This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The large language models (LLMs) that underpin products like OpenAI's ChatGPT, for instance, need to devour enormous datasets of written words to fine tune an algorithm to follow the rules of language. They're so hungry for raw data, in fact, that original material for these algorithms to gobble up is becoming hard to come by.
Matthew Mayo ( @mattmayo13 ) holds a masters degree in computerscience and a graduate diploma in data mining. As managing editor of KDnuggets & Statology , and contributing editor at Machine Learning Mastery , Matthew aims to make complex data science concepts accessible.
Automate the Boring Stuff With Python (Al Sweigart) Platform: Automate the Boring Stuff Level: Beginner to intermediate Why Take It: This book is made available for free by its author. It teaches Python by automating repetitive computer tasks, which makes it practical and immediately applicable to real life.
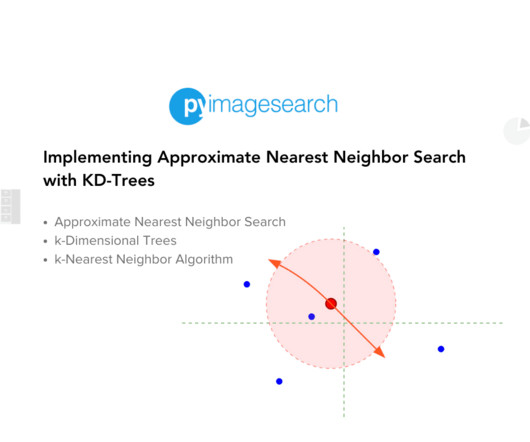
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
Approach To address this issue, Pfizer implemented Machine Learning algorithms that analysed historical maintenance data to forecast future maintenance needs. Implementation Data Scientists created algorithms that processed vast datasets to identify trends and preferences among users. Frequently Asked Questions What is Data Science?
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module.
Data retrieval and augmentation – When a query is initiated, the Vector Database Snap Pack retrieves relevant vectors from OpenSearch Service using similarity search algorithms to match the query with stored vectors. He focuses on Deep learning including NLP and Computer Vision domains.
These problems require a diverse skillset, drawing from fields like computer vision, sequence modeling, generative models, and working with 3D mesh data. This also involves techniques like non-linear optimization and graph algorithms. Have you read any good books or articles recently? It's a book about symmetry in our world.
Sign In Sign Up Communications of the ACM About Us Frequently Asked Questions Contact Us Follow Us CACM on Twitter CACM on Reddit CACM on LinkedIn News Architecture and Hardware An Algorithm for a Better Bookshelf Managing the strategic positioning of empty spaces. Blelloch described it as “a very elegant result.”
A Princeton graduate with a degree in ComputerScience, Jerry is passionate about building tools that enable developers to create scalable, intelligent LLM-powered systems. She is the co-author of Graph Algorithms and Knowledge Graphs from O’Reilly, and a contributor to Massive Graph Analytics (Routledge) and AI on Trial (Bloomsbury).
Beyond the out-of-control cost, there is evidence that degrees do not map to the skills needed in today’s job market, and there’s an increasing disconnect—particularly in computerscience—between the skills employers want and the skills colleges teach. And too many companies fail because they can’t question their own assumptions.
This algorithm takes advantage of the frequency of occurrence of each data item (e.g., Huffman encoding is a prime example of a lossless compression algorithm. Huffman encoding is a widely used lossless data compression algorithm. Or requires a degree in computerscience? What Is Huffman Encoding?
Williams proof relies on a space-efficient tree evaluation algorithm by James Cook and Ian Mertz from last years STOC conference. Cook and Mertzs algorithm builds on earlier work on catalytic computing, highlighted in a recent Quanta article. Williams then applies the tree evaluation algorithm of Cook and Mertz.
This branch of mathematics is particularly important in the context of optimization algorithms, which are used to fine-tune machine learning models to achieve the best possible performance. This important property is the basis of all gradient-based optimization algorithms in machine learning (as we will see later in this post).
I hold a Master’s in ComputerScience and have published research in AI. I'm known in the Rails world for my writing (including a book) on the Hotwire stack. I am also an improvisational pianist, published poet, and I've created novel algorithms and tools for studying and composing both music and poetry.
