This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Josep Ferrer , KDnuggets AI Content Specialist on July 15, 2025 in Data Science Image by Author Delivering the right data at the right time is a primary need for any organization in the data-driven society. But lets be honest: creating a reliable, scalable, and maintainable datapipeline is not an easy task.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Every data scientist has been there: downsampling a dataset because it won’t fit into memory or hacking together a way to let a business user interact with a machine learning model. Machine Learning in your Spreadsheets BQML training and prediction from a Google Sheet Many data conversations start and end in a spreadsheet.
At its core, vibe coding means expressing your intent in natural language and letting AI coding assistants translate that intent into working code. Vibe coding is a new paradigm in software development where you use natural language programming to instruct AI coding assistants to generate, modify, and even debug code.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Fun Generative AI Projects for Absolute Beginners New to generative AI?
However, standalone LLMs have key limitations such as hallucinations, outdated knowledge, and no access to proprietary data. Retrieval Augmented Generation (RAG) addresses these gaps by combining semantic search with generative AI , enabling models to retrieve relevant information from enterprise knowledge bases before responding.
Whether you’re visualizing climate data or plotting sales trends, the goal is clarity. The key is to start simple, iterate often, and don’t fear the documentation. Remember, even experts Google “how to add a second y-axis” sometimes.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
Document Everything : Keep clear and versioned documentation of how each feature is created, transformed, and validated. Use Automation : Use tools like feature stores, pipelines, and automated feature selection to maintain consistency and reduce manual errors.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
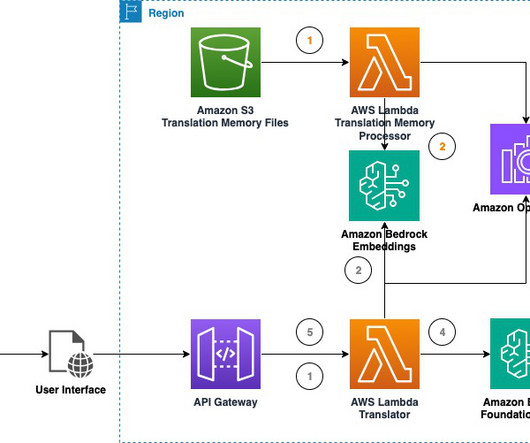
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE.
The landscape of enterprise application development is undergoing a seismic shift with the advent of generative AI. This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 10 Free Online Courses to Master Python in 2025 How can you master Python for free?
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. This post is cowritten with Isaac Cameron and Alex Gnibus from Tecton.
It is critical for AI models to capture not only the context, but also the cultural specificities to produce a more natural sounding translation. The solution offers two TM retrieval modes for users to choose from: vector and document search. For this post, we use a document store. Choose With Document Store.
Generative AI applications are gaining widespread adoption across various industries, including regulated industries such as financial services and healthcare. To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications.
This challenge led Swisscom , Switzerland’s leading telecommunications provider, to explore how AI can transform their network operations. This solution combines generative AI capabilities with a sophisticated data processing pipeline to help engineers quickly access and analyze network data.
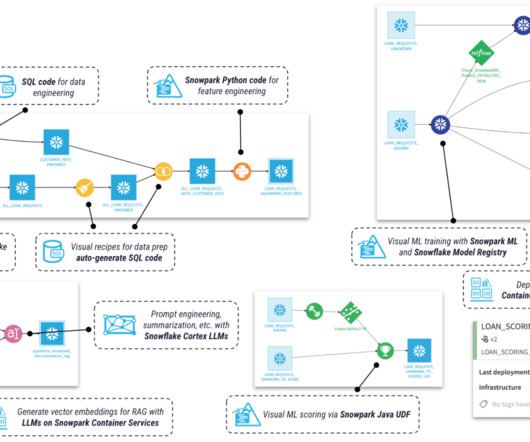
It must integrate seamlessly across data technologies in the stack to execute various workflows—all while maintaining a strong focus on performance and governance. Two key technologies that have become foundational for this type of architecture are the Snowflake AIData Cloud and Dataiku. Let’s say your company makes cars.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Today, we’ll explore why Amazon’s cloud-based machine learning services could be your perfect starting point for building AI-powered applications.
This post introduces HCLTechs AutoWise Companion, a transformative generative AI solution designed to enhance customers vehicle purchasing journey. Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience.
In Part 1 of this series, we explored how Amazon’s Worldwide Returns & ReCommerce (WWRR) organization built the Returns & ReCommerce Data Assist (RRDA)—a generative AI solution that transforms natural language questions into validated SQL queries using Amazon Bedrock Agents.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
VB Transform brings together the people building real enterprise AI strategy. Learn more Walmart isn’t buying enterprise AI solutions, they’re creating them in their AI foundry. Learn more Walmart isn’t buying enterprise AI solutions, they’re creating them in their AI foundry.
