This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Image credit: BlackJack3D via Getty Images) Scientists say they have made a breakthrough after developing a quantum computing technique to run machine learning algorithms that outperform state-of-the-art classical computers. The scientists used a method that relies on a quantum photonic circuit and a bespoke machine learning algorithm.
The complexity of SuperGLUE tasks drives researchers to develop more sophisticated models, leading to advanced algorithms and techniques. The complexity of HumanEval tasks drives researchers to develop more sophisticated models, leading to advanced algorithms and techniques.
The embeddings are generally compared via the inner-product similarity , enabling efficient retrieval through optimized maximum inner product search (MIPS) algorithms. We have provided an open-source implementation of our FDE construction algorithm on GitHub.
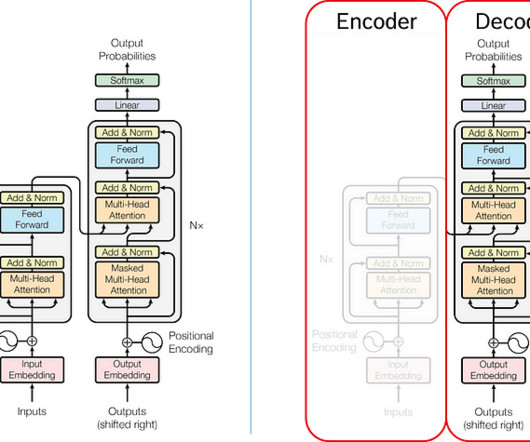
Nevertheless, when I started familiarizing myself with the algorithm of LLMs the so-called transformer I had to go through many different sources to feel like I really understood the topic.In How does the algorithm conclude which token to output next? this article, I want to summarize my understanding of Large Language Models.
Just like chemical elements fall into predictable groups, the researchers claim that machine learning algorithms also form a pattern. A state-of-the-art image classification algorithm requiring zero human labels. The I-Con framework shows that algorithms differ mainly in how they define those relationships. It predicts new ones.
This study employs data-driven artificial intelligence (AI) models supported by explainability algorithms and PSM causal inference to investigate the factors influencing students’ cognitive abilities, and it delved into the differences that arise when using various explainability AI algorithms to analyze educational data mining models.
For many fulfilling roles in data science and analytics, understanding the core machine learning algorithms can be a bit daunting with no examples to rely on. This blog will look at the most popular machine learning algorithms and present real-world use cases to illustrate their application. What Are Machine Learning Algorithms?
It is crucial to probability theory and a foundational element for more intricate statistical models, ranging from machine learning algorithms to customer behaviour prediction. A key idea in data science and statistics is the Bernoulli distribution, named for the Swiss mathematician Jacob Bernoulli. appeared first on Analytics Vidhya.
It plays a crucial role in improving data interpretability, optimizing algorithm efficiency, and preparing datasets for tasks like classification and clustering. Discretization is a fundamental preprocessing technique in data analysis and machine learning, bridging the gap between continuous data and methods designed for discrete inputs.
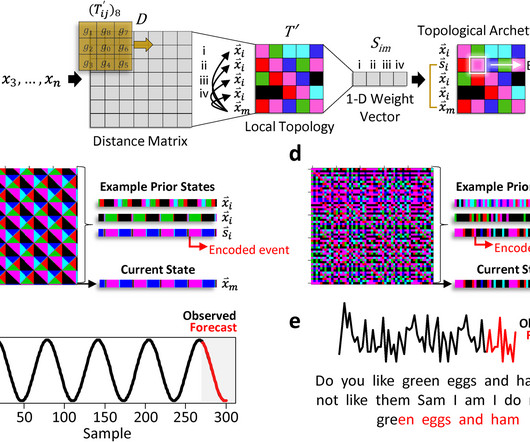
Here, we introduce a learning algorithm that avoids these drawbacks. Chomiak and Hu introduce a versatile time-series data prediction algorithm using recurring local topological patterning. All of these can limit model selection and performance.
Program 1 from sklearn.cluster import KMeans import pandas as pd # Sample data data = pd.DataFrame({ "Income": [15000, 16000, 90000, 95000, 60000, 62000,65000,98000,12000], "SpendingScore": [90, 85, 20, 15, 50, 55,54,23,94] }) # Apply K-Means... The post K-Means Clustering Algorithm appeared first on DataFlair.