Knowledge engineering combines principles from computerscience and artificial intelligence to create systems that emulate the reasoning of human experts. Inference making: Using algorithms to draw conclusions based on the knowledge base. What is knowledge engineering?
Gram-Schmidt Process for QR Factorization The Gram-Schmidt algorithm ( Figure 4 ) is a method for obtaining the QR factorization of a matrix by orthogonalizing its columns. Gram-Schmidt Algorithm Given a matrix with columns , the goal is to decompose into an orthogonal matrix and an upper triangular matrix. 0.82807867 2.76026224] [ 0.
TLDR: In this article we will explore machine learning definitions from leading experts and books, so sit back, relax, and enjoy seeing how the field’s brightest minds explain this revolutionary technology! ” What makes Chollet’s definition stand out among other definitions is the inclusion of art alongside science.
Accor Group , a major hospitality company that developed a generative AI-powered booking application, showcased how, even when working with new technologies like generative AI, fundamental software development principles remain a must-have. He holds a PhD in Mathematics & ComputerScience on large-scale data management.
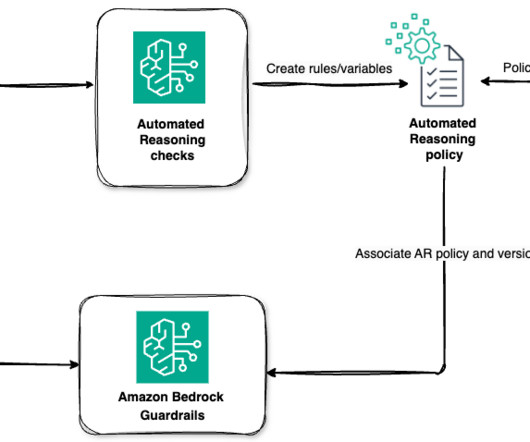
Through logic-based algorithms and mathematical validation, Automated Reasoning checks validate LLM outputs against domain knowledge encoded in the Automated Reasoning policy to help prevent factual inaccuracies. Applied Scientist in the Automated Reasoning Group and holds a PhD in ComputerScience. Nafi Diallo is a Sr.
And the other unspoken superpower often not mentioned except in furtive whispers is “Cracking the LinkedIn Algorithm Code”. 1: Andrew Ng He is the co-founder of Coursera and founder of DeepLearning.AI , and an Adjunct Professor at Stanford University’s ComputerScience Department. They teach. They question.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about data science and Bayesian statistics. in computerscience from the University of California, Berkeley; and Bachelors and Masters degrees fromMIT.
If you want to work on operating production critical databases in the cloud on k8s + write data-driven algorithms for autoscaling, consider applying! Fun engineering challenges: These include complex distributed systems, low-latency algorithms & infrastructure, and modeling sales calls with large language models.
books, courses, etc) reply jesse__ 8 hours ago | root | parent | next [–] Voxel engines are interesting because they're very much an area of active research. From a dev perspective this area has a ton of super interesting algorithmic / math / data structure applications, and computational geometry has always been special to me.
The library sorting problem is used across computerscience for organizing far more than just books. A new solution is less than a page-width away from the theoretical ideal.
While the digital world promotes the use of machines to to learn and create new things, the need and importance of books has always remained constant. Hence, books on AI and other technological developments remain important for the basics and more. What is Meant by Books on AI?
I am a graduate student in ComputerScience at UMass Amherst working with Gerome Miklau and Dan Sheldon. In 2022, my colleagues and I at UMass released AIM , a novel algorithm for differentially private synthetic data generation which outperforms many of the existing mechanisms across high-dimensional datasets.
Most modern animators rely on computer graphics and visualization techniques to create popular movies and TV shows like Finding Dory , Toy Story , and Paw Patrol. In the 1960s and ’70s, computerscience pioneers David Evans and IEEE Life Member Ivan E. IEEE Milestone Dedication: Utah Computer Graphics youtu.be
Generative AI harnesses deep learning algorithms to generate human-like data in response to user input. This technology finds applications in NLP, computer vision, autonomous driving, robotics, and more. Discover Quality Resources : Explore a variety of resources like online courses, books, and tutorials. Automate tasks?
