This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the realm of artificial intelligence, the emergence of vector databases is changing how we manage and retrieve unstructured data. By allowing for semantic similarity searches, vector databases are enhancing applications across various domains, from personalized content recommendations to advanced natural language processing.
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. Impqct of AI on healthcare The healthcare landscape is brimming with data such as demographics, medical records, lab results, imaging scans, – the list goes on.
As an AI-centered platform, it creates direct pathways from customer feedback to product development, helping over 1,000 companies accelerate growth with accurate search, fast analytics, and customizable workflows. Anshu Avinash, Head of AI and Search at DevRev.
It works by analyzing the visual content to find similar images in its database. In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space.
The growing need for cost-effective AI models The landscape of generative AI is rapidly evolving. Although GPT-4o has gained traction in the AI community, enterprises are showing increased interest in Amazon Nova due to its lower latency and cost-effectiveness. Each provisioned node was r7g.4xlarge,
Each category necessitates specialized generative AI-powered tools to generate insights. The available data sources are: Stock Prices Database Contains historical stock price data for publicly traded companies. Analyst Notes Database Knowledge base containing reports from Analysts on their interpretation and analyis of economic events.
Generative AI has revolutionized customer interactions across industries by offering personalized, intuitive experiences powered by unprecedented access to information. For businesses, RAG offers a powerful way to use internal knowledge by connecting company documentation to a generative AI model.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Caching is performed on Amazon CloudFront for certain topics to ease the database load.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access.
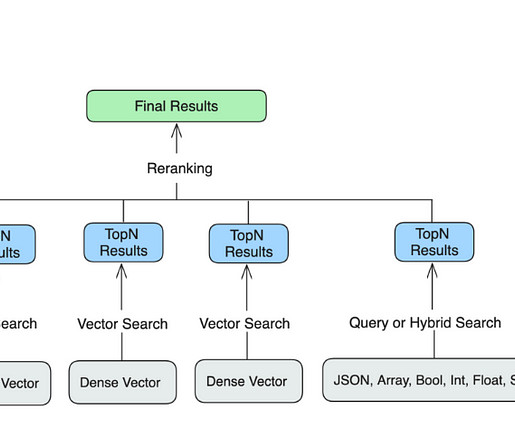
These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems. OpenSearch Service then uses the vectors to find the k-nearestneighbors (KNN) to the vectorized search term and image to retrieve the relevant listings.
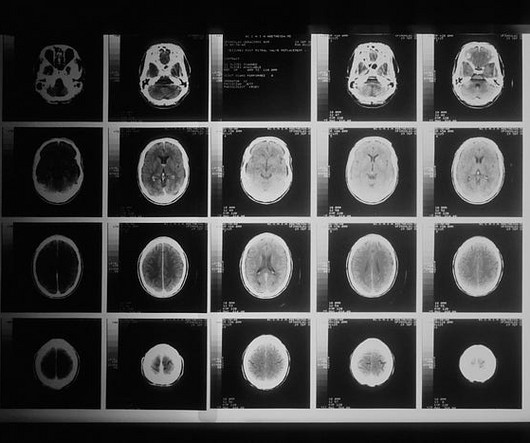
Last Updated on May 13, 2024 by Editorial Team Author(s): Cristian Rodríguez Originally published on Towards AI. 4] Dataset The dataset comes from Kaggle [5], which contains a database of 3206 brain MRI images. The three weak learner models used for this implementation were k-nearestneighbors, decision trees, and naive Bayes.
Last Updated on February 20, 2025 by Editorial Team Author(s): Afaque Umer Originally published on Towards AI. Vector Databases 101: A Beginners Guide to Vector Search and Indexing Photo by Google DeepMind on Unsplash Introduction Alright, folks! Traditional databases? 😎🔥 Section 1: What is a Vector Database?
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. Archana is an aspiring member of the AI/ML technical field community at AWS.
