the k-nearest neighbors (k-NN) algorithm. When you perform a search, the algorithm computes a similarity score between the query vector and the vectors of stored objects using methods such as cosine similarity or Euclidean distance.
Clustering in machine learning is a fascinating method that groups similar data points together. By organizing data into meaningful clusters, businesses and researchers can gain valuable insights into their data, facilitating decision-making across various domains. What is clustering in machine learning?
By developing an algorithm that transforms natural language propositions into structured coherence graphs, the researchers benchmark AI models’ ability to reconstruct logical relationships. To maximize coherence by separating true and false statements into different clusters. What is coherence-driven inference? The problem?
Liang, who began his career in smart imaging and later managed a research team, was praised for hiring top algorithm engineers and fostering a collaborative environment. The firm allocated 70% of its revenue towards AI research, building two supercomputing AI clusters, including one consisting of 10,000 Nvidia A100 chips during 2020 and 2021.
For instance, a classification algorithm could predict whether a transaction is fraudulent or not based on various features. Role of Algorithms in Associative Classification Algorithms play a crucial role in associative classification by automating the rule generation, evaluation, and classification process.
Yet, navigating the world of AI can feel overwhelming, with its complex algorithms, vast datasets, and ever-evolving tools. Essential AI Skills Guide TL;DR Key Takeaways : Proficiency in programming languages like Python, R, and Java is essential for AI development, allowing efficient coding and implementation of algorithms.
To illustrate, when the number of experts increases from 8 to 128, the forward passes of combinatorial pruning algorithms grow exponentially, from 70 to 2.4 × 10³⁷. Specifically, it first identifies clusters of similar experts based on their behavioral similarity.
OpenAI lays out its grand AI blueprint for Europe The spare-part SLA forces regional warehousing and tighter demand-planning algorithms, yet it also unlocks new paid-service streams. Firmware teams need a five-year patch runway, compelling longer-term developer staffing and codebase modularisation.
Explore the model pre-training workflow from start to finish, including setting up clusters, troubleshooting convergence issues, and running distributed training to improve model performance. In this builders’ session, learn how to pre-train an LLM using Slurm on SageMaker HyperPod.
The MTEB Leaderboard provides a standardized comparison of embedding models across diverse tasks and datasets, including retrieval, clustering, classification, and reranking. Leveraging hybrid search , which combines keyword search algorithms like BM25 and semantic search with embeddings.
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
To use the dataset to train the model, you need to first do some pre-processing, You can run the pre-processing code in your JupyterLab application or on a SageMaker ephemeral cluster as a SageMaker Training job using the @remote decorator. In both cases, you can track your experiments using MLflow.
His primary focus lies in using the full potential of data, algorithms, and cloud technologies to drive innovation and efficiency. His areas of expertise include machine learning and MLOps, with particular emphasis on document processing, natural language processing, and large language models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content