It feels almost magical, but beneath that simplicity lies a world of intelligent decision-making powered by some of the most sophisticated algorithms in computer science. The answer lies in a combination of graph theory, real-time data, predictive modeling, and advanced optimization algorithms.
However, there is one important caveat: most of the current real-world successes of RL have been achieved with on-policy RL algorithms ( e.g. , REINFORCE, PPO, GRPO, etc.), In principle, off-policy RL algorithms can use any data, regardless of when and how it was collected. Q-learning is the most widely used off-policy RL algorithm.
But you do need to understand the mathematical concepts behind the algorithms and analyses youll use daily. Part 2: Linear Algebra Every machine learning algorithm youll use relies on linear algebra. Understanding it transforms these algorithms from mysterious black boxes into tools you can use with confidence.
SIMD-friendly algorithms for substring searching Author: Wojciech MuÅa Added on: 2016-11-28 Updated on: 2018-02-14 (spelling), 2017-04-29 (ARMv8 results) Introduction Popular programming languages provide methods or functions which locate a substring in a given string. and (2) based on a simple comparison, like the Karp-Rabin algorithm.
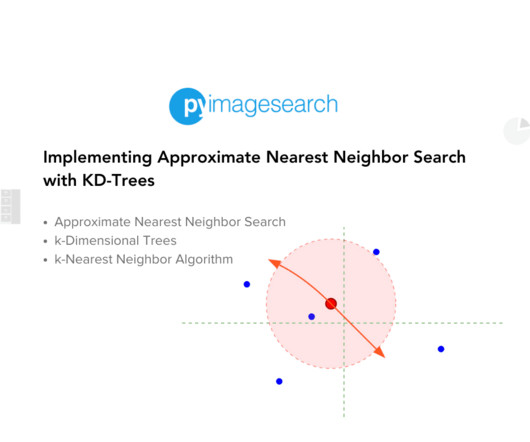
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications.
Instruct , an open agentic code model, to enhance software development efficiency and accuracy by integrating advanced algorithms and a vast knowledge base. This model incorporates sophisticated algorithms and draws upon an extensive knowledge base, enabling it to manage intricate coding assignments with considerable skill.
Program 1 Insurance Claim Approval # Step 1: Import required libraries import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from xgboost import XGBClassifier from sklearn.metrics import accuracy_score, confusion_matrix import matplotlib.pyplot... The post ML Project – (..)
We design new differentially private algorithms for the problems of adversarial bandits and bandits with expert advice. For adversarial bandits, we give a simple and efficient conversion of any non-private bandit algorithms to private bandit algorithms. In particular, our algorithms…
Program 1 Diabetes Prediction Dataset import pandas as pd from sklearn.model_selection import train_test_split from xgboost import XGBClassifier from sklearn.metrics import accuracy_score from sklearn.preprocessing import LabelEncoder # Load data df = pd.read_csv("D://scikit_data/diabetes/diabetes_prediction_dataset.csv") # columns: Glucose,... (..)
Meta-learning can automate the discovery of novel algorithms, but is limited by first-order improvements and the human design of a suitable search space. The advance of AI could itself be automated. If done safely, that would accelerate AI development and allow us to reap its benefits much sooner.
This system implements novel ensemble learning techniques and dynamic algorithm selection methodologies that I developed, which have resulted in two patent applications. Madhura Raut: The trend that seems most noteworthy to me is the merging of sophisticated algorithmic methods with deployment realities.
Employers frequently assess candidates on their proficiency with Python’s core constructs, data manipulation, visualization, and algorithmic problem-solving. Python powers most data analytics workflows thanks to its readability, versatility, and rich ecosystem of libraries like Pandas, NumPy, Matplotlib, SciPy, and scikit-learn.
Google DeepMind today pulled the curtain back on AlphaEvolve, an artificial-intelligence agent that can invent brand-new computer algorithms then put them straight to work inside the companys vast computing empire. AlphaEvolve pairs Googles Gemini large language models with an evolutionary
To reduce delays, you may need to fine-tune your data pipeline, optimize processing algorithms, and leverage techniques like batching and caching for better responsiveness. Latency While streaming promises real-time processing, it can introduce latency, particularly with large or complex data streams.