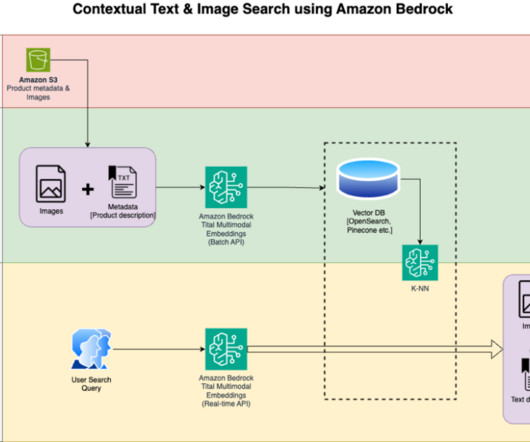
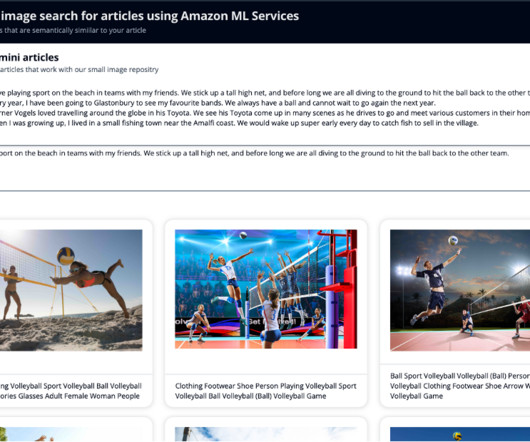
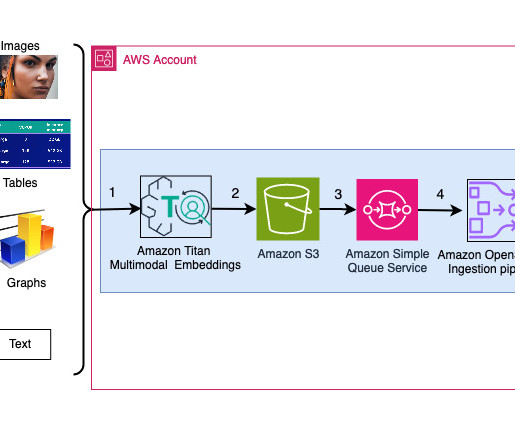
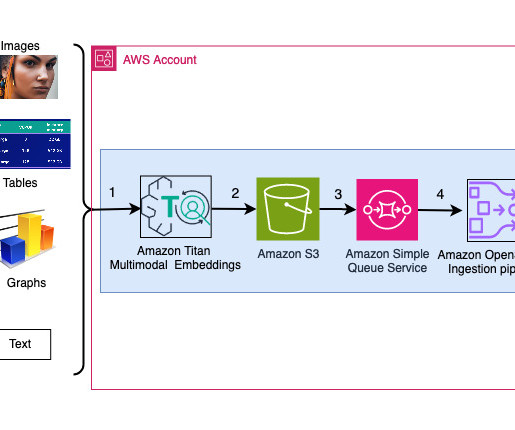
Search engines and recommendation systems powered by generative AI can improve the product search experience exponentially by understanding natural language queries and returning more accurate results. With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generative AI, using historical data, to drive efficiency and effectiveness.
You then use Exact k-NN with scoring script so that you can search by two fields: celebrity names and the vector that captured the semantic information of the article. You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space.
The AWS Generative AI Innovation Center (GenAIIC) is a team of AWS science and strategy experts who have deep knowledge of generative AI. They help AWS customers jumpstart their generative AI journey by building proofs of concept that use generative AI to bring business value. doc,pdf, or.txt).
DeepSeek-R1 is a powerful and cost-effective AI model that excels at complex reasoning tasks. This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. This example provides a solution for enterprises looking to enhance their AI capabilities.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
AI now plays a pivotal role in the development and evolution of the automotive sector, in which Applus+ IDIADA operates. In this post, we showcase the research process undertaken to develop a classifier for human interactions in this AI-based environment using Amazon Bedrock.
Last Updated on April 24, 2025 by Editorial Team Author(s): James Luan Originally published on Towards AI. The general perception is that you can simply feed data into an embedding model to generate vector embeddings and then transfer these vectors into your vector database to retrieve the desired results.
With the advent of generative AI, today’s foundation models (FMs), such as the large language models (LLMs) Claude 2 and Llama 2, can perform a range of generative tasks such as question answering, summarization, and content creation on text data. Setting k=1 retrieves the most relevant slide to the user question.
That’s why diversifying enterprise AI and ML usage can prove invaluable to maintaining a competitive edge. ML is a computer science, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. What is machine learning?
Conversational AI has come a long way in recent years thanks to the rapid developments in generative AI, especially the performance improvements of large language models (LLMs) introduced by training techniques such as instruction fine-tuning and reinforcement learning from human feedback.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean.
