
Governing the ML lifecycle at scale, Part 3: Setting up data governance at scale
NOVEMBER 22, 2024
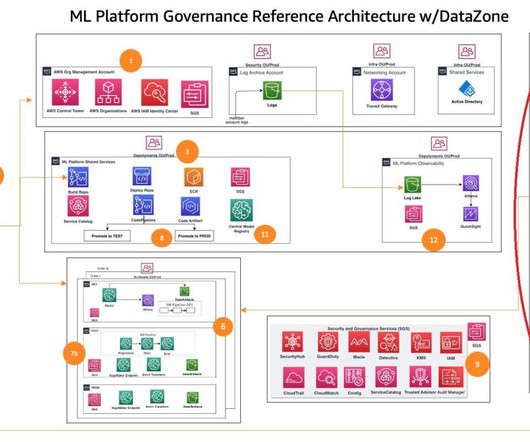
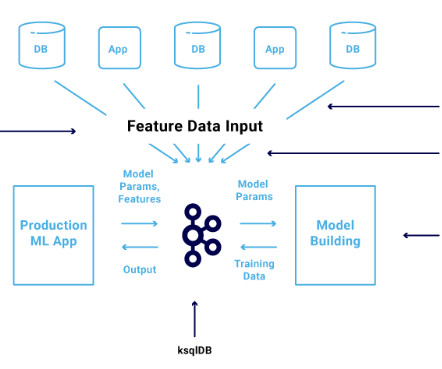
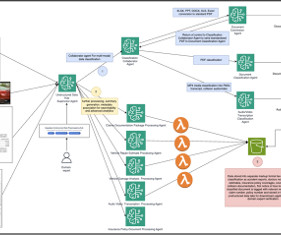
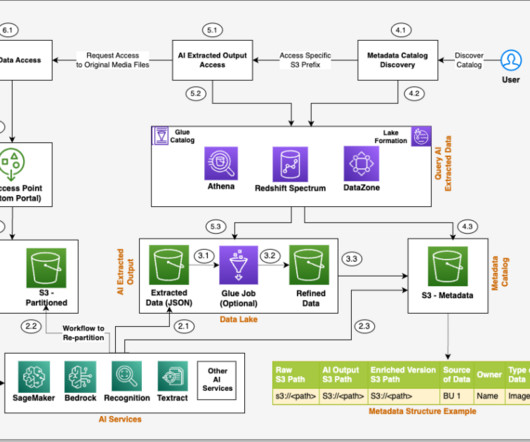
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.

































Let's personalize your content