Data structures play a critical role in organizing and manipulating data efficiently, serving as the foundation for algorithms and high-performing applications. Importance of data structures Data structures significantly impact algorithm efficiency and application performance.
By using intelligent algorithms, real-time data analysis, and even emotional cues, AI has emerged as the ultimate networking wingman. AI-driven personalization takes away the guesswork: Smart recommendations: Algorithms suggest connections based on mutual goals, skills, or industries. The answer might be artificial intelligence.
Despite these limitations, advancements in algorithms have propelled the capability of machines to recognize patterns and objects more accurately. It is crucial to have labeled datasets, which serve as training material for the algorithms. Once data is collected, training neural networks becomes the next step.
Alternatives to Rekognition people pathing One alternative to Amazon Rekognition people pathing combines the open source ML model YOLOv9 , which is used for object detection, and the open source ByteTrack algorithm, which is used for multi-object tracking.
torchft implements a few different algorithms for fault tolerance. These algorithms minimize communication overhead by synchronizing at specified intervals instead of every step like HSDP. We’re always keeping an eye out for new algorithms, such as our upcoming support for streaming DiLoCo.
Neural networks surround us, in the form of large language models, speech transcription systems, molecular discovery algorithms, robotics, and much more.
Introduction Mathematics forms the backbone of Artificial Intelligence , driving its algorithms and enabling systems to learn and adapt. Key Takeaways Mathematics is crucial for optimising AI algorithms and models. Mastering these areas is critical for AI professionals to design scalable and efficient AI solutions.
By Jayita Gulati on July 16, 2025 in Machine Learning Image by Editor In data science and machine learning, raw data is rarely suitable for direct consumption by algorithms. Feature engineering can impact model performance, sometimes even more than the choice of algorithm itself.
In this article, we will talk about RLHF — a fundamental algorithm implemented at the core of ChatGPT that surpasses the limits of human annotations for LLMs. Loss function used in the RLHF algorithm. Instead, they designed an incredible technique that allowed a breakthrough.
Advanced algorithms analyze customer preferences, geographic conditions, and material requirements to generate highly customizable designs. Real-time monitoring and machine learning algorithms improve production efficiency by identifying bottlenecks and suggesting improvements.
Photo by ThisisEngineering on Unsplash Gradient Descent is a fundamental optimization algorithm used in machine learning to minimize a function by iteratively moving in the direction of steepest descent. It’s particularly useful in training models with large datasets, as it efficiently finds the minimum of a cost function.
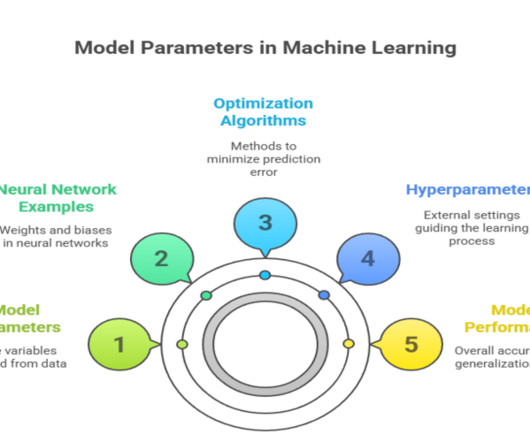
Optimization algorithms like Adam and SGD iteratively update parameters during training. Examples of Model Parameters in Common Algorithms Model parameters are the internal variables that a machine learning mode l learns from data to make predictions. These parameters define how the model transforms input data into predictions.
Algorithms and logic building: Apply algorithmic thinking with the Luhn algorithm , bisection method , shortest path , recursion ( Tower of Hanoi ), and tree traversal. Computer science foundations: Algorithms, data structures, and how they apply in Python. #
To address this challenge, we introduce a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels, emph{without external supervision}. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision.
In contrast, computers, especially with algorithms, can efficiently create vast sets of random numbers. These external variables produce genuine randomness that does not rely on existing algorithms. While convenient and fast, the numbers produced can eventually repeat, making them less suitable for cryptographic applications.
Data Analysis Algorithms are applied to detect patterns and trends. Ethical concerns and algorithm bias Algorithms may reflect biases present in their training data, sometimes leading to uneven performance across populations. This creates a detailed dataset that forms the foundation for analysis.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. CatBoost is part of the gradient boosting family, alongside well-known algorithms like XGBoost and LightGBM.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content