Amazon Bedrock is a fully managed service that provides access to a range of high-performing foundation models from leading AI companies through a single API. It offers the capabilities needed to build generative AI applications with security, privacy, and responsible AI. Victor Wang is a Sr.
For example: Traditional Search: "A superhero film with an AI-powered villain" Doesnt match Avengers: Age of Ultron unless those exact words appear in the dataset. Semantic Search: "A superhero film with an AI-powered villain" Correctly retrieves Avengers: Age of Ultron , even if the description is phrased differently.
In this series, we will set up AWS OpenSearch , which will serve as a vector database for a semantic search application that well develop step by step. Hybrid Search: Combines BM25 (Best Match 25) keyword search with vector embeddings, balancing traditional and AI-powered search for precise, relevant results.
In this post, we present a solution to handle OOC situations through knowledge graph-based embedding search using the k-nearestneighbor (kNN) search capabilities of OpenSearch Service. Solution overview. The key AWS services used to implement this solution are OpenSearch Service, SageMaker, Lambda, and Amazon S3.
Generative AI offers new possibilities to address this challenge and can be used by content teams and influencers to enhance their creativity and engagement while maintaining brand consistency. find_similar_items performs semantic search using the k-nearestneighbors (kNN) algorithm on the input image prompt.
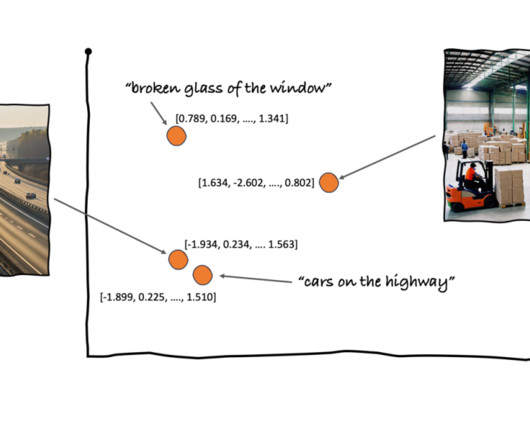
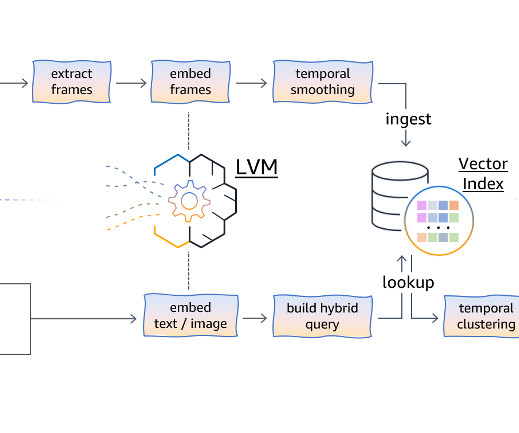
Furthermore, we demonstrate the end-to-end functionality of this approach by using both asynchronous and real-time hosting options on Amazon SageMaker AI to perform video, image, and text processing using publicly available LVMs on the Hugging Face Model Hub. The retrieved frame embeddings undergo temporal clustering.
K-NearestNeighbor Regression Neural Network (KNN) The k-nearestneighbor (k-NN) algorithm is one of the most popular non-parametric approaches used for classification, and it has been extended to regression. Decision Trees ML-based decision trees are used to classify items (products) in the database.
He presented “Building Machine Learning Systems for the Era of Data-Centric AI” at Snorkel AI’s The Future of Data-Centric AI event in 2022. This talk was followed by an audience Q&A conducted by Snorkel AI’s Priyal Aggarwal. Ce Zhang is an associate professor in Computer Science at ETH Zürich.
He presented “Building Machine Learning Systems for the Era of Data-Centric AI” at Snorkel AI’s The Future of Data-Centric AI event in 2022. This talk was followed by an audience Q&A conducted by Snorkel AI’s Priyal Aggarwal. Ce Zhang is an associate professor in Computer Science at ETH Zürich.
Basics of Machine Learning Machine Learning is a subset of Artificial Intelligence (AI) that allows systems to learn from data, improve from experience, and make predictions or decisions without being explicitly programmed. This data can come from databases, APIs, or public datasets. Random Forests).
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
HNSW is one of the most straightforward approaches to building a graph for nearest neighbour search, but it’s the best indexing scheme in terms of memory utilisation. Adding vectors to the index (xb are database vectors that are to be indexed). D, I = index.search(xq, k) #Source: [link] Check this out to learn more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content