Summary: This curated list of 20 Artificial Intelligence books for beginners highlights foundational concepts, coding practices, and ethical insights. This blog highlights the 20 best Artificial Intelligence books tailored for newcomers, offering practical insights, ethical considerations, and real-world applications.
Organized by John McCarthy , Marvin Minsky , Claude Shannon , and Nathaniel Rochester , it brought together a few dozen of the leading thinkers in AI, computerscience, and information theory to map out future paths for investigation. A group photo [shown above] captured seven of the main participants. Where Was the Photo Taken?
Home Table of Contents DETR Breakdown Part 2: Methodologies and Algorithms The DETR Model ?️ Summary Citation Information DETR Breakdown Part 2: Methodologies and Algorithms In this tutorial, we’ll learn about the methodologies applied in DETR. 2020) propose the following algorithm. Object Detection Set Prediction Loss ?
Coding, algorithms, statistics, and big data technologies are especially crucial for AI engineers. Soft skills are important in computerscience careers as well. CAIE™’s self-paced learning format enables candidates to learn through study books, hands-on videos with practice code, and eLearning materials with workshops.
As newer fields emerge within data science and the research is still hard to grasp, sometimes it’s best to talk to the experts and pioneers of the field. Recently, we spoke with Pedro Domingos, Professor of computerscience at the University of Washington, AI researcher, and author of “The Master Algorithm” book.
The next installment in ODSC’s popular lightning interview series will feature Pedro Domingos, Professor Emeritus of ComputerScience at the University of Washington and recipient of the SIGKDD Innovation Award. by Judea Pearl, author of The Book of Why, Professor of ComputerScience at UCLA and winner of the A.
You could write an algorithm that predicts the sales of comic books, and your model works well and produces high-accuracy predictions, but you need to know why. Or maybe it’s the opposite, your algorithm predicts completely wrong sales figures, and you need to figure out why. Disney+ has shows about comic book characters.
Read the Top 10 Statistics Books for Data Science Geometry and Topology 7. Information theory is used in many different areas of communication, computerscience, and statistics. It is also used in everyday life, such as when designing data compression algorithms and communication protocols.
That’s because AI algorithms are trained on data. And it’s safe to say that most AI algorithms are trained on datasets that are significantly older. Author’s note: Julia Stoyanovich is the co-author of a five-volume comic book on AI that can be downloaded free from GitHub. You turned left or right. Your coat was red or blue.
According to SEO Toronto Experts , AI engineers work on creating algorithms, building advanced techniques for data processing, and improving the reliability and performance of AI systems to ensure they solve problems that are complex in nature and efficiently optimize their operations. Then, what does an AI Engineer do?
They design, develop, and deploy the machine learning algorithms that power everything from self-driving cars to personalized recommendations. They are the driving force behind the artificial intelligence revolution, creating new opportunities and possibilities that were once the stuff of science fiction. They build the future.
Introduction Array are fundamental data structure in computerscience, widely used for storing collections of data. In programming, arrays are essential for tasks ranging from simple data storage to implementing complex algorithms. They allow programmers to manage and manipulate data efficiently.
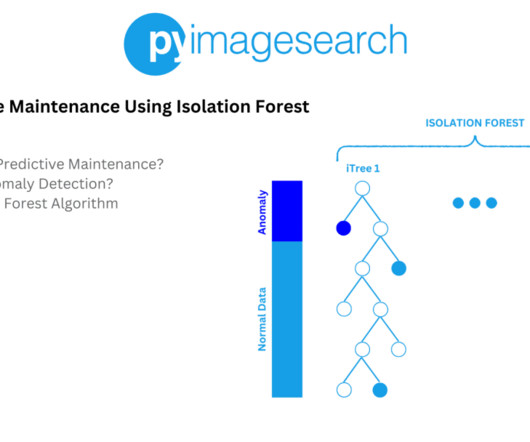
One such technique is the Isolation Forest algorithm, which excels in identifying anomalies within datasets. In this tutorial, you will learn how to implement a predictive maintenance system using the Isolation Forest algorithm — a well-known algorithm for anomaly detection. And Why Anomaly Detection?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content