This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
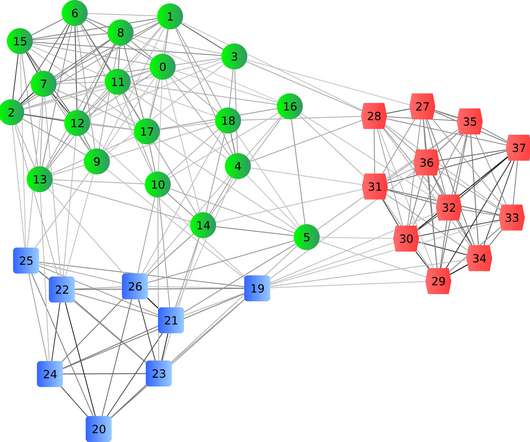
Explainable AI is no longer just an optional add-on when using ML algorithms for corporate decision making. The post Adding Explainability to Clustering appeared first on Analytics Vidhya. Introduction The ability to explain decisions is increasingly becoming important across businesses.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Fifth, we’ll showcase various generative AI use cases across industries.
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters. Create a new training plan.
At the time, I knew little about AI or machine learning (ML). But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML. Panic set in as we realized we would be competing on stage in front of thousands of people while knowing little about ML.
Ray has emerged as a powerful framework for distributed computing in AI and ML workloads, enabling researchers and practitioners to scale their applications from laptops to clusters with minimal code changes.
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. RELand consistently outperforms the benchmark models on all relevant metrics.
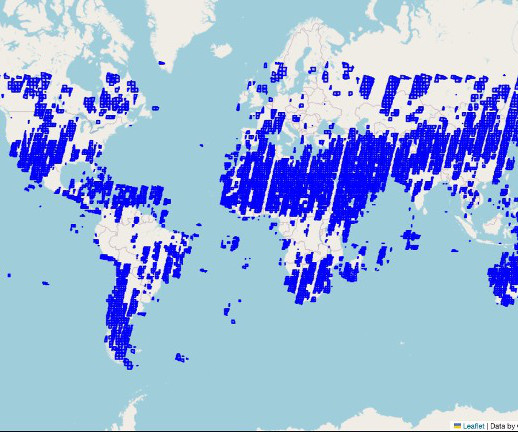
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. Larger clusters, more failures, smaller MTBF As cluster size increases, the entropy of the system increases, resulting in a lower MTBF. It implies that if a single instance fails, it stops the entire job.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. For this post we’ll use a provisioned Amazon Redshift cluster.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
Climate tech startups are at the forefront of building impactful solutions to the climate crisis, and theyre using generative AI to build as quickly as possible. Trends among climate tech startups building with generative AI Climate tech startups adoption of generative AI is evolving rapidly.
Hammerspace, the company orchestrating the Next Data Cycle, unveiled the high-performance NAS architecture needed to address the requirements of broad-based enterprise AI, machine learning and deep learning (AI/ML/DL) initiatives and the widespread rise of GPU computing both on-premises and in the cloud.
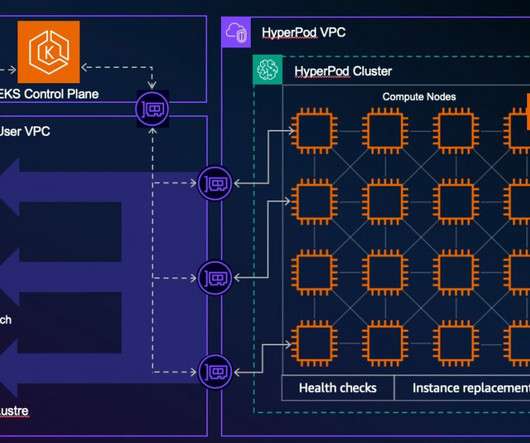
Solution overview The steps to implement the solution are as follows: Create the EKS cluster. Create the EKS cluster If you don’t have an existing EKS cluster, you can create one using eksctl. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. These classified transactions then serve as critical inputs for downstream credit risk AI models, enabling more accurate assessments of a businesss creditworthiness.