Amazon Bedrock Agents helps you accelerate generative AI application development by orchestrating multistep tasks. With the power of AI automation, you can boost productivity and reduce cost. The generative AI–based application builder assistant from this post will help you accomplish tasks through all three tiers.
Well start by breaking down what a Matillion pipeline is, then dive into some best practices to keep your workflows clean, scalable, and easy to maintain. As a bonus, well check out Matillions AI Copilot and see how AI can help take workflow design to the next level. Data tables used and their role in the workflow.
Clean, interoperable datapipelines : Having region-specific analytics, differentiated content such as marketing materials translated into various languages, and numerous CRM instances all add up to global operations. Consistent execution requires defined change management workflows and clearly delineated onboarding documentation.
It integrates diverse, high-quality content from 22 sources, enabling robust AI research and development. Its accessibility and scalability make it essential for applications like text generation, summarisation, and domain-specific AI solutions. Its diverse content includes academic papers, web data, books, and code.
Key Takeaways Trusted data is critical for AI success. Data integration ensures your AI initiatives are fueled by complete, relevant, and real-time enterprise data, minimizing errors and unreliable outcomes that could harm your business. Data integration solves key business challenges.
Use Cases in ML Workflows Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines. It also simplifies managing configuration dependencies in Deep Learning projects and large-scale datapipelines.
Whether youre new to AI development or an experienced practitioner, this post provides step-by-step guidance and code examples to help you build more reliable AI applications. The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs.
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
As AI technologies continue to evolve, understanding the functionalities and development stages of LLM applications is essential for both new and seasoned developers. Data collection and preparation Quality data is paramount in training an effective LLM. KLU.ai: Offers no-code solutions for smooth data source integration.
As AI and data engineering continue to evolve at an unprecedented pace, the challenge isnt just building advanced modelsits integrating them efficiently, securely, and at scale. This session explores open-source tools and techniques for transforming unstructured documents into structured formats like JSON and Markdown.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls. I am interested in contract work if it is the right fit.
Generative AI has rapidly evolved from a novelty to a powerful driver of innovation. From summarizing complex legal documents to powering advanced chat-based assistants, AI capabilities are expanding at an increasing pace. Gartner predicts that 30% of generative AI projects will be abandoned in 2025.
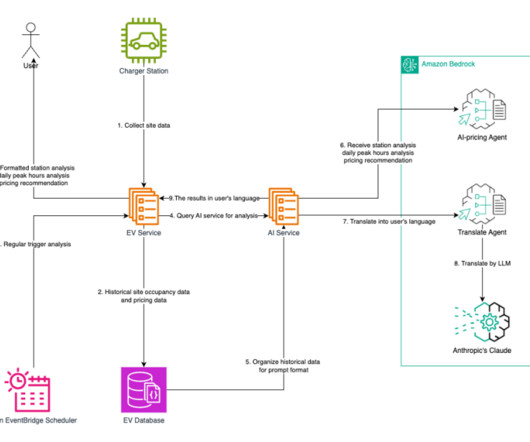
To solve this, Noodoe has integrated large language models (LLMs) through Amazon Bedrock and Amazon Bedrock Agents to deliver intelligent automation, real-time data access, and multilingual support. In this post, we explore how Noodoe uses AI and Amazon Bedrock to optimize EV charging operations.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
Most AI teams focus on the wrong things. Heres a common scene from my consulting work: AI TEAM Heres our agent architectureweve got RAG here, a router there, and were using this new framework for ME [Holding up my hand to pause the enthusiastic tech lead] Can you show me how youre measuring if any of this actually works?
Give us feedback → Edit this page Scroll to top Blog Why Go is a good fit for agents Why Go is a good fit for agents Since you’re here, you might be interested in checking out Hatchet — the platform for running background tasks, datapipelines and AI agents at scale. They often involve input from a user (or another agent!)
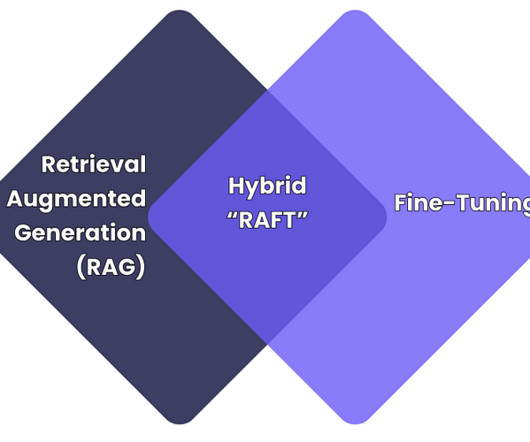
Originally published on Towards AI. RAFT vs Fine-Tuning Image created by author As the use of large language models (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g., Solution: Use overlapping chunks (e.g.,
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. Lets look at how generative AI can help solve this problem.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content