To reduce costs while continuing to use the power of AI , many companies have shifted to fine tuning LLMs on their domain-specific data using Parameter-Efficient Fine Tuning (PEFT). Manually managing such complexity can often be counter-productive and take away valuable resources from your businesses AI development.
The rise of generative AI has significantly increased the complexity of building, training, and deploying machine learning (ML) models. It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters.
Increasingly, organizations across industries are turning to generative AI foundation models (FMs) to enhance their applications. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. recipes=recipe-name.
In this post, we introduce an innovative solution for end-to-end model customization and deployment at the edge using Amazon SageMaker and Qualcomm AI Hub. After fine-tuning, we show you how to optimize the model with Qualcomm AI Hub so that it’s ready for deployment across edge devices powered by Snapdragon and Qualcomm platforms.
AI agents are rapidly becoming the next frontier in enterprise transformation, with 82% of organizations planning adoption within the next 3 years. According to a Capgemini survey of 1,100 executives at large enterprises, 10% of organizations already use AI agents, and more than half plan to use them in the next year.
This is why businesses are looking to leverage machine learning (ML). In this article, we will share some best practices for improving your analytics with ML. Top ML approaches to improve your analytics. Clustering. ?lustering They need a more comprehensive analytics strategy to achieve these business goals.
Thanks to machine learning (ML) and artificial intelligence (AI), it is possible to predict cellular responses and extract meaningful insights without the need for exhaustive laboratory experiments. They introduce PERTURBQA , a benchmark designed to align AI-driven perturbation models with real biological decision-making.
Other organizations are just discovering how to apply AI to accelerate experimentation time frames and find the best models to produce results. With a goal to help data science teams learn about the application of AI and ML, DataRobot shares helpful, educational blogs based on work with the world’s most strategic companies.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. Generative AI is reshaping businesses and unlocking new opportunities across various industries.
Last Updated on September 3, 2024 by Editorial Team Author(s): Surya Maddula Originally published on Towards AI. Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
The use of unsupervised learning methods on semi-structured data along with generative AI has been transformative in unlocking hidden insights. Amazon Bedrock is a fully managed service that provides access to high-performing foundation models (FMs) from leading AI startups and Amazon through a unified API.
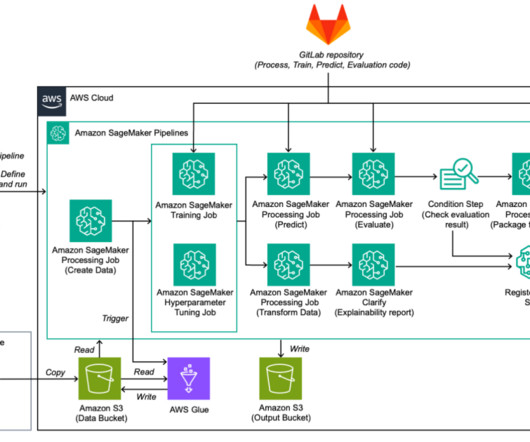
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Human oversight : Including human involvement in AI decision-making processes.
AIs transformative impact extends throughout the modern business landscape, with telecommunications emerging as a key area of innovation. Fastweb , one of Italys leading telecommunications operators, recognized the immense potential of AI technologies early on and began investing in this area in 2019.
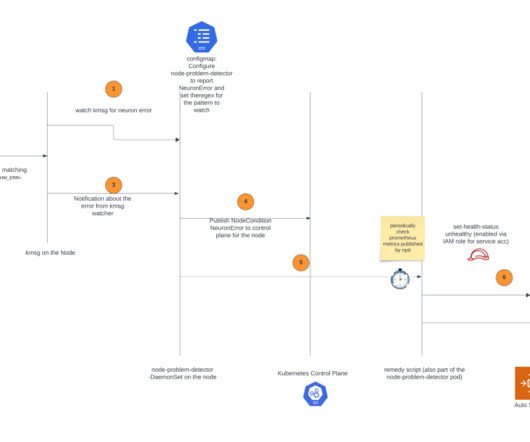
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. # install.sh
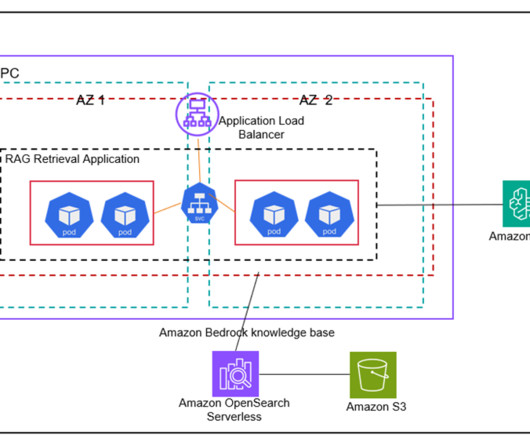
Generative artificial intelligence (AI) applications are commonly built using a technique called Retrieval Augmented Generation (RAG) that provides foundation models (FMs) access to additional data they didnt have during training.
At the Open Compute Project (OCP) Global Summit 2024, we’re showcasing our latest open AI hardware designs with the OCP community. These innovations include a new AI platform, cutting-edge open rack designs, and advanced network fabrics and components. Prior to Llama, our largest AI jobs ran on 128 NVIDIA A100 GPUs.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Companies across various scales and industries are using large language models (LLMs) to develop generative AI applications that provide innovative experiences for customers and employees. By offloading the management and maintenance of the training cluster to SageMaker, we reduce both training time and our total cost of ownership (TCO).
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
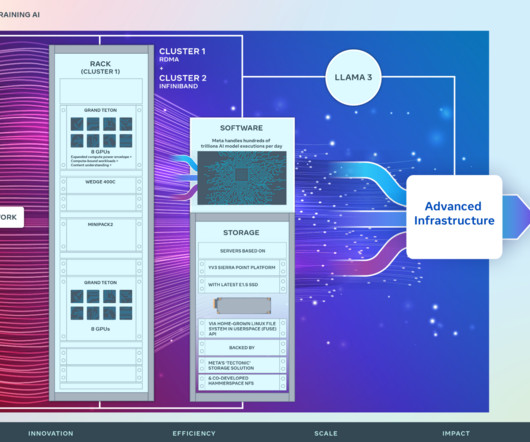
Meta is currently operating many data centers with GPU training clusters across the world. A year ago, however, as the industry reached a critical inflection point due to the rise of artificial intelligence (AI), we recognized that to lead in the generative AI space we’d need to transform our fleet.
You can use these techniques together to train complex models that are orders of magnitude faster and rapidly iterate and deploy innovative AI solutions that drive business value. After they’re initiated, SageMaker training jobs spin up the cluster, provisioning the specified number and type of compute instances.
TensorFlow provides high-level APIs, such as tf.distribute, to distribute training across multiple devices, machines, or clusters. PyTorch: PyTorch , developed by Facebook’s AI Research lab, is another popular distributed learning framework.
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
The report The economic potential of generative AI: The next productivity frontier , published by McKinsey & Company, estimates that generative AI could add an equivalent of $2.6 The potential for such large business value is galvanizing tens of thousands of enterprises to build their generative AI applications in AWS.
As we gather for NVIDIA GTC, organizations of all sizes are at a pivotal moment in their AI journey. The question is no longer whether to adopt generative AI, but how to move from promising pilots to production-ready systems that deliver real business value.
Author(s): Alessandro Amenta Originally published on Towards AI. Image generated with DALL-E 3 In the fast-paced world of Machine Learning (ML) research, keeping up with the latest findings is crucial and exciting, but let’s be honest — it’s also a challenge. What’s the next big thing in ML?
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extract high throughput and reliability for various AI workloads. We use this cluster design for Llama 3 training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content